

本文来自faceswap论坛的翻译,并进行了稍作修改和补充说明,后续会继续优化!!
在尝试上述任何操作之前,请确保您已阅读、理解并完成安装说明:
训练Faceswap之前,我们需要了解一下Extraction的工作流程,人脸数据的提取,人脸数据的优化,对齐文件的优化等:

如果你只想简单的训练一下faceswap,不做过多的探讨点击这里:

如果你想了解详细的转换指南过程,点击这里:

1. 简介
很多人刚开始换脸的时候会不知所措,而且会犯很多错误。错误是好的,这是我们学习的方式,但有时在深入学习之前对相关过程有一点了解会有所帮助。
在这篇文章中,我将详细介绍我们如何训练模型,有几种models可供选择,我不会把所有内容都讲完,但希望这些内容能够帮助您做出明智的决定。如果你还没有为训练生成你的人脸数据集,那么现在就停止阅读这篇文章,并前往提取指南生成它们。
这本指南中有相当多的背景知识,我建议你熟悉这一切。机器学习是一个复杂的概念,但我试图把它分解成尽可能简单的理解。对神经网络的工作原理有一个基本的了解,以及从看到的数据类型中受益,将大大提高您成功实现swap的可能性。
在本指南中,我将使用GUI,但是对cli(命令行)而言是完全相同的(GUI中出现的所有选项都可以在cli中使用)。
2. 什么是Training?
2.1 综述
从高水平上分析,训练是教我们的神经网络(NN)如何去重建一张人脸,大多数模型主要由两部分组成:
Encoder(编码器)- 它的工作是将一堆人脸作为输入,并将它们“encoding”成一个“vector”的表示形式。需要注意的是,它并不是在学习你输入给它的每一张人脸的精确表示,而是试图创建一种算法,可以在以后尽可能通过接近输入图像,来重建人脸。Decoder(解码器)- 它的任务是将编码器(Encoder)创建的向量转换成人脸,尽可能与输入图像匹配。
有些模型的构造略有不同,但基本前提是相同的。
神经网络需要知道它对人脸进行编码和解码的效果如何,它使用两种主要参数来实现这一点:
Loss(损失)- 对于每一批输入到模型中的人脸,神经网络将查看它试图通过当前的编码和解码算法重建的人脸,并将其与输入的实际人脸进行比较。根据它认为自己做得有多好,它将给自己一个分数(损失值),并相应地更新权重。Weights(权重)- 一旦模型评估了人脸重建的效果,它就会更新权重,这些权重将输入到编码器/解码器算法中。如果它在一个方向调整了权重,但感觉重建的效果比以前差,那么它就知道权重在向错误的方向移动,所以它会将权重向相反的方向调整。如果它感觉自己有了进步,那么它就会知道继续朝着它前进的方向调整权重。
然后,该模型会重复这个动作很多很多次,不断更新基于损失值的权重,理论上会随着时间的推移而改进,直到你觉得它已经学会了有效地重建一张人脸,或者损失值停止下降。
现在我们已经了解了神经网络的基本功能以及它是如何学习创建人脸的,如何应用于人脸交换?你可能已经注意到,在上述模型中,这个神经网络学会了如何获取一个人的大量人脸,然后重建这些人脸。这不是我们想要的……,我们想要用大量的人脸来重建别人的脸,为了实现这一点,我们的NN做了以下几件事:
Shared Encoder(共享编码器) – 当我们训练模型时,我们给它输入两组人脸。A集合(我们想要替换的原始人脸)和B集合(我们想要放到场景中的交换人脸),实现这一点的第一步是为A和B集合共享编码器。通过这种方式,我们的编码器学习一个算法,为2个不同的人脸,这是极其重要的,因为我们最终将告诉我们的神经网络,把一张人脸的编码,解码到另一张人脸。因此,编码器需要看到,并学习交换所需的两组人脸。Switched Decoders(切换解码器) – 在训练模型时,我们训练了 2 个解码器。 解码器 A 使用编码向量并尝试重新创建人脸 A,解码器 B 使用编码向量并尝试重新创建人脸 B。当最终交换人脸时,我们切换解码器,因此我们提供模型的人脸 A是通过解码器 B得到的。由于编码器已经在两组人脸上进行了训练,因此模型将对 A 的输入人脸进行编码,然后尝试从解码器 B 中重建它,从而导致我们的模型输出交换的人脸。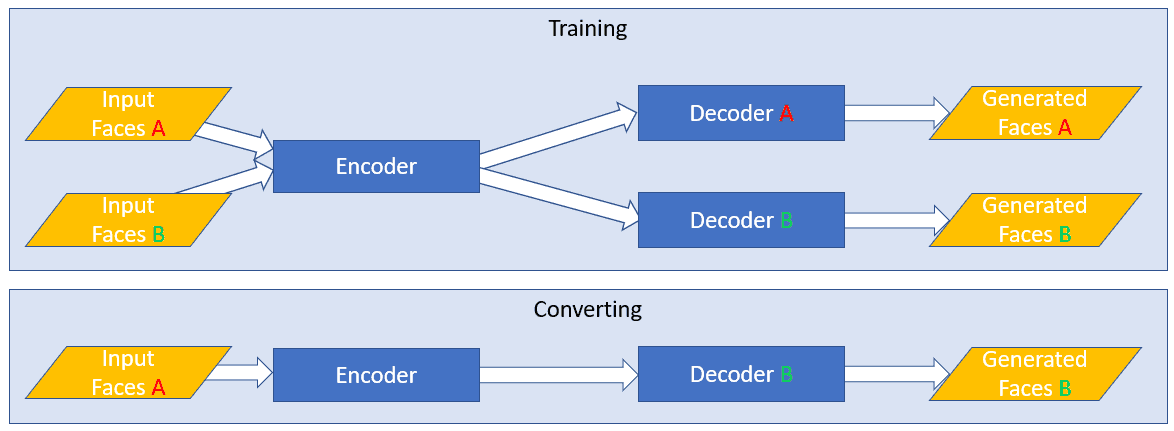
