
在几个月前引发很大讨论的画图AI — Stable Diffusion 2来了。
先说一个结论,真的太卷了!
相关内容
文章

论文链接:

代码
链接:
这里其实很有意思的一个点,旧版的SD是在CompVis的项目下,新版本是在Stability-AI的项目下。
权重文件
这些对于文字转图像、图像转图像、还有特定修改图片的都需要专门的权重文件,大家可以根据自己需要去下载对应的权重文件包

样例[暂时没本地测试]
depth2img
新的模型主要除了计算速度提升优化、图片大小的提升之外,最大卖点就是引入深度信息!

脚本里的名字是depth2img.py的文件,基本逻辑就是他能识别深度,然后新替换的图片也会保持住。
其中样例如下:

一张图片识别面部是会存在深度的,其他人的脸型会完全嵌入。
这样就能保持图像的空间稳定。



这部分我也会第一个测试一下,看一下具体效果。
inpainting
这里主要就是对于图片固定区域保持,其他区域更换的功能。


其他
txt2img、img2img、superresolution这几个就别叫传统,文字生成图片,图片转图片以及锐化图片,主要就是尺寸、速度及使用资源上的优化及提升。
综上来看,stable diffusion的方向主要还是修图以及学习物体3D结构为目标的。
使用
这次模块和第一版的diffusion差异还是很大。这一版将图像转换图像相关的depth2img和img2img直接包装成为了Gradio的模式,通过web段进行获取。
depth2img
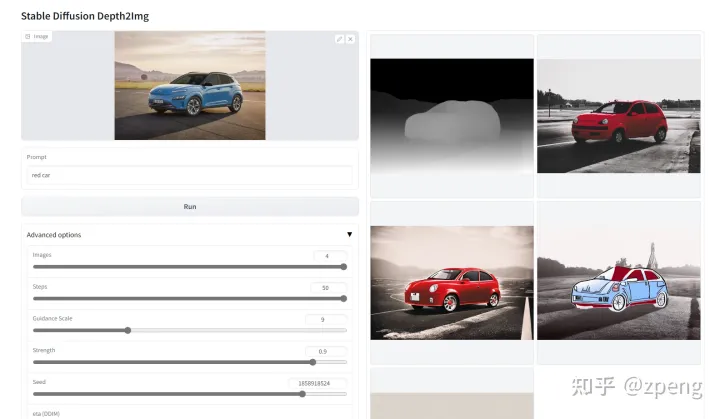
运行之间需要下载权重文件,还有新建文件夹midas_models,将识别图像深度的模型dpt_hybrid-midas-501f0c75.pt 放置好:

