
一、etcd 优化
1、etcd 采用本地 ssd 盘作为后端存储存储2、etcd 独立部署在非 k8s node 上3、etcd 快照(snap)与预写式日志(wal)分盘存储etcd 详细的优化操作可以参考上篇文章:etcd 性能测试与调优。
二、apiserver 的优化
1、参数调整
–max-mutating-requests-inflight :在给定时间内的最大 mutating 请求数,调整 apiserver 的流控 qos,可以调整至 3000,默认为 200–max-requests-inflight:在给定时间内的最大 non-mutating 请求数,默认 400,可以调整至 1000–watch-cache-sizes:调大 resources 的 watch size,默认为 100,当集群中 node 以及 pod 数量非常多时可以稍微调大,比如: –watch-cache-sizes=node#1000,pod#50002、etcd 多实例支持
对于不同 object 进行分库存储,首先应该将数据与状态分离,即将 events 放在单独的 etcd 实例中,在 apiserver 的配置中加上–etcd-servers-overrides=/events#https://xxx:3379;https://xxx:3379;https://xxx:3379;https://xxxx:3379;https://xxx:3379,后期可以将 pod、node 等 object 也分离在单独的 etcd 实例中。
3、apiserver 的负载均衡
通常为了保证集群的高可用,集群中一般会有多个 master 节点,kubelet 的连接也会被均分到不同的 apiserver,在 k8s v1.10 以前的版本中,kubelet 使用 HTTP/2,HTTP/2 为了提高网络性能,一个主机只建立一个连接,所有的请求都通过该连接进行,默认情况下,即使网络异常,它还是重用这个连接,直到操作系统将连接关闭,而操作系统关闭僵尸连接的时间默认是十几分钟,所以在 v1.10 以前的版本中 kubelet 连接 apiserver 超时之后不会主动 reset 掉连接进行重试,除非主动重启 kubelet 或者等待十多分钟后其进行重试。
此问题在 v1.10 版本中被修复过(track/close kubelet->API connections on heartbeat failure #63492),代码也被 merge 到了 v1.8 和 v1.9,但是该问题并没有完全修复,直到 v1.14 版本才被完全修复( kubelet: fix fail to close kubelet->API connections on heartbeat failure #78016)。
所以为了保证 apiserver 的连接数均衡,请使用 v1.14 及以上版本。
4、使用 pprof 进行性能分析
pprof 是 golang 的一大杀器,要想进行源码级别的性能分析,必须使用 pprof。
然后打开 svg 文件:
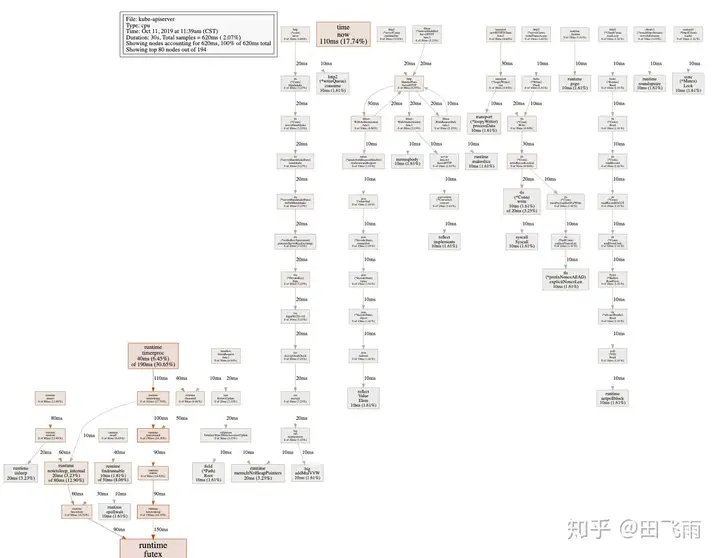
可以通过 graph 以及交互式界面得到 cpu 耗时、goroutine 阻塞等信息,apiserver 中的对象比较多,序列化会消耗非常大的时间,golang 标准库的 json 也有很严重的性能问题,开源的 json-iter 相比标准库有不少性能上的提升,但 json-iter 有很多标准库不兼容的问题,此前也有相关的 issue 进行反馈但并没有合进主线。
三、kube-controller-manager 的优化
1、参数优化
调大 –kube-api-qps 值:可以调整至 100,默认值为 20调大 –kube-api-burst 值:可以调整至 100,默认值为 30禁用不需要的 controller:kubernetes v1.14 中已有 35 个 controller,默认启动为–controllers,即启动所有 controller,可以禁用不需要的 controller调整 controller 同步资源的周期:避免过多的资源同步导致集群资源的消耗,所有带有 –concurrent 前缀的参数2、kube-controller-manager 升级过程 informer 预加载