2.2 术语
在使用 Faceswap 时,您会看到一些常见的机器学习术语。 为了让我们理解起来更简单,这里显示了术语表:
Batch – Batch是同时通过神经网络输入的一组人脸。Batch Size – Batch Size是指同时通过神经网络输入的batch的大小。Batch Size为64的图像意味着64张人脸同时通过神经网络输入,然后计算这批图像的损失和权值更新。更大的Batch Size将训练得更快,有更高的泛化能力。较小的Batch Size将训练得更慢,能更好地区分人脸之间的差异。在训练的各个阶段调整Batch Size会有所帮助。Epoch – 例如:如果你有一个文件夹有5000个人脸,1 个 epoch是模型已经训练了所有5000个人脸。2个epoch是模型已经训练了所有5000个人脸两次,以此类推。就faceswap而言,Epoch实际上并不是一个有用的衡量标准。因为一个模型是在两个数据集(A人脸和B人脸)上训练的,除非这些数据集的大小完全相同(非常不可能),否则不可能计算一个Epoch,因为每一人脸的数据都不一样。Example – 就 Faceswap 而言,一个example是“Face”的另一个名称。它基本上是通过神经网络传递的一张人脸,如果模型看到了10个examples,那么它就看到了10张人脸。EG/s – 这是神经网络每秒看到的样本数量,或者就Faceswap而言,就是模型每秒处理的人脸数量。Iteration – Iteration是通过神经网络处理的一个完整batch。 因此,batch size为 64 的 10 次Iteration意味着模型已经看到了 640 (64 * 10) 张人脸。NN – 是神经网络的缩写。3. Training Data(训练数据)
数据质量对模型的重要性再怎么强调也不过分。一个较小的模型可以在良好的数据下表现得很好,同样,没有一个模型会在糟糕的数据下表现得很好。在你的模型的每一边至少应该有500个不同的图像,但是在一定程度上,数据越多,变化越多,越好……。要使用的合理数量的图像在 1,000 到 10,000 之间,添加更多的图像实际上会损害训练。
太多类似的图片对你的模型没有帮助,你需要尽可能多的不同角度、表情和光照条件。这是一个常见的误解,即模型是为特定的场景训练的,这是“记忆”,而不是你想要达到的目的。你要试着训练模型去理解一张在所有情况下,所有角度,所有表情的人脸,然后把它换成另一张在所有情况下,所有角度,所有表情的人脸。因此,您需要从尽可能多的不同来源为A和B数据集构建一个训练集。
不同的角度是非常重要的,神经网络只能学习它看到的东西。如果95%的脸是直视着相机的,5%是侧着的,那么模型将需要很长时间来学习如何创建侧着的脸。它可能根本无法创造它们,因为它很少看到侧面的脸。理想情况下,你希望脸部角度、表情和光照条件尽可能均匀分布。
同样,在人脸A和人脸B之间拥有尽可能多的匹配角度、表达式、光照条件也是很重要的。如果你有大量的配置文件图像为人脸A,而没有配置文件图像为人脸B,那么模型将永远不能在配置文件中执行交换,因为解码器B将缺乏创建配置文件镜头所需的信息。
训练数据的质量一般不应模糊,而应高质量(清晰和详细)。然而,在训练集中有一些模糊或者部分模糊的图像是好的。在最终的交换中,一些人脸将会模糊/低分辨率/不清楚,所以对神经网络来说,看到这些类型的图像也是很重要的,这样它就可以做一个准确可靠的再现。
更多关于创建训练集的详细信息可以在提取指南中找到。