分析时候导入图像,输入prompt信息,直接计算就可以获得结果。其中图像包括一个深度预测图,你理解就是激光雷达,找到核心区域,之后将新的结果塞进去,如同上面我给车换颜色;
这个其实最大用处就是固定范围。
这个模式对于目标明确人是有用的,但如果硬往里塞,比如客机的图我塞进去一架战斗机的结果如下:
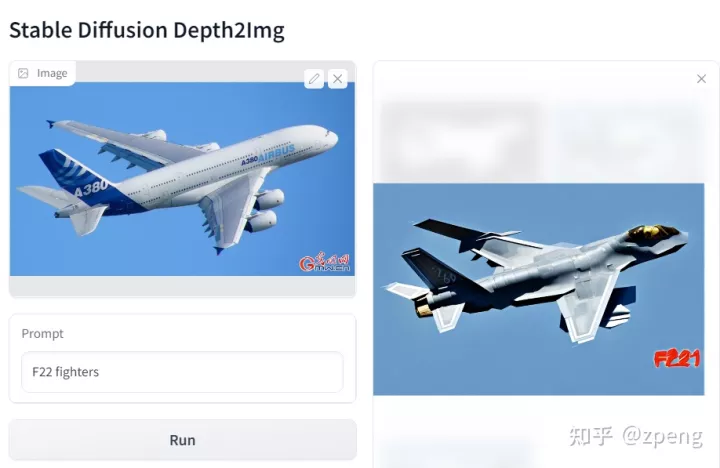
客机版F22,明显你能感觉出这种模式的尴尬;
但是也算了解了未来stable diffusion的方向应该就是吵着固定修改图片区域发展。
具体说一下下面的参数(在depth2img.py里可以修改上下限):
图片输入(Image):选择一个合适的图作为输入,不建议太大,我是爆了很几次显存;关键词输入(Prompt):输入图片将变化情况;图片个数(Images):输出图片张数,最多4张;步数(Steps):diffusion模型迭代次数,最多50次;知道程度(Guidance Scale):图片符合prompt的程度,越大越一致,但是,我测试结果是过了某个值之后它会变得随机,最大是30;效果(Strength);图像与原图的一致性,越小就是和原图一致,我理解这个参数其实就是乘以step看采样层数。通过后台运行可以看到上面steps*strength正好是后台运行的实际step次数,最大值是1;seed: 种子数;采样模式(DDIM): 加速采样,但是我试了超过2返回就是黑图;运行的命令也很简单:
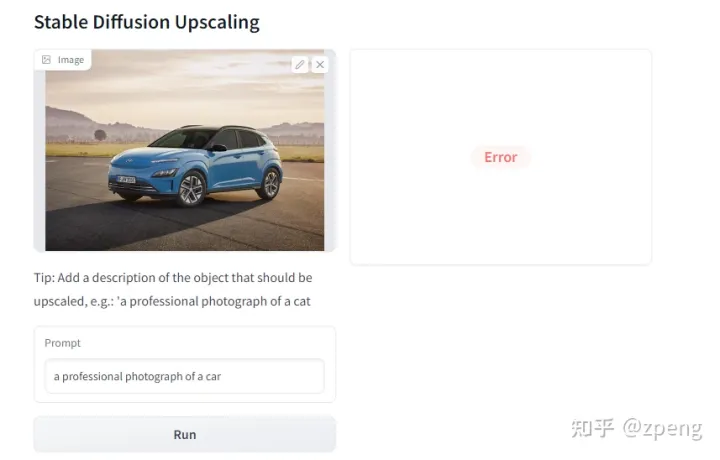
upscalling
上采样的部分会报错,显存不够

算是没有测试成功,这个模块用的也不多。
inpainting
这个部分就很有意思了,你可以用笔刷将特定区域固定,其他区域不变的前提下,就替换某一个位置:
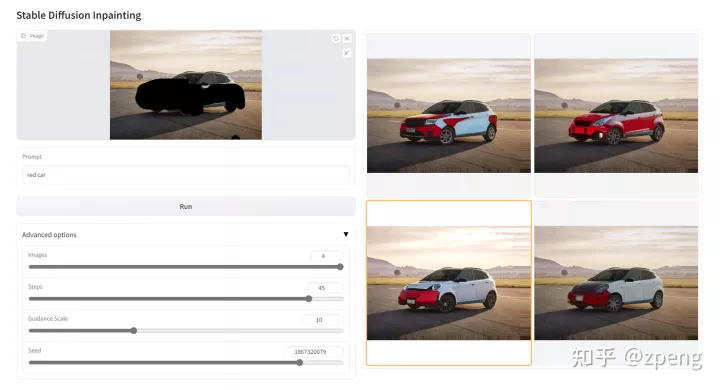
像上图,我将车身区域进行遮盖,在图片区域可以进行选择,然后通过prompt进行替换;
从实际效果来看还是存在颜色区域不稳定的问题,但出来多张还是可以进行选择,这样可玩性就提高很多。
主要参数和之前depth2img大部分一致:
图片输入(Image):选择一个合适的图作为输入,可以进行区域涂抹;关键词输入(Prompt):输入图片将变化情况;图片个数(Images):输出图片张数,最多4张;步数(Steps):diffusion模型迭代次数,最多50次;知道程度(Guidance Scale):图片符合prompt的程度,越大越一致,但是,我测试结果是过了某个值之后它会变得随机,最大是30;seed: 种子数;运行的命令也很简单:

















暂无评论内容