
初创公司StabilityAI在最近宣布发布了Stable Diffusion模型,这是一款功能强大并且可以在标准显卡上运行的AI图像生成器。
本文中将介绍如何下载代码和预训练模型,并且将其整合成一个能够在本地电脑运行的项目,最后也会提供完整项目的下载。
本地电脑运行
因为模型比较大,所以必须要有NVIDIA GPU,至少4GB VRAM,本地磁盘至少有15GB的空间,我们打包的项目解压后需要11G的磁盘。
除此以外还需要一个Python环境,这里我们使用3.8,最后就是git,因为我们需要从github中下载一些项目代码。
下载模型权重
从https://huggingface.co/CompVis/stable-diffusion下载模型和预训练权重。撰写本文的最新版本是v1.4-original。
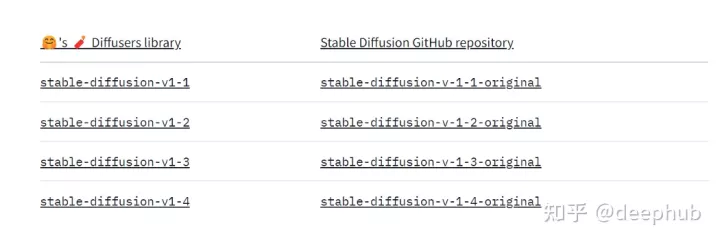
在“Files and versions”选项卡下,单击检查点文件并下载它。
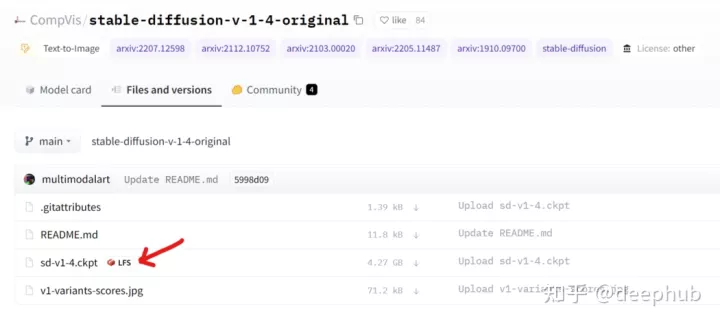
文件很大4.2GB,需要确保下载文件是完整的
从这个GitHub存储库下载下载Stable Diffusion,https://github.com/lstein/stable-diffusion。它是由lstein修改的原始源代码的一个分支,感谢lstein。