4. Choosing a model(选择一个模型)
Faceswap中有几种可用的模型,随着时间的推移将添加更多模型。每一个的质量都可能是非常主观的,因此这将提供每个(当前)可用的简要概述。最终,最适合您的模型可以归结为许多因素,因此没有明确的答案。每种方法都有利有弊,但是如上所述,最重要的一个因素是数据的质量,没有模型可以解决数据问题。
您将看到下面提到的输入和输出大小(例如 64px输入,64px输出)。这是输入模型的人脸图像的大小(输入)和模型生成的人脸的大小(输出),输入模型的所有人脸都是方形的,所以 64px 的图像将是 64 像素宽、64 像素高。一种常见的误解是,更高分辨率的输入会得到更好的交换,虽然它可以提供帮助,但情况并非总是如此。神经网络正在学习如何将人脸编码为算法,然后再次解码该算法。它只需要足够的数据就可以创建一个可靠的算法,输入分辨率和输出质量没有直接联系。
值得注意的是,模型越大,训练所需的时间就越长。使用Nvidia GTX 1080进行训练需要12-48小时,Villain可以在相同的硬件上工作一周。通常认为,一个具有两倍输入大小的模型将花费两倍的时间,这是不正确的,这至少需要4倍的时间,甚至可能更久。这是因为64px的图像有4,096个像素。然而,128像素的图像有16,384像素,这是原来的4倍,除此之外,还需要对模型进行缩放,以处理增加的数据量,训练时间可以很快累积起来。

5. Model configuration settings(模型配置设置)
好了,你已经选择了你的模型,让我们来训练!等一下,我钦佩你的热心,但你可能想先设置一些模型的特定选项。为此,我将使用GUI,但配置文件(如果使用命令行)可以在faceswap文件夹中的faceswap/config/train.ini位置找到。
我不会详细介绍每个模型的选项,因为这些选项各不相同,并且为新模型保持更新会很困难,但我将概述一些更常见的选项,我们将更多地关注适用于所有模型的全局选项。所有选项都有工具提示,因此将鼠标悬停在选项上以获取有关其功能的更多信息。
要访问模型配置面板,请转至 Settings > Configure Settings …或选择Train Settings的快捷方式以直接转到正确位置:
5.1 Global Settings(全局设置)
这些选项适用于所有模型,并被分为Global模型选项和Loss选项。
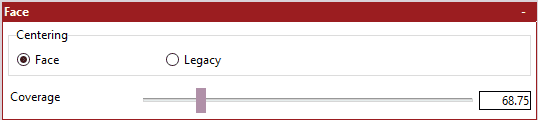
Global:可以通过选择“Train”节点访问全局选项。 此页面上的所有选项(Learning Rate、Epsilon Exponent、Convert Batchsize、Allow Growth和 NaN Protection除外)仅在创建新模型时生效。 一旦您开始训练模型,此处选择的设置将“locked”到该模型,并且在您恢复训练时会重新加载,无论此处配置的是什么。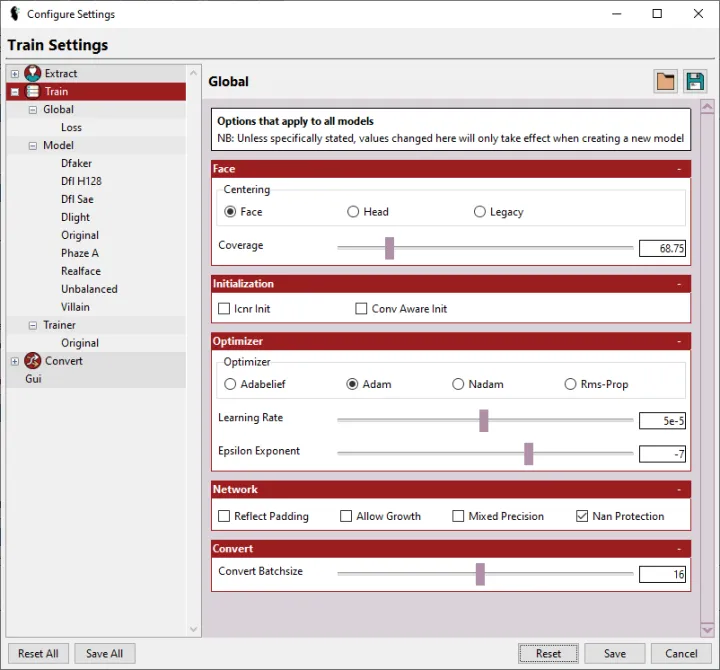



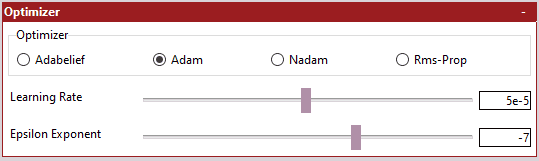

5.2 Loss Settings(损失设置)
用于控制要使用的损失类型和数量的选项。通过展开“Global”节点并选择“Loss”来访问这些选项:
Loss Settings就像全局设置一样,一旦您开始训练,这些选项中的大多数都会“locked”到模型。这是除了Eye Multipliers和Mouth Multipliers以及 L2 Reg Term ,可以针对现有模型进行调整。
