

文 / 十界
出品 / 节点财经
在 7 月 23 日稀土开发者大会上,字节跳动宣布 KubeWharf 项目正式开源。
何为KubeWharf?
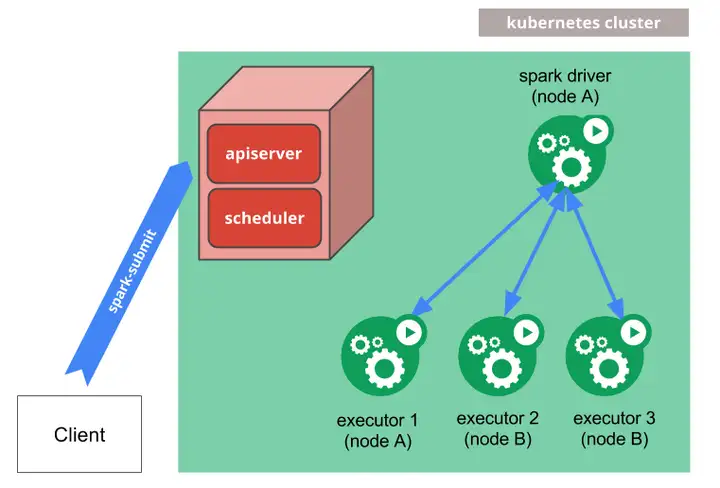
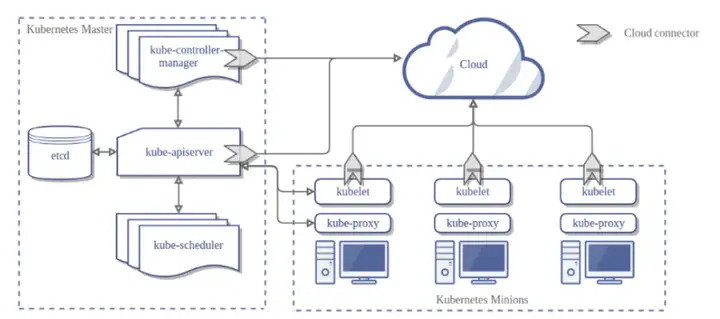
KubeWharf 是字节跳动基础架构团队在对 Kubernetes 进行了大规模应用和不断优化增强之后的技术结晶。这是一套以 Kubernetes 为基础构建的分布式操作系统,由一组云原生组件构成,专注于提高系统的可扩展性、功能性、稳定性、可观测性、安全性等,以支持大规模多租集群、在离线混部、存储和机器学习云原生化等场景。
早在2016年,字节跳动启用 Kubernetes 技术栈,开始对业务进行大规模容器化改造,到 2018 年,内部部署的容器单集群已经达到了上万个节点。时至今日,字节跳动实现云原生化的应用比例已超过 95%。
据了解,字节跳动计划和开源社区合作,逐步开放规模化云原生落地的工具和最佳实践。
为何字节跳动要做KubeWharf?
以 Kubernetes 为代表的云原生技术底座支撑了字节跳动业务的快速发展。从微服务场景开始,Kubernetes 逐渐演化,统一支撑了字节内部的大数据、机器学习以及存储服务等多种形态基础设施。
从 2018 年至今,字节跳动的 Kubernetes 节点的规模增长了 10 倍以上。面对这样的增速,提高 Kubernetes 分布式操作系统的性能、资源利用率、可扩展性、可用性等愈发重要,KubeWharf 就是在这样的背景下诞生。
目前,KubeWharf 第一批计划开源三个项目 :高性能元信息存储系统 KubeBrain、kube-apiserver 七层网关 KubeGateway、轻量级多租户方案 KubeZoo。
以KubeWharf 首批开源项目——KubeBrain为例。Kubernetes 是典型的中心化架构,元信息存储的性能对于集群的可扩展性和稳定性至关重要。在字节使用 Kubernetes 的过程中,随着集群规模增大到 1w 节点左右,etcd 逐渐成为制约集群可扩展性的瓶颈,经常出现读写延迟增高、OOM 等问题。
字节跳动团队在分析了 etcd 的性能瓶颈和 Kubernetes 对于状态信息存储的需求之后,字节跳动基础架构团队自研了 KubeBrain,代替 etcd 作为 Kubernetes 的元数据存储系统。
据字节跳动透露,目前 KubeWharf 开源了第一批的三个项目,未来,将结合内外部用户需求,持续迭代已经开源的项目。
近几年,字节跳动持续开源其他更多 Kubernetes 生态的项目,如在离线统一的高性能分布式调度器、混部管控系统等。以这些有差异化竞争力的云原生组件与技术为基础,推出 Kubernetes 发行版,持续输出在大规模多租集群、混部、大数据等关键场景的解决方案与最佳实践。
这意味着,字节跳动通过输出云原生关键场景下丰富的解决方案和实践,将为云原生开发者提供工具、参考和新思路。
节点财经声明:文章内容仅供参考,文章中的信息或所表述的意见不构成任何投资建议,节点财经不对因使用本文章所采取的任何行动承担任何责任。

















暂无评论内容