
点击@CV计算机视觉,关注更多CV干货

1.亮点
YOLOv6 3.0版本在以前的基础上,增加了:
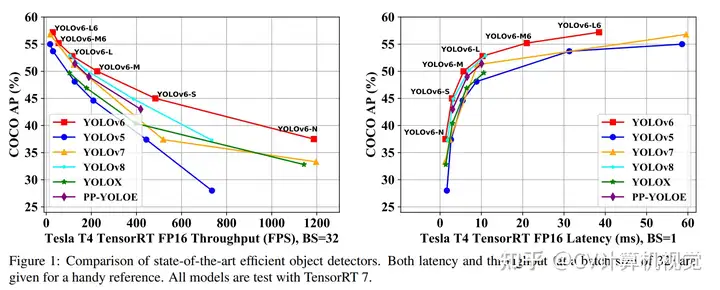
更好的网络结构设计:使用Bi-directional Concatenation (BiC) 、SimCSPSPPF模块作为Neck辅助训练分支:在训练时,额外增加anchor-based的head用于辅助,在推理时去掉anchor-based的head更好的蒸馏策略:在回归分支中使用DFL(Distribution Focal Loss)做蒸馏学习;由于DFL的引入会导致reg分支结构变大,因此在小模型中DFL只用于辅助训练,推理时不使用DFL,以提升小模型的推理速度。YOLOv6 3.0的性能如下图所示:
2.网络结构设计
YOLOv6 3.0使用了增强型的PAN作为Neck。YOLOv6 3.0的总体结构如下图所示:
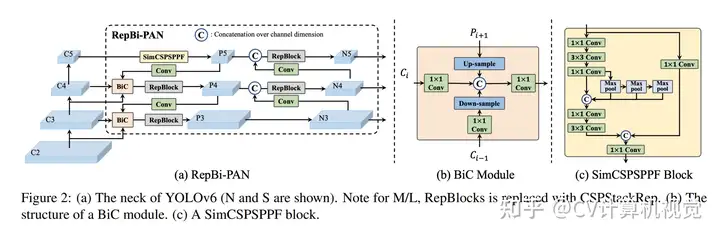
作者使用了Bi-directional Concatenation(BiC)来融合Backbone输出的相邻层的特征。BiC还使用了backbone中的C2C_2特征,以保留更精确的定位信息,利于小目标的检测。
此外,作者将SPPF block与CSP进行结合,并简化了SPPF block,如上图图(c)所示。
3.Anchor-Aided Training
在head部分,在原始anchor-free head的基础上,作者增加了anchor-based head作为辅助分支,如下图所示:
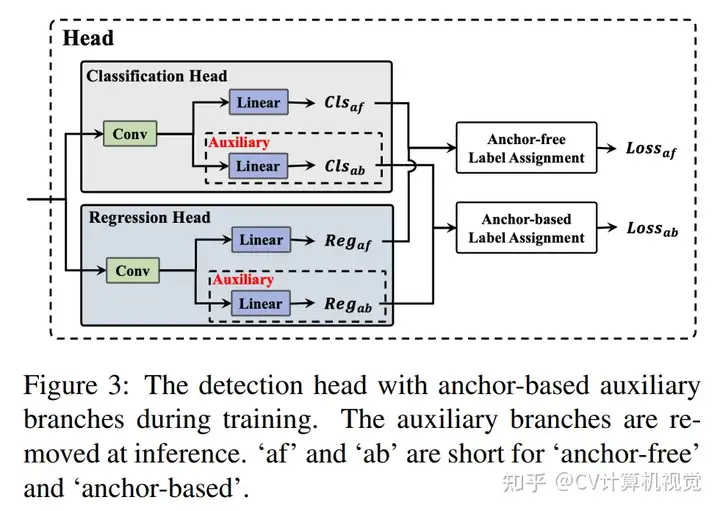
这样能充分利用2种head的优势。在训练时,2种head计算loss并进行反向传播,在推理时,移除anchor-based head。该操作能在不增加推理时间的前提下提升检测器性能。
4.蒸馏学习
作者在分类蒸馏的基础上,还引入了DFL(Distribution Focal Loss)用于回归分支的蒸馏。
使用蒸馏学习后,Loss如下:

LdetL_{d e t}是检测Loss,α\alpha用于平衡检测Loss和蒸馏学习的Loss。 在训练早期,软标签容易学习,因此α\alpha应大一些;随着训练的进行,硬标签更利于学习,α\alpha应小一些。作者设计了α\alpha的衰减策略:
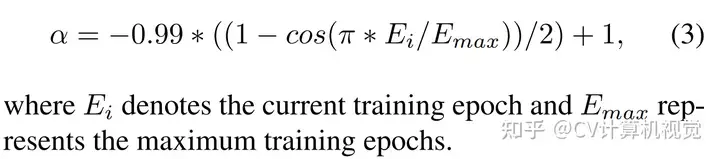
DFL的引入会导致回归分支结构变大,不利于小模型的推理速度。因此在小模型中,DFL作为辅助训练分支,不参与推理计算。训练时,原始的回归分支和DFL回归分支一起训练,原始回归分支学习硬标签,DFL学习硬标签和教师模型输出的软标签;训练一段时间后,DFL回归分支被移除。
5.实验
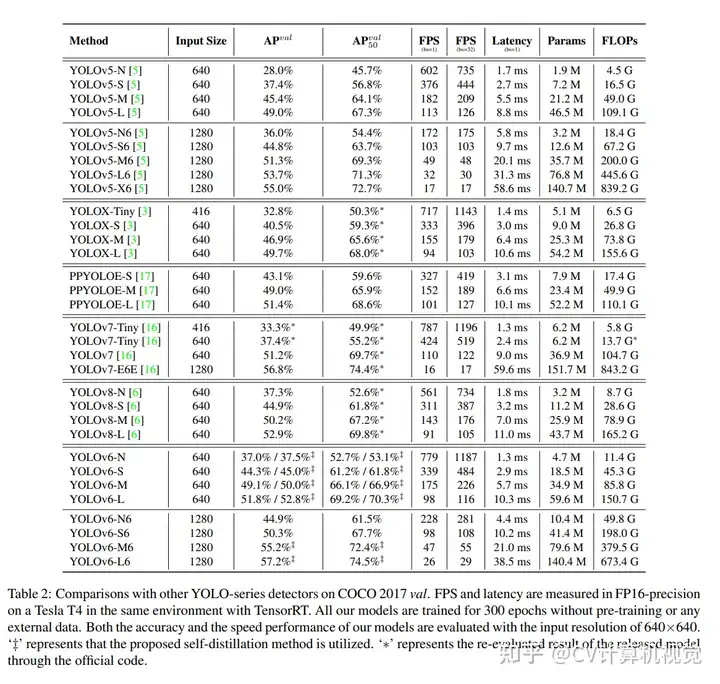
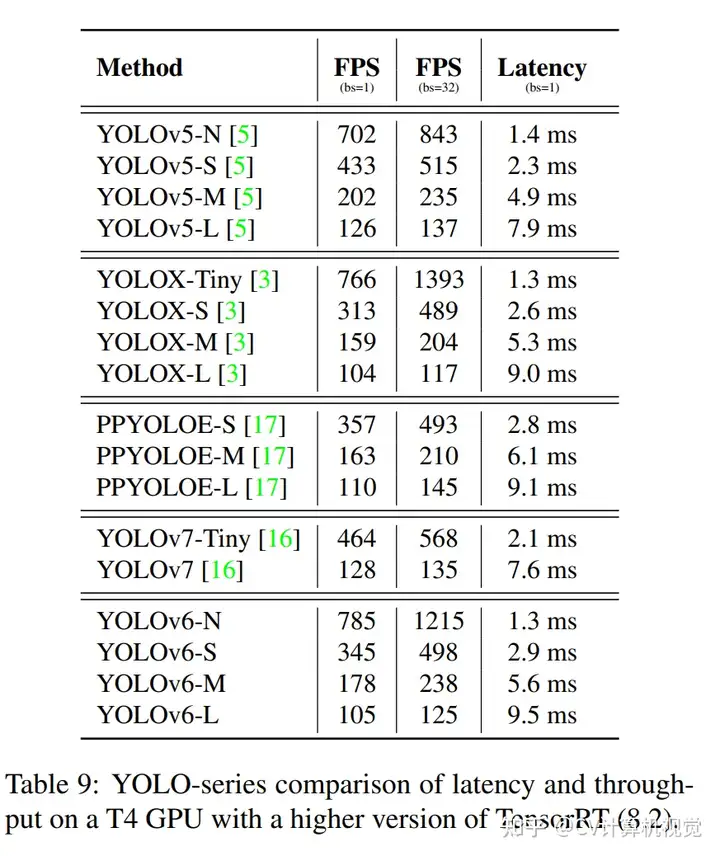
推荐阅读:
















暂无评论内容