Loss:使用的损失函数。有多种不同的方法来计算损失,或者让神经网络辨别它在训练模型方面的表现。我不会详细介绍每个可用的功能,因为这将是一个有点冗长的过程,而且互联网上有大量关于这些功能的信息。Loss Function – 最常用的损失方法是 MAE(平均绝对误差)和 SSIM(结构相似性),我个人的偏好是使用 SSIM。Mask Loss Function – 如果您打算学习mask,请使用该方法。默认的均方误差 (MSE) 没问题。L2 Reg Term – 如果使用结构相似性损失(例如 SSIM),则应应用 L2 正则化。此选项仅影响兼容损失,除非您知道自己在做什么,否则应保留默认设置。Eye Multiplier – 赋予眼部区域的“weight”量。只有在启用了“Penalized Loss”的情况下才能使用此选项。值为 2 意味着眼睛的重要性是人脸其余部分的两倍,这有助于学习精细的细节,但将其设置得太高会导致像素化。由于可以针对现有模型调整此设置,因此通常可以训练出问题。Mouth Multiplier – 给予嘴部区域的“weight”量。只有在启用了“Penalized Loss”的情况下才能使用此选项。值为 2 意味着嘴巴的重要性是人脸其余部分的两倍。这有助于学习精细的细节,但将其设置得太高会导致像素化。由于可以针对现有模型调整此设置,因此通常可以训练出问题。Penalized Mask Loss – 此选项决定了位于人脸区域之外的图像区域的重要性,是否应低于位于人脸区域内的区域,此选项应始终启用。Mask:适用于带mask训练的选项。设置mask是指示图像的哪个区域重要的一种方式,在下面的例子中,红色区域被 “masked out”(即:它被认为是不重要的),而清晰区域被 “masked in”(它是人脸,所以是我们感兴趣的区域):训练mask有两个目的:它将训练集中在人脸区域,迫使模型对背景的重要性降低。这可以帮助模型更快地学习,同时还确保它不会占用学习不重要的背景细节的空间。学习到的mask可以在转换阶段使用。在当前的实现中,学习的mask是否比在转换时,使用标准mask提供任何好处是有争议的,但使用mask进行训练可确保您可以选择使用它。Mask Type – 用于训练的mask类型。要使用mask,您必须将所需的masks添加到生成训练集的原始对齐文件中,您可以使用mask工具添加/更新mask。有关每个mask的详细说明,请参阅[Guide] Extraction – A WorkflowMask Blur Kernel – 这会对mask的边缘,应用轻微的模糊。实际上,它去除了mask的硬边缘,并从人脸到背景逐渐混合,这可以帮助计算不佳的mask。是否要启用此功能以及要使用的值取决于您,默认值应该没问题,但您可以使用mask工具进行试验。Mask Threshold – 此选项不会影响基于对齐的masks(extended, components),因为它们是二进制的(即mask是“on”或“off”)。对于基于 NN 的masks,masks不是二进制的,并且具有不同级别的不透明度。在某些情况下,这可能会导致masks出现斑点,提高阈值会使masks部分接近透明、完全透明,而masks部分接近实心、完全实心。同样,这将因情况而异。Learn Mask – 如前所述,学习mask是否有任何好处是有争议的。启用此选项将使用更多 VRAM,因此我倾向于将其关闭,但如果您希望预测mask在转换中可用,那么您应该启用此选项。5.3 Model Settings(模型设置)
这些是特定于每个模型插件的设置。您可以通过单击“Model”节点来访问这些:
Model Settings如前所述,我不会详细介绍模型特定的设置,这些因插件而异。但是,我将介绍您可能在每个插件中看到的一些常见选项。与往常一样,每个选项都有一个工具提示,可以为您提供更多信息。
