
4月,实时物体检测系统的最佳算法–YOLO发布了V4版本。下面的文章,将从多个维度,带你重新认识这个视觉识别领域最优秀的算法。
介绍
对于我们人类而言,我们借助眼睛看事物,肉眼就能够捕捉到每一帧画面中的信息,并将其发送到我们的大脑,我们的大脑就会进行解码并从中得出对我们有意义的信息。听起来很简单对吧?我们只需看看,我们就能了解所看到的物体是什么,它们是如何放置的,以及关于它们的其他大量信息。这是因为我们大脑的处理能力是其他东西都无法比拟的。

大脑的这种有趣的能力使研究人员认为,如果我们能把这种能力赋予一台机器呢。有了它,机器的任务就会简单得多,一旦它能识别周围的物体,它就能更好地与它们互动,这就是改进机器的全部目的,让它们更人性化。
在这个过程中,有一个很大的障碍。我们如何让机器识别一个物体?这就是产生计算机视觉领域的原因,我们称之为“目标检测”。目标检测是计算机视觉和图像处理的一个领域,它处理在数字捕获的图像或视频中检测各类实体对象(如人、书、椅子、汽车、公共汽车等)。
我们把该领域进一步划分为子领域,如人脸检测、活动识别、图像标注等。目标检测在自动驾驶汽车、机器人、视频监控、目标跟踪等领域有着广泛的应用。
对象检测领域面临的五大挑战
1.可变对象数
目标检测是在图像中定位和分类不同数量的目标的问题。重要的是“可变”部分。要检测的对象数量可能因图像而异。与此相关的主要问题是,在机器学习模型中,我们通常需要用固定大小的向量来表示数据。由于我们事先不知道图像中的对象数量,因此我们无法知道正确的输出数量,我们可能需要一些后处理,这增加了复杂性。
2.多种空间比例和长宽比
图像中的对象具有多种空间比例和纵横比,可能有一些对象覆盖了大部分图像,但也会有一些我们可能想要找到但小到十几个像素(或图像的很小百分比)的对象。即使是同一个对象在不同的图像中也可以有不同的比例。这些不同尺寸的物体给追踪它们带来了困难。一些算法使用了滑动窗口的概念,但是效率很低。
3.建模
目标检测需要同时解决目标检测和目标定位两种方法。我们不仅想对物体进行分类,还想把它定位在图像中。为了解决这些问题,大多数研究使用多任务损失函数来惩罚误分类错误和定位错误。由于损失函数的这种二元性,很多时候它在这两方面都表现得很差。
4.有限数据
目前可用于对象检测的带注释数据数量有限,这是该过程中的另一个障碍。对象检测数据集通常包含十几到一百个类的注释示例,而图像分类数据集可以包含多达100000个类,为每个类收集地面真相标签和边界框仍然是一个非常繁琐的任务。
5.实时检测的速度
目标检测算法不仅需要准确地预测目标的类别及其位置,而且还需要以惊人的速度完成所有这些工作,以配合视频处理的实时需求。通常,一个视频的拍摄速度几乎是每秒24帧,而要建立一个能够达到这个帧速率的算法是一个相当困难的任务。
解决目标检测困难的三种方法