参考自 阿里巴巴云原生实践 15 讲controller-manager 中存储的对象非常多,每次升级过程中从 apiserver 获取这些对象并反序列化的开销是无法忽略的,重启 controller-manager 恢复时可能要花费几分钟才能完成。我们需要尽量的减小 controller-manager 单次升级对系统的中断时间,主要有以下两处改造:
预启动备 controller informer,提前加载 controller 需要的数据主 controller 升级时,会主动释放 Leader Lease,触发备立即接管工作通过此方案 controller-manager 中断时间降低到秒级别(升级时 < 2s),即使在异常宕机时,备仅需等待 leader lease 的过期(默认 15s),无需要花费几分 钟重新同步数据。通过这个增强,显著的降低了 controller-manager MTTR(平均恢复时间),同时降低了 controller-manager 恢复时对 apiserver 的性能冲击。
此方案需要对 controller-manager 上面两处的代码进行修改,controller-manager 默认的启动方式是先拿到锁然后 callback run 方法,在 run 方法中会启动 informers 然后同步对象,在停止时也要改为主动释放 leader lease。
四、kube-scheduler 优化
在 k8s 核心组件中,调度器的功能做的比较通用,大部分公司都不会局限于当前调度器的功能而进行一系列的改造,例如美团就对 kube-scheduler 进行过一些优化,并将预选失败中断机制(详见PR)和将全局最优解改为局部最优解(详见PR1,PR2)等重要 feature 回馈给了社区。
首先还是使用好调度器的基本功能:
Pod/Node Affinity & Anti-affinityTaint & TolerationPriority & PreemptionPod Disruption Budget然后再进行一些必要的优化。
1、参数优化
调大–kube-api-qps 值:可以调整至 100,默认值为 50
2、调度器优化
扩展调度器功能:目前可以通过 scheduler_extender 很方便的扩展调度器,比如对于 GPU 的调度,可以通过 scheduler_extender + device-plugins 来支持。多调度器支持:kubernetes 也支持在集群中运行多个调度器调度不同作业,例如可以在 pod 的 spec.schedulerName 指定对应的调度器,也可以在 job 的 .spec.template.spec.schedulerName 指定调度器。动态调度支持:由于 kubernetes 的默认调度器只在 pod 创建过程中进行一次性调度,后续不会重新去平衡 pod 在集群中的分布,导致实际的资源使用率不均衡,此时集群中会存在部分热点宿主,为了解决默认调度器的功能缺陷,kubernetes 孵化了一个工具 Descheduler 来对默认调度器的功能进行一些补充,详细说明可以参考官方文档。3、其他优化策略
根据实际资源使用率进行调度:目前默认的调度仅根据 pod 的 request 值进行调度,对于一些资源使用率非常不均衡的场景可以考虑直接以实际的使用率进行调度。等价类划分(Equivalence classes):典型的用户扩容请求为一次扩容多个容器,因此我 们通过将 pending 队列中的请求划分等价类的方式,实现批处理,显著的降 低 Predicates/Priorities 的次数,这是阿里在今年的 kubeCon 上提出的一个优化方式。五、kubelet 优化
1、使用 node lease 减少心跳上报频率