lowmem – 一些插件具有“lowmem”模式。这使您能够运行模型的精简版本,占用更少的 VRAM,但代价是保真度较差。input size – 一些插件允许您调整输入模型的输入大小。输入始终是方形的,因此这是输入模型的图像的宽度和高度的大小(以像素为单位)。不要相信更大的输入总是等于更好的质量,这并非总是如此,还有许多其他因素决定模型是否具有良好的质量。更高的输入尺寸需要成倍增加的 VRAM 来处理。output size – 一些插件允许您调整模型生成的图像的大小。输入大小和输出大小不必相同,因此某些模型包含升级器,返回比输入图像更大的输出图像。5.4 Trainer Settings(训练器设置)
配置设置页面中的部分用于Trainer或“Data Augmentation”选项。展开“Trainer”节点并选择“Original”:
神经网络需要看到很多很多不同的图像。为了更好地学习人脸,它对输入图像执行各种操作,这称为“数据增强”。如注释中所述,标准设置适用于 99% 的用例,因此只有在您知道它们会产生什么影响时才更改这些设置。
Evaluation – 评估训练状态的选项。Preview Images – 这是预览窗口中显示的交换人脸A和人脸B的人脸数量。Image Augmentation – 这些是对输入模型的人脸进行的操作。Zoom Amount – 人脸在输入神经网络之前,被放大或缩小的百分比。帮助模型处理错位。Rotation Range – 人脸在被送入神经网络之前,顺时针或逆时针旋转的百分比量。帮助模型处理错位。Shift Range – 人脸在被送入神经网络之前,向上/向下、向左/向右移动的百分比量。帮助模型处理错位。Flip Chance – 水平翻转人脸的机会。帮助创建更多角度供神经网络学习。Color Augmentation – 这些增强处理输入模型的人脸的颜色/对比度,使神经网络对颜色差异更加鲁棒:这是色彩增强在幕后所做的说明(您不会在预览/最终输出中看到它,它仅用于演示的目的):Color Lightness – 上下调整输入图像亮度的百分比,有助于应对不同的光照条件。Color AB – 在 Lab 颜色空间的 A/B 标度上调整颜色的百分比量,帮助神经网络处理不同的颜色条件。Color CLAHE Chance – 图像将应用对比度受限的自适应直方图均衡化的百分比机会。 CLAHE是一种尝试定位对比度变化的对比度方法,这有助于神经网络处理不同的对比度量。Color CLAHE Max Size – CLAHE 算法的最大“grid size”,这被缩放到输入图像。更高的值将导致更高的对比度应用,这有助于神经网络处理不同的对比度量。5.5 Configuration Presets(预设配置)
某些模型具有预设,可轻松加载不同情况的配置选项。预设加载和保存是一个仅限 GUI 的功能,可以从页面顶部的保存和加载图标访问:
可以为具有配置选项的任何页面保存或加载预设。这使您能够为各种情况保存已知的良好设置,并能够轻松加载它们。预设不仅限于训练选项,您可以为 Faceswap 的任何部分保存预设(例如提取/训练/转换等)。
请记住点击配置页面底部的Save按钮,以应用您可能已加载的任何预设。
注意:CLI 用户:如果您使用的是 cli,那么您可以通过导航到 Faceswap 文件夹中的 lib/gui/.cache/presets 来访问现有的预设值,但是您需要手动将这些值复制到您的 train.ini 文件中,或者您可以在有显示器的机器上安装 Faceswap,在这台机器上加载/保存您的预设,然后将更新的 train.ini 文件复制到您将实际运行 Faceswap 的机器上。
一旦你有了你想要的模型设置,点击OK保存配置并关闭窗口。
注意:点击OK会保存所有选项卡上的选项,所以一定要仔细检查它们。您可以按Cancel取消任何更改,或按Reset将所有值恢复为默认设置。
6. Setting up
现在您已经准备好了您的人脸,您已经配置了您的模型,是时候开始工作了!
