

Hive作为大数据平台举足轻重的框架,以其稳定性和简单易用性也成为当前构建企业级数据仓库时使用最多的框架之一。
但是如果我们只局限于会使用Hive,而不考虑性能问题,就难搭建出一个完美的数仓,所以Hive性能调优是我们大数据从业者必须掌握的技能。本文将给大家讲解Hive性能调优的一些方法及技巧。
Hive性能调优的方式
为什么都说性能优化这项工作是比较难的,因为一项技术的优化,必然是一项综合性的工作,它是多门技术的结合。我们如果只局限于一种技术,那么肯定做不好优化的。
下面将从多个完全不同的角度来介绍Hive优化的多样性,我们先来一起感受下。
1. SQL语句优化
SQL语句优化涉及到的内容太多,因篇幅有限,不能一一介绍到,所以就拿几个典型举例,让大家学到这种思想,以后遇到类似调优问题可以往这几个方面多思考下。

1. union all
insert into table stu partition(tp)
select sage,max(sbirth) stat,max tp
from stuori
group by sage
union all
insert into table stu partition(tp)
select sage,min(sbirth) stat,min tp
from stuori
group by sage;
我们简单分析上面的SQl语句,就是将每个年龄的最大和最小的生日获取出来放到同一张表中,union all 前后的两个语句都是对同一张表按照sage进行分组,然后分别取最大值和最小值。对同一张表相同的字段进行两次分组,这造成了极大浪费,我们能不能改造下呢,当然是可以的,为大家介绍一个语法:from … insert into …,这个语法将from前置,作用就是使用一张表,可以进行多次插入操作:
–开启动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
from stuori
insert into table stu partition(tp)
select sage,max(sbirth) stat,max tp
group by sage
insert into table stu partition(tp)
select sage,min(sbirth) stat,min tp
group by sage;
上面的SQL就可以对stuori表的sage字段分组一次而进行两次不同的插入操作。
这个例子告诉我们一定要多了解SQL语句,如果我们不知道这种语法,一定不会想到这种方式的。
2. distinct
先看一个SQL,去重计数:
select count(1)
from(
select sage
from stu
group by sage
) b;
这是简单统计年龄的枚举值个数,为什么不用distinct?
select count(distinct sage)
from stu;
有人说因为在数据量特别大的情况下使用第一种方式能够有效避免Reduce端的数据倾斜,但是事实如此吗?
我们先不管数据量特别大这个问题,就当前的业务和环境下使用distinct一定会比上面那种子查询的方式效率高。原因有以下几点:
上面进行去重的字段是年龄字段,要知道年龄的枚举值是非常有限的,就算计算1岁到100岁之间的年龄,sage的最大枚举值才是100,如果转化成MapReduce来解释的话,在Map阶段,每个Map会对sage去重。由于sage枚举值有限,因而每个Map得到的sage也有限,最终得到reduce的数据量也就是map数量*sage枚举值的个数。distinct的命令会在内存中构建一个hashtable,查找去重的时间复杂度是O(1);group by在不同版本间变动比较大,有的版本会用构建hashtable的形式去重,有的版本会通过排序的方式,排序最优时间复杂度无法到O(1)。另外,第一种方式(group by)去重会转化为两个任务,会消耗更多的磁盘网络I/O资源。最新的Hive 3.0中新增了 count(distinct )优化,通过配置 hive.optimize.countdistinct,即使真的出现数据倾斜也可以自动优化,自动改变SQL执行的逻辑。第二种方式(distinct)比第一种方式(group by)代码简洁,表达的意思简单明了,如果没有特殊的问题,代码简洁就是优!
这个例子告诉我们,有时候我们不要过度优化,调优讲究适时调优,过早进行调优有可能做的是无用功甚至产生负效应,在调优上投入的工作成本和回报不成正比。调优需要遵循一定的原则。
2.数据格式优化
Hive提供了多种数据存储组织格式,不同格式对程序的运行效率也会有极大的影响。
Hive提供的格式有TEXT、SequenceFile、RCFile、ORC和Parquet等。
SequenceFile是一个二进制key/value对结构的平面文件,在早期的Hadoop平台上被广泛用于MapReduce输出/输出格式,以及作为数据存储格式。
Parquet是一种列式数据存储格式,可以兼容多种计算引擎,如MapRedcue和Spark等,对多层嵌套的数据结构提供了良好的性能支持,是目前Hive生产环境中数据存储的主流选择之一。
ORC优化是对RCFile的一种优化,它提供了一种高效的方式来存储Hive数据,同时也能够提高Hive的读取、写入和处理数据的性能,能够兼容多种计算引擎。事实上,在实际的生产环境中,ORC已经成为了Hive在数据存储上的主流选择之一。
我们使用同样数据及SQL语句,只是数据存储格式不同,得到如下执行时长:
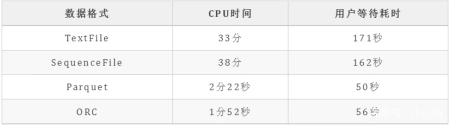
注:CPU时间:表示运行程序所占用服务器CPU资源的时间。用户等待耗时:记录的是用户从提交作业到返回结果期间用户等待的所有时间。
查询TextFile类型的数据表CPU耗时33分钟,查询ORC类型的表耗时1分52秒,时间得以极大缩短,可见不同的数据存储格式也能给HiveSQL性能带来极大的影响。
3.小文件过多优化
小文件如果过多,对 hive 来说,在进行查询时,每个小文件都会当成一个块,启动一个Map任务来完成,而一个Map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的Map数量是受限的。
4.并行执行优化