我们认识到目标检测领域面临的困难与挑战,这些挑战意味着什么,以及影响的过程。现在我们来看看解决这些挑战的方法—— YOLO 算法。
1.快速R-CNN
快速R-CNN是R-CNN的改进版本,它具有多级流水线环境、时空开销大、目标检测速度慢等缺点。为了解决这些缺点,R-CNN引入了一种新的结构。
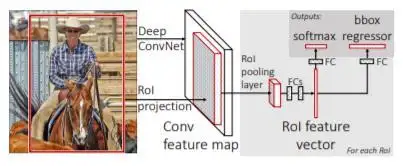
该结构将整个图像与对象建议一起作为输入。最初,该算法在输入图像上运行CNN,并通过使用不同的conv和max池层形成特征映射。之后,对于每个对象提议,兴趣区域(RoI)池层提取固定长度的特征向量,并将其输入到完全连接(FC)层。此层进一步分支到两个输出层:一个为每个类生成SoftMax概率,另一个为每个类输出四个实数,这些类定义了该特定类的边界框。
2.单发MultiBox检测器(SSD)。
SSD作用于自由转发卷积层的方法,该方法输出边界框的固定大小集合以及在那些边界框中存在的对象类实例的分数。它还使用“非最大抑制”来做出最终决定。
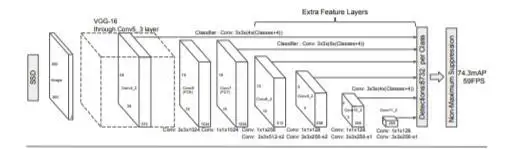
SSD的体系结构非常简单。模型中的初始层是用于图像分类的标准ConvNet层,在它们的术语中是基础网络,在这个基础网络的基础上,它们添加一些辅助层以产生检测,同时考虑到多尺度特征图、默认框和纵横比。
3.视网膜网络(Retina-Net)
Retina-Net 是一个单一的、统一的网络,由一个骨干网和两个特定于任务的子网组成。主干网负责计算整个输入图像上的conv特征映射,是一个非自卷积网络。第一个子网对主干网输出进行分类;第二个子网进行卷积包围和回归。
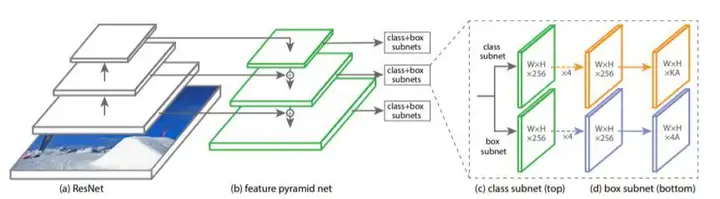
它在前向ResNet结构的基础上使用特征金字塔网络(FPN)骨干网生成丰富的多尺度卷积特征金字塔,然后将其馈送到两个子网,其中一个子网对锚箱进行分类,另一个子网执行从锚箱到地面真值锚箱的回归。
YOLO 算法
到目前为止,我们已经看到了一些非常著名且性能良好的目标检测体系结构。所有这些算法都解决了本文开头提到的一些问题,但在实时目标检测的最重要的一个速度上都失败了。
YOLO算法在我们讨论的所有参数上都有更好的性能,同时还提供了实时使用的高fps。YOLO算法是一种基于回归的算法,它不必选择图像中感兴趣的部分,只需运行一次就可以预测整个图像的类和包围盒。
要了解YOLO算法,首先我们需要了解实际预测的是什么。最终,我们的目标是预测一类对象和指定对象位置的边界框。可以使用四个描述符描述每个边界框:
盒子的中心( bx , by )宽度( bw )高度( bh )与对象类对应的值 c除此之外,我们还预测了一个实数pc,这是边界框中有一个对象的概率。