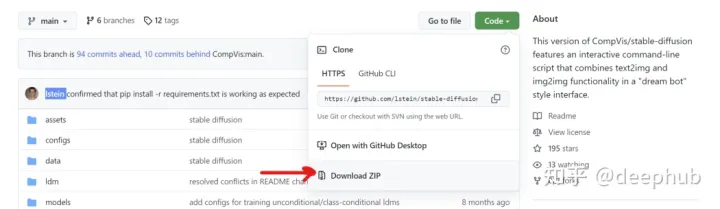
将文件解压缩到本地。在“ldm”文件夹中,创建一个名为“stable-diffusion-v1”的文件夹。如下图所示。
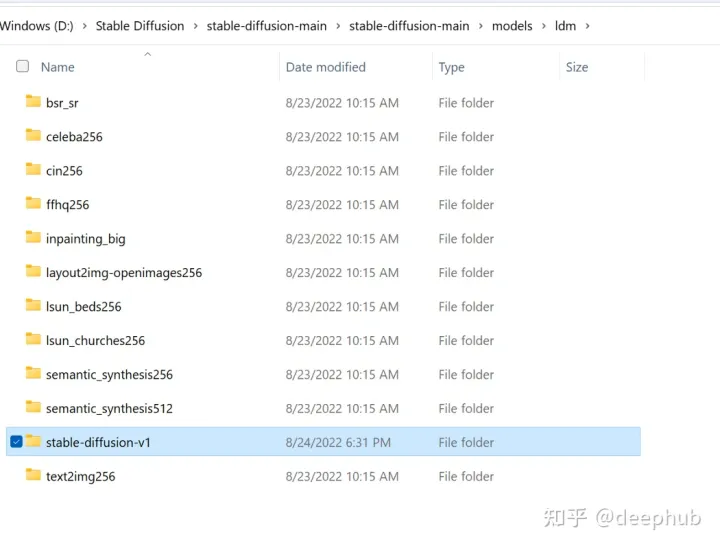
复制下载的模型文件sd-v1-4到stable-diffusion-v1文件夹中,将检其重命名为model.ckpt。
使用Anaconda创建运行环境:
第一行命令会下载运行模型所需的所有依赖项和包。这里的文件也很大,大概几个GB,所以可能需要一段时间。
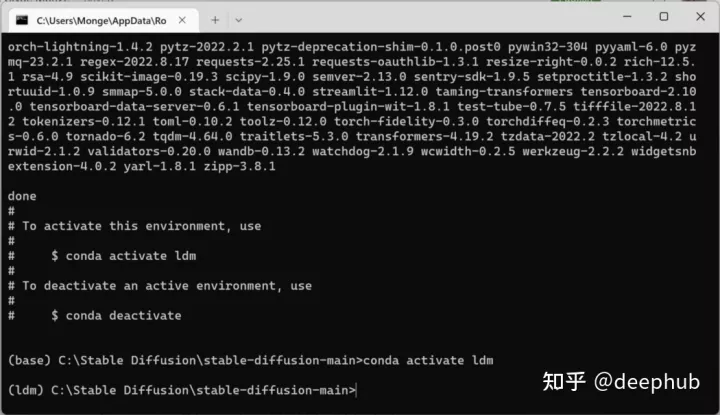
这样环境就准备好了,下面我们加载模型需要的几个小ML模型。
在继续之前,请确保看到了“success”的信息。
现在我们可以开始生成图像了。
命令行将在“dream>”处暂停,也就是说要我们输入文本了。
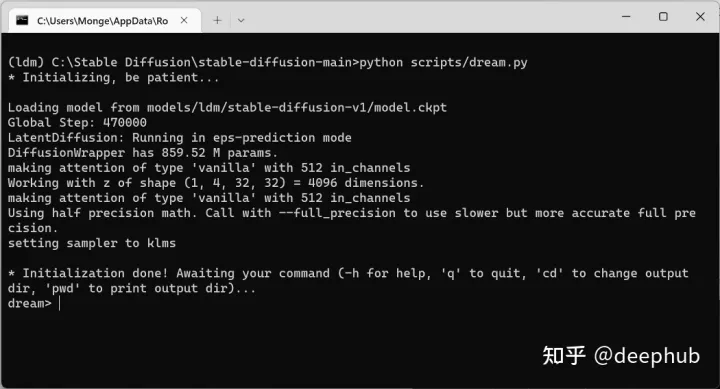
输入后会执行生成的过程
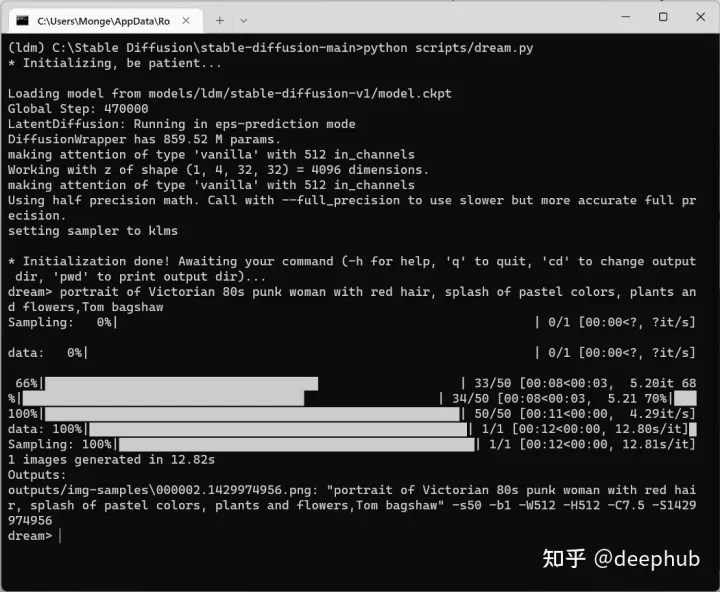