Hive会将一个查询转化成一个或者多个阶段。这样的阶段可以是MapReduce阶段、抽样阶段、合并阶段、limit阶段。或者Hive执行过程中可能需要的其他阶段。默认情况下,Hive一次只会执行一个阶段。不过,某个特定的job可能包含众多的阶段,而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个job的执行时间缩短。如果有更多的阶段可以并行执行,那么job可能就越快完成。
通过设置参数hive.exec.parallel值为true,就可以开启并发执行。在共享集群中,需要注意下,如果job中并行阶段增多,那么集群利用率就会增加。
set hive.exec.parallel=true;//打开任务并行执行
set hive.exec.parallel.thread.number=16;//同一个sql允许最大并行度,默认为8。
当然得是在系统资源比较空闲的时候才有优势,否则没资源,并行也起不来。
5.数据倾斜优化
数据倾斜的原理都知道,就是某一个或几个key占据了整个数据的90%,这样整个任务的效率都会被这个key的处理拖慢,同时也可能会因为相同的key会聚合到一起造成内存溢出。
Hive的数据倾斜一般的处理方案:
常见的做法,通过参数调优:
set hive.map.aggr=true;
set hive.groupby.skewindata = ture;
当选项设定为true时,生成的查询计划有两个MapReduce任务。
在第一个MapReduce中,map的输出结果集合会随机分布到reduce中,每个reduce做部分聚合操作,并输出结果。
这样处理的结果是,相同的Group By Key有可能分发到不同的reduce中,从而达到负载均衡的目的;
第二个MapReduce任务再根据预处理的数据结果按照Group By Key分布到reduce中(这个过程可以保证相同的Group By Key分布到同一个reduce中),最后完成最终的聚合操作。
但是这个处理方案对于我们来说是个黑盒,无法把控。
那么在日常需求的情况下如何处理这种数据倾斜的情况呢:
sample采样,获取哪些集中的key;将集中的key按照一定规则添加随机数;进行join,由于打散了,所以数据倾斜避免了;在处理结果中对之前的添加的随机数进行切分,变成原始的数据。
例:如发现有90%的key都是null,数据量一旦过大必然出现数据倾斜,可采用如下方式:
SELECT *
FROM a
LEFT JOIN b ON CASE
WHEN a.userid IS NULL THEN concat(hive, rand())
ELSE a.userid
END = b.userid;
注意:给null值随机赋的值不要与表中已有的值重复,不然会导致结果错误。
6. Limit 限制调整优化
一般情况下,Limit语句还是需要执行整个查询语句,然后再返回部分结果。
有一个配置属性可以开启,避免这种情况:对数据源进行抽样。
hive.limit.optimize.enable=true –开启对数据源进行采样的功能
hive.limit.row.max.size –设置最小的采样容量
hive.limit.optimize.limit.file –设置最大的采样样本数
缺点:有可能部分数据永远不会被处理到
7. JOIN优化
1.使用相同的连接键
当对3个或者更多个表进行join连接时,如果每个on子句都使用相同的连接键的话,那么只会产生一个MapReduce job。
2.尽量尽早地过滤数据
减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使用到的字段。
3.尽量原子化操作
尽量避免一个SQL包含复杂逻辑,可以使用中间表来完成复杂的逻辑。
8.谓词下推优化
Hive中的 Predicate Pushdown 简称谓词下推,简而言之,就是在不影响结果的情况下,尽量将过滤条件下推到join之前进行。谓词下推后,过滤条件在map端执行,减少了map端的输出,降低了数据在集群上传输的量,节约了集群的资源,也提升了任务的性能。
我们看下面这个语句:
select s1.key, s2.key
from s1 left join s2
on s1.key >2;
上面是一个Left Join语句,s1是左表,称为保留行表,s2是右表。
问:on条件的s1.key >2是在join之前执行还是之后?也就是会不会进行谓词下推?
答:不会进行谓词下推,因为s1是保留行表,过滤条件会在join之后执行。
而下面这个语句:
select s1.key, s2.key
from s1 left join s2
on s2.key >2;
s2表不是保留行,所以s2.key>2条件可以下推到s2表中,也就是join之前执行。
再看下面这个语句:
select s1.key, s2.key
from s1 left join s2
where s1.key >2;
右表s2为NULL补充表。
s1不是NULL补充表,所以s1.key>2可以进行谓词下推。
而下面语句:
select s1.key, s2.key
from s1 left join s2
where s2.key >2;
由于s2为NULL补充表,所以s2.key>2过滤条件不能下推。
那么谓词下推的规则是什么,到底什么时候会进行下推,什么时候不会下推,总结了下面的一张表,建议收藏保存:
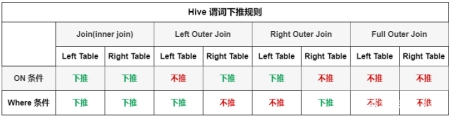
案例:
select a.*
from a
left join b on a.uid = b.uid
where a.ds=2020-08-10
and b.ds=2020-08-10
上面这个SQL主要犯了两个错误:
1.右表(上方b表)的where条件写在join后面,会导致先全表关联在过滤分区。
注:虽然a表的where条件也写在join后面,但是a表会进行谓词下推,也就是先执行where条件,再执行join,但是b表不会进行谓词下推!
2.on的条件没有过滤null值的情况,如果两个数据表存在大批量null值的情况,会造成数据倾斜。
最后
代码优化原则:
理透需求原则,这是优化的根本;把握数据全链路原则,这是优化的脉络;坚持代码的简洁原则,这让优化更加简单;没有瓶颈时谈论优化,这是自寻烦恼。
文章来源于数据管道




















暂无评论内容