转到GUI中的Train标签:
我们会在这里告诉Faceswap所有东西都存储在哪里,我们想用什么,并开始训练。
6.1 Faces
这是我们告诉facesswap人脸存储在哪里的地方:
Input A – 这是包含您在提取过程中提取的人脸A的文件夹的位置。这些是将从原始场景中移除的人脸,以替换为您的交换人脸,此文件夹中应该有大约 1,000 – 10,000 张面孔。Input B – 这是包含您在提取过程中提取的人脸B的文件夹的位置。这些是将被交换到场景中的人脸,此文件夹中应该有大约 1,000 – 10,000 张面孔。6.2 Model
与您将要接受训练的模型有关的选项:
Model Dir – 这是模型文件将被保存的地方。如果您要启动新模型,则应选择一个空文件夹,如果要从已启动的模型恢复训练,则应选择包含模型文件的现有文件夹。Load Weights – 您可以从之前训练过的模型加载权重。这可以通过基于先前训练的数据初始化权重来帮助“启动”您的模型,只有在您开始新模型时才会使用加载权重。如果您要恢复现有模型,则此选项将被忽略。通常,这只会为编码器加载权重,尽管某些模型(例如 Phaze-A)为您提供了将权重加载到模型其他部分的选项。如果您正在加载权重,那么您通常还需要选择“Freeze Weights ”选项。原因是当您启动模型时,梯度更新将立即开始。未能冻结权重意味着您加载的权重,将被来自模型其余部分的随机初始化数据污染,这将抵消您从加载权重中获得的任何好处。Trainer – 这是您要为交换训练的模型,上面提供了不同模型的概述。Summary – 启用摘要选项只会显示您将训练的模型的摘要,并退出该过程,训练将不会开始。当您使用更复杂的模型,并希望在开始训练课程之前快速检查布局时,这非常有用。如果启用此选项,则不需要提供输入数据。Freeze Weights – 可以冻结模型特定部分的权重。这意味着您冻结的部分将不会继续学习。当您为模型的某个部分加载了权重,或者您只想将训练重点放在模型的特定部分时,这会很有用。通常,当您冻结权重时,您会希望降低学习率。对于大多数模型,选择这个选项只会冻结编码器(这通常是模型中您希望冻结的部分)。然而,有些模型(例如Phase-A)也允许你冻结模型的其他部分。6.3 Training
训练的具体设置:
Batch Size – 如上所述,Batch Size 是指一次通过模型输入的图像数量。增加这个数字将增加VRAM的使用。增加Batch Size 将加速训练到某个点,小Batch Size 提供了一种有助于模型泛化的规则形式。虽然Batch Size 生产的速度更快,但8到16个Batch Size 的产品质量可能更好。其他形式的监管能否取代或消除这种需求,仍是一个有待解决的问题。Iterations – 在自动停止训练之前要执行的迭代次数。这实际上只是为了自动化,或者确保训练在一定时间后停止。通常,当您对预览的质量感到满意时,您会手动停止训练。Distributed – [仅限 NVIDIA] 启用 Tensorflow的镜像分布策略,以在多个 GPU 上进行训练。如果您的系统中有多个 GPU,那么您可以利用它们来加速训练。请注意,这种加速不是线性的,您添加的 GPU 越多,收益递减的就越多。最终,它允许您通过将它们拆分到多个 GPU 来训练更大的批次大小。您将始终受到最弱 GPU 的速度和 VRAM 的限制,因此在相同 GPU 上进行训练时效果最佳。您可以在此处阅读有关 Tensorflow 分布策略的更多信息。No Logs – 提供了损失和模型日志,以便能够在 TensorBoard和 GUI 中分析数据。关闭此功能将意味着您无权访问此数据。实际上,没有理由禁用日志记录,因此通常不应检查此项。6.4 Saving
计划保存模型文件的选项:
Save Interval – 模型应保存到磁盘的频率。当一个模型被保存时,它并没有被训练,所以你可以提高这个值以获得训练的轻微速度提升(即它不会经常等待模型被写出到磁盘)。您可能不想将其提高得太高,因为它基本上是您的“故障安全”。如果模型在训练期间崩溃,那么您将只能从上次保存继续。注意:如果使用 Ping Pong 内存节省选项,则不应将其增加到 100 以上,因为这可能会损害最终质量。Snapshot Interval – Snapshots 是模型在某个时间点的副本。如果您对模型的进展方式不满意,这使您可以回滚到较早的Snapshots ,或者如果您的保存文件已损坏且没有可用的备份,则可以回滚。通常,这应该是一个很大的数字(在大多数情况下默认值应该没问题),因为创建Snapshots 可能需要一段时间,并且在此过程完成时您的模型将不会进行训练。在一段很长的训练过程中,会拍摄很多Snapshots ,所以你可能想要注意这一点,并随着时间的推移删除不需要的Snapshots ,因为它们会占用空间并造成混乱。Snapshots 将保存在您实际的模型文件夹旁边,名称_snapshot和迭代次数附加到文件夹名称的末尾。要从Snapshots 中恢复,很简单,只需删除实际的模型文件夹,并将Snapshots 文件夹重命名为原来的模型名称(即从文件夹名称的末尾删除_snapshot_xxxxx_iters)。6.5 Preview
