
引言
随着群脉业务的发展,日志量越来越大,日志收集延迟的现象频频发生,这严重影响了研发的工作效率,而且我们有很多监控报警是基于日志实现的,日志收集的延迟同时影响了 SRE 对于线上问题的排查。下文记录了我们排查和解决该问题的过程,经过优化后,单个 Logstash Pod(2 个 CPU 3G 内存)的日志处理速率(TPS)从 600 events/s 提高到 5000 events/s。
背景知识
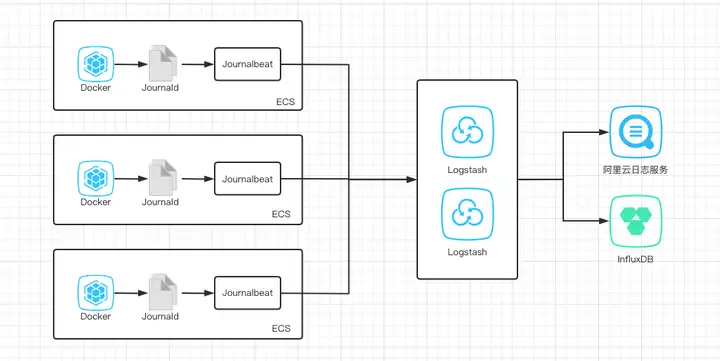
群脉 Kubernetes 集群的日志收集方案使用了 Journalbeat + Logstash + 阿里云日志服务 + InfluxDB 的架构:首先是业务容器写到标准输出,然后由 Docker 收集再写到 Journald,Journalbeat 作为日志采集器,将 Journald 日志发送到 Logstash,Logstash 作为日志处理引擎,对日志进行解析处理,生成符合日志规范的格式并将其发送给阿里云日志服务和 InfluxDB 以分别对日志进行存储、查询和监控报警。
优化
监控先行
横跨多个组件的性能优化是非常困难的事情,难点就在于整个日志收集的过程是串行的,要判断出瓶颈来自哪个组件,需要逐个组件去分析,还要能够保证单一组件的优化对整体性能产生的影响是可量化的。在实施优化之前,需要首先搭建出一套能够量化处理速率的监控,以做到定量分析,这样可以极大的方便我们排查性能问题。
Journalbeat:默认配置会每 30s 输出一次 metrics,记录过去 30s 发送了多少条日志,多少字节数等等信息,但是这个数据尚未提供 API 供监控使用,我们对源码做了修改以支持 API 的方式调用,从而方便我们做监控数据埋点并在 Grafana 中展示。(最新的官方 Jounalbeat 版本已经支持了 API 方式调用,还有大幅度的性能优化,但是由于当时该项目存在 bug1:Journald rotation 的时候会导致 Journalbeat 停止写入 和 bug2:重复发送日志 的原因,所以没有采用)。
Logstash:这是重点要监控的,因为在整个收集链路中,Logstash 不仅要做日志的收集与发送,还要做大量的数据处理逻辑,是最耗费 CPU 的地方,也最有可能成为瓶颈。Logstash 自身提供了监控 API 供性能分析,详情请参考这里。Logstash 官方没有提供详细的文档介绍这些 metrics,这里我们选几个重点的 metrics 作说明:
jvm:服务 CPU 使用率和堆内存的使用率,以及 GC 的使用情况。
in、filtered、out:展示当前 Logstash 在不同的阶段处理的数据量。
duration_in_millis:指 Logstash worker 线程从 queue 中拿到一批输入数据开始到处理并输出到指定后端后这一过程的总耗时。根据这个参数即可计算速率 v(events/s) = out / duration_in_millis * 1000。值得注意的是,根据该讨论 的描述,Logstash 同时会有多个 worker 并行处理,所以该时间是所有批处理耗时的和,并不会直接和时钟时间相关联。
queue_push_duration_in_millis:指写入到 Logstash queue 中所等待的时间总和。如果该值很大,远大于 duration_in_millis,说明 Logstash 的输入插件速率很快,而 filter/output 的处理很慢,导致等待时间非常的长,这时候要重点注意优化后面两个插件。详情参考这个讨论
pipelines:展示每个插件的耗时,参考如下的例子。其参数含义与上面的介绍相同,所以我们可以很轻松的算出每个插件在处理一个 event 的耗时。
hot threads:当前 Logstash 中的繁忙线程。
阿里云日志服务:由于阿里云日志服务本身没有暴露任何 metrics 出来,我们选择一个取巧的方式,那就是每隔 60s 计算一次日志的增量(比如从 0 点开始到 60s 前和 60s 后分别计算结果求差值),以此判断阿里云的写入速率是否出现了瓶颈。
接下来就是通过编码实现将整套完整的监控体系搭建起来,这样就可以轻松的从图表中发现日志收集速率的变化,识别性能瓶颈。
控制变量
优化过程中采用控制变量的方式以确保测试准确性,分别测试了以下三个场景:
Journalbeat 配置将收集到的日志直接写到文件。Journalbeat 配置将收集到的日志写到 Logstash 中,Logstash 不对日志数据做作何处理直接写数据到阿里云日志服务。Journalbeat 配置将收集到的日志写到 Logstash 中,Logstash 根据业务需求处理日志数据再写数据到阿里云日志服务。通过多次测试发现,测试一结果日志采集速率在 10000 events/s 左右,测试二结果在 5000 events/s 左右,测试三结果在 1000 events/s 左右,因此推测出瓶颈在 Logstash 组件上。
优化 Logstash
升级 LogstashLogstash 版本在迭代过程中包含了大量的性能优化,要多关注下 change log,选择更新的版本可能会有事半功倍的效果。
调优 JVM 参数Logstash 在处理数据时会消耗大量 CPU,需要关注 Logstash JVM 相关的监控以及 Hot Threads,判断当前 CPU 是否都在处理日志数据而不是处理 GC,如果频繁 GC,需调整 JVM 及内存相关参数再测试。
优化 filter 插件确保每个 filter 插件都携带一个可读的 id,比如 set_@metadata_field_from_comm,方便快速定位到具体的插件上,默认是一个随机字符串,不可读,不易排查问题。
编写脚本根据监控 API 分析 filter 插件耗时。
优化常见的可能存在性能问题的地方:
正则匹配:正则尽量要能匹配到开头和结尾,以便不满足条件的快速匹配失败,可以提高性能。参考 killing-your-logstash-performance-with-grok。日志脱敏:一般都要递归的比较每个字段(比如字段名包含 password、token 等字符串的其值要脱敏),集中处理可能会带来比较大的性能问题,可以考虑在查询的时候做脱敏,分散脱敏压力。公共逻辑:尽量提前,不要在每个地方做一遍。优化参数pipeline.workers、pipeline.batch.size:Logstash 内存中的 events 数量等于 workers * batchSize,增大 batchSize 和 workers 数值有助于提高并行处理的效率,当然这会导致在内存中的日志数量增加,同时如果发现 CPU 未饱和,则可能是在等待写入到 output 的返回,每个线程会等待数据写入完成后才去拿下一批日志,需要根据测试结果选择合理的值。
优化 output 插件参数(以 InfluxDB 为例)flush_size:表示缓存的数据量到达多少时写入到后端存储,通过多次调整测试使写入和处理达到一个平衡(CPU 和内存利用率最高)。max_retries:表示写入后端存储失败时的最大重试次数,太多的重试会导致 Logstash 阻塞一直等待达到相应的重试次数,由于同一批数据写入到多个 output 后端之间是同步的,假设 InfluxDB 挂了,重试次数设置的又很高,就会导致写入另一个后端阻塞很长时间。优化结果
经过上述优化后,再次进行测试,结果如下图所示:
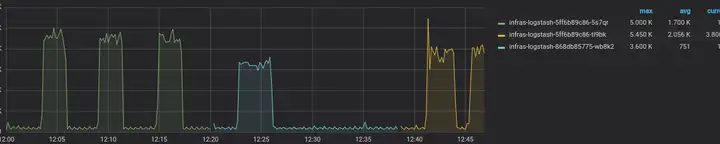
其中绿色线表示只启用了阿里云日志服务作为 Logstash output,蓝色线表示同时启用了阿里云日志服务 + InfluxDB 作为 Logstash output,可以看到 Logstash 的 qps 得到了显著提升。
以下是调优后的 Logstash 配置参数,供参考:
pipeline.batch.size: 500pipeline.workers: 6CPU:2coreMemory:3000Mi总结
综上所述,对于日志收集的优化,可以采用以下方案解决:
为每一个组件定义可量化的指标,如日志投递速度(TPS),用于量化优化结果。通过监控分析各个组件可能存在的性能瓶颈,先从木桶最短的那个板开始优化起,控制变量,逐步寻找问题。对于 Logstash 可以考虑升级版本、优化 JVM 参数、优化运行参数、优化数据处理逻辑等。对于组件的 CPU、内存分配应基于最佳实践,并进行多次测试调整,以最大化资源利用率。补充说明:此优化完成于 2019 年二季度,只是现在才整理出来,某些信息可能已过时,请注意识别。
关于
作者:张中华(Byron Zhang),群脉技术专家。编辑:王永浩(Aaron Wang),群脉首席架构师。本文使用 Zhihu On VSCode 创作并发布
















暂无评论内容