结果如下:

怎么样,还不错吧,如果我们想要调整参数怎么办?下面看看这个方法
创建一个生成图像的web服务
我们使用Gradio UI来将生成图像的模型封装成AP服务,并且提供一个web页面来进行参数的调整:
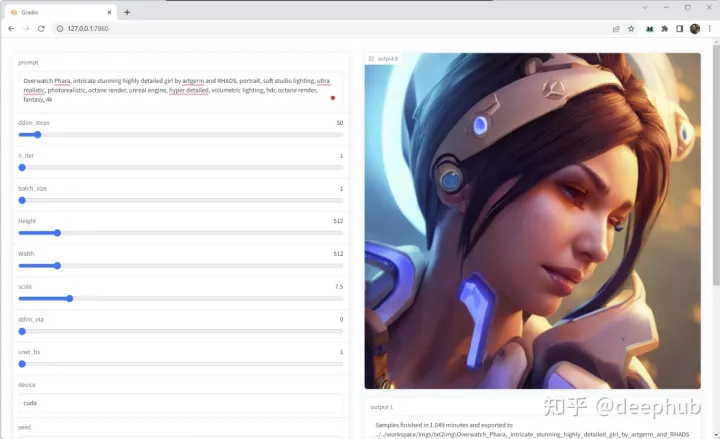
我将所有的依赖都整理成了完整的项目,下载链接放在本文的最后,文件比较大,下载完成后解压应该是这个样子:
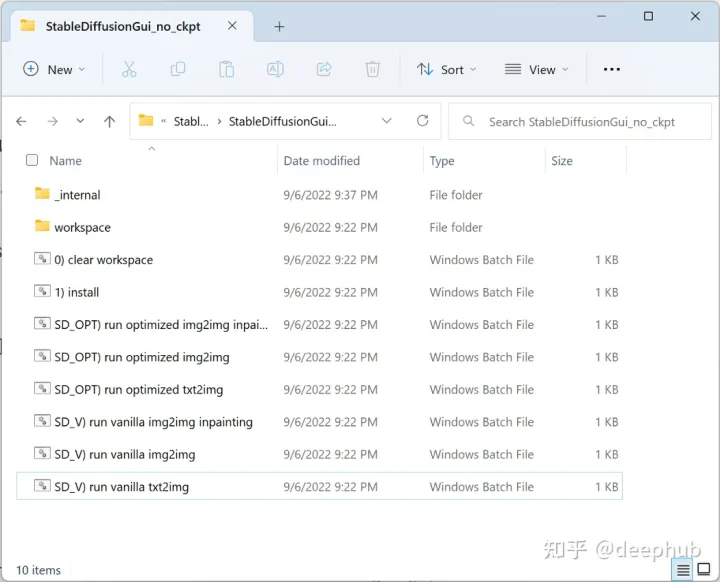
双击“1)install.bat”文件。屏幕底部应该出现一条成功消息,这一步是从Github中下载几个依赖的包。
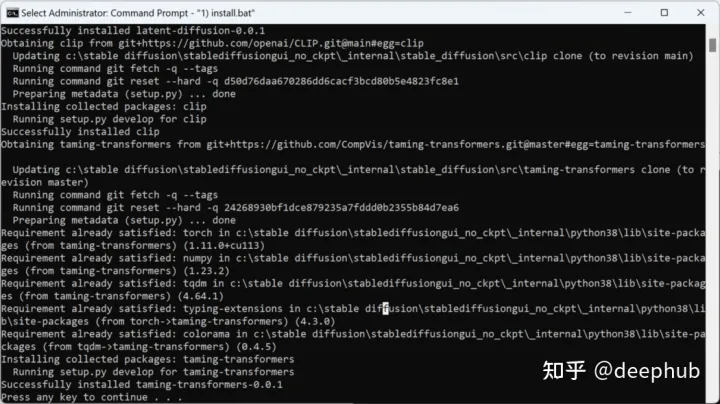
然后运行批处理文件“SD_OPT) run optimized txt2img.bat”。
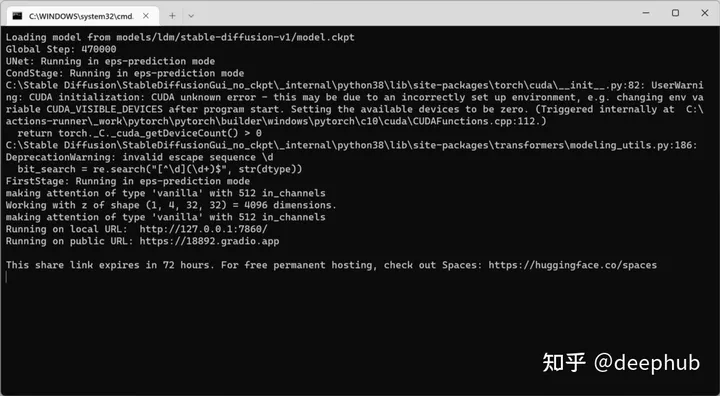
因为加载的模型有4GB多,所以会很久没有相应,请耐心等待当加载完成后显示如下
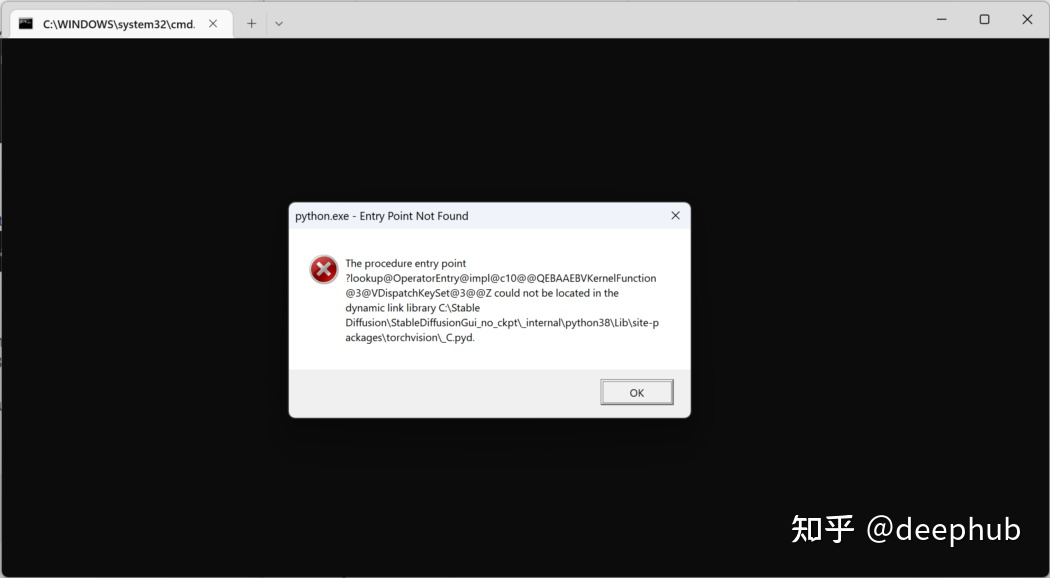
如果有下面弹窗则可以忽略,我也不知道是什么问题,但是对于使用不影响,哈:
然后在浏览器中访问http://127.0.0.1:7860/,就打开Gradio UI。
然后我们输入:
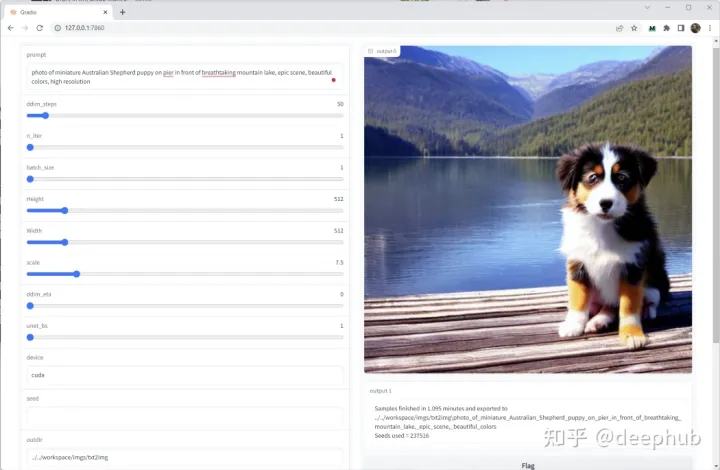
注意:提交按钮在最下面,要按submit才可以进行生成操作,结果还可以吧
总结
最后我们说明下问题:
1、我们这边测试4GB的卡可以生成384×384的图片,512的大概需要6G左右, 1024的则需要8G+,推理速度慢,根据显卡和图片大小不同,大概需要20-60s
2、生成的输入是可以支持中文的,但是不建议中文,因为很可能产生一些玄学的玩意,非常的诡异让人看了非常不舒服,所以建议将中文翻译成英文,并且越详细越好,这样生成的模型会很好
3、生成的图像会保存在workspace文件夹中,可以查看历史输入
4、项目直接内置了python,支持win10和win11,可以直接下载使用
下面来一个我的测试吧,猜猜这是用什么文本生成的?

可以看到,图上的那些疑似的方块汉字就是因为我们输入中包含汉字出来的,汉字比例越大越诡异,所以不建议直接输入汉字。
关注我们公众号 deephub-imba 发送 diffusion 或 扩散模型 可以获取本文的完整项目,项目较大打包压缩完6G+所以请注意磁盘空间占用和下载时间



















暂无评论内容