显示训练进度预览窗口的选项:
如果您使用的是 GUI,那么通常您不会想要使用这些选项。预览是一个弹出的窗口,显示训练的进度。GUI 将此信息嵌入到“Display”面板中,因此弹出的窗口将只显示完全相同的信息并且是多余的。每次保存迭代时,预览都会更新。
Preview Scale – 弹出预览的大小与训练图像的大小相同。如果您的训练图像为 256 像素,则完整预览窗口将为 3072×1792。这对于大多数显示器来说太大了,所以这个选项会按给定的百分比缩小预览。Preview – 启用弹出预览窗口,禁用不弹出预览窗口。对于GUI的使用,通常不要检查这个。Write Image – 这将把预览图像写入faceswap文件夹。如果在没有窗口的系统上训练是有用的。6.6 Timelapse(延时)
生成一组延时图像的选项:
Timelapse 选项是一项可选功能,可让您查看一段时间内在一组固定人脸上的训练进度。在每次保存迭代时,将保存一张图像,显示当时所选人脸的训练进度。请注意,延时图像占用的磁盘空间量,会随着时间的推移而累积。
Timelapse Input A – 包含要用于为人脸A(原始)生成延时的人脸的文件夹,仅使用找到的前 14 个人脸。如果您希望从训练集中选择前 14 张人脸,您可以将其指向您的“Input A”文件夹。Timelapse Input B – 包含要用于为人脸B(交换)侧生成延时的人脸的文件夹,仅使用找到的前 14 个人脸。如果您希望从训练集中选择前 14 张人脸,您可以将其指向您的“Input B”文件夹。Timelapse Output – 您希望保存生成的延时图像的位置。如果您提供了 A 和 B 的源,但将此留空,则这将默认为您选择的模型文件夹。6.7 Augmentation
数据增强特定选项:
Warp To Landmarks – 如前所述,数据被扭曲,以便神经网络可以学习如何重新创建人脸。Warp to Landmarks 是一种不同的变形方法,它尝试将人脸随机变形为另一侧的相似人脸(即对于 A 组,它从 B 组中找到一些相似的人脸,并应用变形,并进行一些随机化)。关于这是否比标准随机变形有任何好处/差异,目前还没有定论。No Flip – 图像被随机翻转,以帮助增加神经网络将看到的数据量。在大多数情况下,这很好,但人脸不对称,因此对于某些目标,这可能是不可取的(例如,人脸一侧的痣)。通常,这应该不受检查,并且在开始训练时,当然应该不受检查。稍后在session期间,您可能希望为某些交换禁用此功能。No Augment Color – Faceswap执行颜色增强(前面有详细说明)。这确实有助于匹配A和B之间的颜色/照明/对比度,但有时可能不是理想的,所以它可以在这里禁用。色彩增强的影响如下:No Warp – 扭曲图像对于神经网络正确学习是非常重要的,所以总是确保在开始一个模型时,禁用这个选项,以及在大部分训练中。然而,当你快要训练结束的时候,你可以关闭这个功能,把细节展现出来。6.8 Global
全局Faceswap选项:
这些选项不仅适用于训练,而且适用于Faceswap的每个部分:
Exclude GPUs – 如果你有多个gpu,你可以选择在Faceswap中隐藏它们。将鼠标悬停在项目上,查看每个索引适用于哪个GPU。Configfile – 您可以指定自定义 train.ini 文件,而不是使用存储在 faceswap/config 文件夹中的文件。如果您希望在多个不同的已知良好配置之间进行切换,这会很有用。Loglevel – Faceswap 将记录的级别。通常,这应始终设置为 INFO。如果开发人员要求您这样做,您应该仅将其设置为 TRACE,因为它会显着减慢训练速度,并生成大量日志文件。注意:控制台只会记录到VERBOSE级别。日志级别的DEBUG和TRACE只写入日志文件。Logfile – 默认情况下,日志文件存储在 faceswap/faceswap.log 中。 如果您愿意,可以在此处指定不同的位置。一旦锁定所有设置后,请查看它们以确保您满意,然后点击Train按钮开始训练。
7. Monitoring Training(监控训练)
一旦你开始训练,这个过程将花费一到两分钟来建立模型,预加载数据并开始训练。一旦它开始,GUI将进入训练模式,在底部放置一个状态栏,并在右边打开一些tabs:
7.1 Status Bar(状态栏)
他出现在右下角,给出了当前训练的概述。它更新每一次迭代:
你不需要太关注这里的损失数字,对于换脸,它们实际上毫无意义。这些数字给出了神经网络认为它重新创建人脸 A 的程度,以及它重新创建人脸 B 的程度的概念。然而,我们对模型根据人脸 A 的编码创建人脸 B 的情况感兴趣,这是不可能得到一个损失值的,因为没有真实世界的例子可以让神经网络进行比较。
Elapsed – 此训练过程已经运行的时间。Session Iterations – 在此训练session期间,已处理的迭代次数。Total Iterations – 已为此模型的所有session处理的迭代总数。Loss A/Loss B – 当前迭代的损失。注意:可能有多个损失值(例如face、mask、多输出等)。该值是所有损失的总和,因此此处的数字可能相差很大。7.2 Preview Tab(预览Tab)