在大规模场景下,大量 node 的心跳汇报严重影响了 node 的 watch,apiserver 处理心跳请求也需要非常大的开销。而开启 nodeLease 之后,kubelet 会使用非常轻量的 nodeLease 对象 (0.1 KB) 更新请求替换老的 Update Node Status 方式,这会大大减轻 apiserver 的负担。
2、使用 bookmark 机制
kubernetes v1.15 支持 bookmark 机制,bookmark 主要作用是只将特定的事件发送给客户端,从而避免增加 apiserver 的负载。bookmark 的核心思想概括起来就是在 client 与 server 之间保持一个“心跳”, 即使队列中无 client 需要感知的更新,reflector 内部的版本号也需要及时的更新。
比如:每个节点上的 kubelet 仅关注 和自己节点相关的 pods,pod storage 队列是有限的(FIFO),当 pods 的队列更新时,旧的变更就会从队列中淘汰,当队列中的更新与某个 kubelet client 无关时,kubelet client watch 的 resourceVersion 仍然保持不变,若此时 kubelet client 重连 apiserver 后,这时候 apiserver 无法判断当前队列的最小值与 kubelet client 之间是否存在需要感知的变更,因此返回 client too old version err 触发 kubelet client 重新 list 所有的数据。
3、限制驱逐
kubelet 拥有节点自动修复的能力,例如在发现异常容器或不合规容器后,会对它们进行驱逐删除操作,这对于有些场景来说风险太大。例如当 kubelet 发现当前宿主机上容器个数比设置的最大容器个数大时,会挑选驱逐和删除某些容器,虽然正常情况下不会轻易发生这种问题,但是也需要对此进行控制,降低此类风险,配置 kubelet 的参数 —-eviction-hard= 来确保在任何情况 kubelet 都不会驱逐容器。
4、原地升级
kubernetes 默认只要 pod 的 spec 信息有改动,例如镜像信息,此时 pod 的 hash 值就会改变,然后会导致 pod 的销毁重建,一个Pod中可能包含了主业务容器,还有不可剥离的依赖业务容器,以及SideCar组件容器等,这在生产环境中代价是很大的,一方面 ip 和 hostname 可能会发生改变,pod 重启也需要一定的时间,另一方面频繁的重建也给集群管理带来了更多的压力,甚至还可能导致无法调度成功。为了解决该问题,就需要支持容器的原地升级。可以开发一个 operator 来实现相关的功能,这种方法需要重新实现一个 resource 对应于 k8s 中的应用,然后当 pod 中的 image 改变后只更新 pod 不重建,kubelet 会重启 container 的,可以参考阿里的 cafeDeployment,或者对原生 deployment/statefulset 中的控制器直接进行修改。
六、kube-proxy 优化
1、使用 ipvs 模式
由于 iptables 匹配时延和规则更新时延在大规模集群中呈指数增长,增加以及删除规则非常耗时,所以需要转为 ipvs,ipvs 使用 hash 表,其增加或者删除一条规则几乎不受规则基数的影响。iptables 以及 ipvs 详细的介绍会在后面的文章中介绍。
2、独立部署
kube-proxy 默认与 kubelet 同时部署在一台 node 上,可以将 kube-proxy 组件独立部署在非 k8s node 上,避免在所有 node 上都产生大量 iptables 规则。
七、镜像优化
一个容器的镜像平均 2G 左右,若频繁的拉取镜像可能会将宿主机的带宽打满,甚至影响镜像仓库的使用,
1、限制镜像的大小2、镜像缓存3、使用 P2P 进行镜像分发,比如:dragonfly4、基础镜像预加载:一般镜像会分为三层,第一层基础镜像即 os,第二层环境镜像即带有 nginx、tomcat 等服务的镜像,第三层业务镜像也就是带有业务代码的镜像。基础镜像一般不会频繁更新,可在所有宿主机上预先加载,环境镜像可以定时进行加载,业务镜像则实时拉取。八、客户端优化