YOLO不会在输入图像中搜索可能包含对象的感兴趣区域,而是将图像分割为单元格,通常是19×19网格。然后,每个单元负责预测K个边界框。
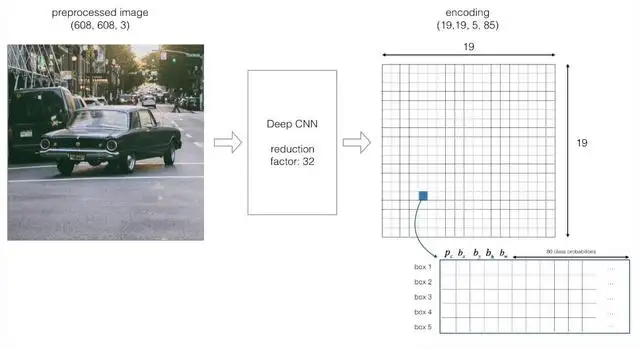
仅当锚定箱的中心坐标位于特定单元中时,才认为对象位于该单元中。由于此特性,中心坐标始终相对于单元格计算,而高度和宽度则相对于整个图像大小计算。
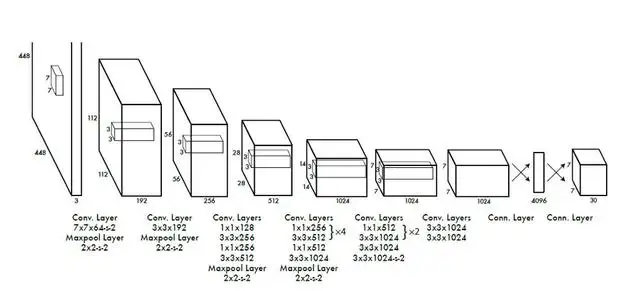
在一次前向传播过程中,YOLO确定单元包含某个类的概率。同样的公式是:
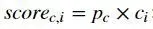
选择概率最大的类并将其分配给特定的网格单元。图像中所有网格单元都会发生类似的过程。
在计算上述类概率之后,图像可能如下所示:
上图显示了预测每个网格单元的类概率的前后对比。预测类概率后,下一步是非最大抑制,它有助于算法去除不必要的锚箱,如下图所示,有很多锚箱是根据类概率计算出来的。

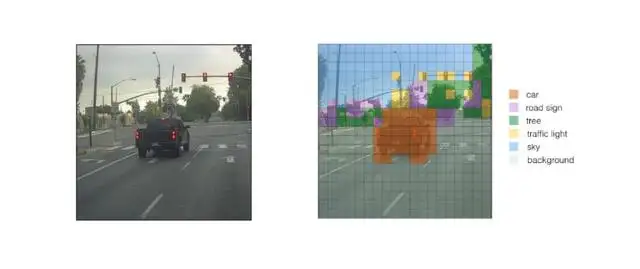
为了解决这个问题,非最大抑制消除了边界框,这些边界框是非常接近的,通过执行IoU(交集超过并集),其中一个具有最高的类概率。
它计算出与具有最高类概率的边界框相对应的所有边界框的IoU值,然后拒绝IoU值大于阈值的边界框。这意味着这两个边界框覆盖同一对象,而另一个边界框覆盖同一对象的概率较低,因此被消除。
一旦完成,算法找到具有次高类概率的绑定框并执行相同的过程,直到我们留下所有不同的绑定框为止。

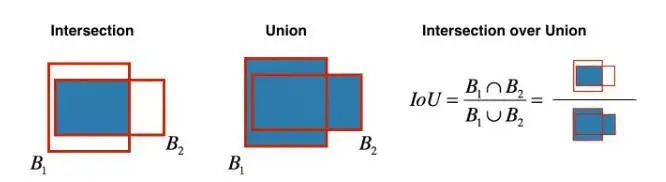
在这之后,我们几乎所有的工作都完成了,算法最终输出所需的向量,显示各自类的边界框的细节。算法的总体架构如下:
另外,算法中最重要的参数,其损失函数如下所示。YOLO同时学习了它预测的所有四个参数(上面讨论过)。
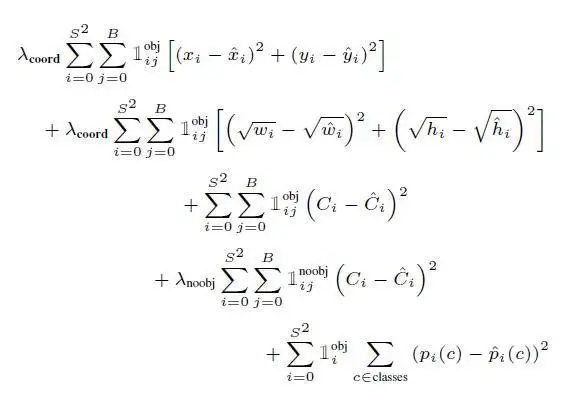
以上是关于 YOLO 算法的所有内容。我们讨论了物体检测的所有方面以及我们在该领域面临的挑战。然后我们提到了解决这些挑战的一些算法,但在最关键的一次实时检测( fps 中的速度)中失败。最后,我们研究了 YOLO 算法,该算法在所面临的挑战方面优于其他所有模型,其快速性在实时目标检测方面可以很好地工作,采用了回归方法。
算法仍在改进中。我们目前有四代的YOLO算法从v1到v4,加上它的小版本YOLO tiny,它是专门为达到令人难以置信的220fps的高速而设计的。
希望以上内容能够让你了解算法和与物体检测相关的概念。
–END–
喜欢本文的同学,记得转发+收藏哦~
也欢迎大家关注我们的公众号:为AI呐喊(weainahan),学习更多AI知识!


















暂无评论内容