可视化模型的当前状态。这是模型重新创建和交换人脸的能力的表示,每次模型保存时它都会更新:
了解模型是否完成训练的最佳方法是观看预览,最终,这些显示了实际交换的样子。当您对预览感到满意时,就该停止训练了。眼睛眩光和牙齿等精细细节将是最后的事情,一旦定义了这些,通常是训练即将完成的良好迹象。
预览将显示 12 列。前 6 个是人脸“A”(原始人脸),第二个 6 是人脸“B”(交换人脸)。每组 6 列分为 2 组,每组 3 列。对于这些列中的每一列:第1列是输入模型的未改变的人脸第2列是试图重建那张人脸的模型第3列是试图交换人脸的模型这些表情一开始会是纯色,或者非常模糊,但是随着时间的推移,随着神经网络学会如何重建和交换表情,这些表情会得到改善。不透明的红色区域表示人脸被mask的区域(如果使用mask训练)。如果训练覆盖率低于 100%,您将看到红色框的边缘。这表示“交换区域”或神经网络正在训练的区域。您可以保存当前预览图像的副本与保存按钮在右下角。可以取消勾选右下角的“Enable Preview”框来禁用预览。Graph Tab:此选项卡包含一个图表,显示随时间的损失。每次模型保存时它都会更新,但可以通过点击“Refresh”按钮进行刷新:
你不需要太关注这里的数字,对于换脸,它们实际上毫无意义。这些数字给出了神经网络认为它重新创建人脸 A 的程度,以及它重新创建人脸 B 的程度的概念。然而,我们对模型根据人脸 A 的编码创建人脸 B 的情况感兴趣,这是不可能得到一个损失值的,因为没有真实世界的例子可以让神经网络进行比较。
损失图仍然是一个有用的工具,最终只要损失在下降,那么模型仍在学习。模型学习的速度会随着时间的推移而降低,因此到最后可能很难辨别它是否仍在学习。在这些情况下,请参阅分析选项卡。
根据输出的数量,可能有几个可用的图表(例如total loss、mask loss、 face loss等)。每个图表都显示了该特定输出的损失。您可以使用右下角的保存按钮保存当前图形的副本。可以通过取消右下角的“Enable Preview”框来禁用该图形。Analysis Tab:这个选项卡显示了当前运行和以前的训练session的一些统计数据:
各栏如下:
Graphs – 单击蓝色图形图标,打开选定session的图形。Start/End/Elapsed – 每次session的开始时间、结束时间和总训练时间。Batch – 每个session的批处理大小Iterations – 为每个session处理的迭代总数。EGs/sec – 每秒通过模型处理的人脸数量。当模型未训练时,您可以通过点击右下角的打开按钮,并在模型文件夹中选择模型的 state.json 文件来打开之前训练过的模型的统计信息。
您可以使用右下角的保存图标将分析选项卡的内容保存到 csv 文件中。
如上所述,损失图对于查看损失是否下降很有用,但很难辨别模型何时训练了很长时间。分析选项卡可以为您提供更精细的视图:
单击最新训练session旁边的蓝色图表图标,将调出选定session的训练图表。选择“Show Smoothed”,将平滑量提高到0.99,点击刷新按钮,然后放大,最后5000 – 10000次迭代:现在图表放大了,您应该能够判断损失是否仍在下降或是否已经“收敛”。收敛是指模型不再学习任何东西。在这个例子中,你可以看到,虽然乍一看模型似乎已经收敛,但仔细观察,损失仍在下降:8. Stopping and Resuming(停止和恢复)
只要按下GUI左下角的Terminate按钮,就可以在任何时候停止训练,模型将保存它的当前状态并退出。
通过选择相同的设置并将“model dir”文件夹指向保存文件夹的相同位置,可以恢复模型。这可以通过保存你的Faceswap配置变得更容易,从GUI文件菜单或从选项面板下面的保存图标:
你可以重新加载配置并继续训练。
可以在 Training 文件夹中添加和删除人脸,但请确保在进行任何更改之前停止训练,然后再次恢复。
新更新的版本可以采用下面这种方式,简答快速:
你想让你的模型学习,直到在预览视图中得到你满意的图像,要停止训练,你可以:
命令行:在预览窗口或控制台中按“Enter”GUI:按终止键(Stop)当停止训练时,模型将保存,流程将退出,这可能需要一点时间,所以要有耐心。该模型还将每250次迭代左右进行一次保存(可以手动设置,Save Interval)。
你可以在任何时候停止和恢复训练,只要把FaceSwap指向相同的文件夹,需要删除里面的.bk文件,然后继续即可。
9. Recovering a Corrupted Model(恢复损坏的模型)
有时模型会损坏,这可能出于多种原因,但可以通过预览中的所有人脸变成纯色/乱码,以及损失值飙升至很高的数字并且没有恢复来证明。
faceswap提供了一个轻松恢复模型的工具,在每次保存迭代中,当总体损失值下降时,备份就会被保存。这些备份可以通过以下方式进行恢复:
进入Tools>Restore:Model Dir – 包含损坏模型的文件夹应该在这里输入:点击Restore按钮。恢复后,您应该能够从上次备份继续训练。


















暂无评论内容