在大规模场景下,集群中所有的 daemonset、webhook 以及 operator 等组件非常多,每个客户端都要从 apiserver 中获取资源,此时对 apiserver 的压力非常大,若客户端使用不当很可能导致 apiserver 或者 etcd 崩溃,此时对客户端的行为进行限制就非常有必要了。首先应确保所有客户端都使用 ListWatch 机制而不是只使用 List,并且在使用 ListWatch 机制时尽量不要覆盖 ListOption,即直接从 apiserver 的缓存中获取资源列表,避免请求直接命中 etcd。
k8s.io/apimachinery/pkg/apis/meta/v1/types.go:
九、资源使用率的提升
在大规模场景中,提高资源使用率是非常有必要的,否则会存在严重的资源浪费,资源使用率高即宿主的 cpu 利用率,但是不可能一个宿主上所有容器的资源利用率都非常高,容器和物理机不同,一个服务下容器的平均 cpu idle 一般到 50% 时此服务就该扩容了,但物理机 idle 在 50% 时还是处于稳定运行状态的,而服务一般都会有潮汐现象,所以需要一些其他方法来提高整机的 cpu 使用率。
1、pod 分配资源压缩:为 pod 设置 request 和 limit 值,对应的 pod qos 为 burstable。2、宿主资源超卖:比如将一个实际只有 48 核的宿主上报资源给 apiserver 时上报为 60 核,以此来对宿主进行资源超卖。第一种方法就是给宿主机打上特定的资源超卖标签,然后直接修改 kubelet 的代码上报时应用指定的超卖系数,或者使用 admission webhook 在 patch node status 时修改其资源中对应的值,这种方法需要对 kubelet 注册 apiserver 的原理有深入了解。3、在离线业务混部:大部分公司都会做在离线混部,在离线混部需要解决的问题有:
1、在线能及时抢占离线资源(目前内核不支持)2、让离线高效的利用空闲 CPU 腾讯云对在离线有深入研究,整机资源使用率已达 90%,可以借鉴其一些设计理念,参考:腾讯成本优化黑科技:整机CPU利用率最高提升至90%。
十、动态调整 Pod 资源限制
参考:超大规模商用 K8s 场景下,阿里巴巴如何动态解决容器资源的按需分配问题?在大规模集群场景,服务可能会因高峰期资源不足导致响应慢等问题,对于某些应用时间内 HPA 或者 VPA 都不是件容易的事情。先说 HPA,我们或许可以秒级拉起了 Pod,创建新的容器,然而拉起的容器是否真的可用呢。从创建到可用,中间要经过调度、分配ip、拉取镜像、同步白名单等,可能需要比较久的时间,对于大促和抢购秒杀 这种访问量“洪峰”可能仅维持几分钟或者十几分钟的实际场景,如果我们等到 HPA 的副本全部可用,可能市场活动早已经结束了。至于社区目前的 VPA 场景,删掉旧 Pod,创建新 Pod,这样的逻辑更难接受。
目前阿里的 policy engine 支持动态调整 pod 的资源限制,底层使用类似 cadvisor 的一个数据采集组件,直接采集 cgroup 数据,然后对容器做画像,当容器资源不足时会瞬时快速修改容器 cgroup 文件目录下的的参数,如果是 cpu 型的,直接调整低优先级容器的 cgroup 下 cpu quota 的值,首先抑制低优先级的容器对于 cpu 的争抢,然后再适当上调高优先级容器的相关资源值。
十一、其他优化方法
1、禁用 kubectl 的 –all 操作,避免误操作导致某一资源全部被删除
十二、总结
以上是笔者对 kubernetes 性能优化方法的一些思考及总结,部分方法参考社区的文档。kubernetes 拥有庞大而快速发展的生态系统,以上提及的优化方法仅是冰山一角,性能优化无终点,在生产环境中能发挥价值才是最有用的。
参考: eBay应用程序集群管理器TESS.IO在大规模集群下的性能优化
开放下载《阿里巴巴云原生实践 15 讲》揭秘九年云原生规模化落地
华为云在 K8S 大规模场景下的 Service 性能优化实践
记一次kubernetes集群异常: kubelet连接apiserver超时
















暂无评论内容