
Kubernetes Ingress 简介
通常情况下,Kubernetes 集群内的网络环境与外部是隔离的,也就是说 Kubernetes 集群外部的客户端无法直接访问到集群内部的服务,这属于不同网络域如何连接的问题。解决跨网络域访问的常规做法是为目标集群引入一个入口点,所有外部请求目标集群的流量必须访问这个入口点,然后由入口点将外部请求转发至目标节点。
同样,Kubernetes 社区也是通过增设入口点的方案来解决集群内部服务如何对外暴露的问题。Kubernetes 一贯的作风是通过定义标准来解决同一类问题,在解决集群对外流量管理的问题也不例外。Kubernetes 对集群入口点进行了进一步的统一抽象,提出了 3 种解决方案:NodePort、LoadBalancer 和 Ingress。下图是这三种方案的对比: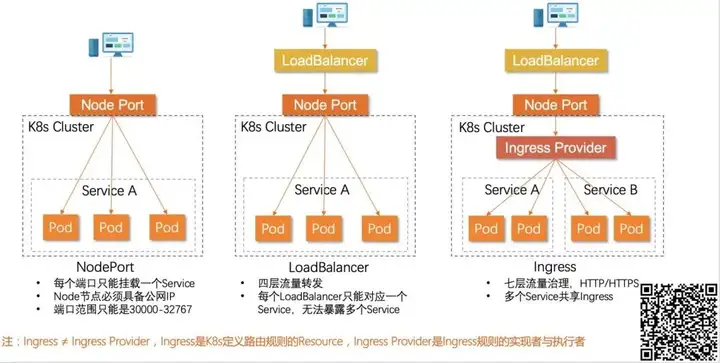
通过对比,可以看到 Ingress 是更适合业务使用的一种方式,可以基于其做更复杂的二次路由分发,这也是目前用户主流的选择。
Kubernetes Ingress 现状
虽然 Kubernetes 对集群入口流量管理方式进行标准化的统一抽象,但仅仅覆盖了基本的 HTTP/HTTPS 流量转发功能,无法满足云原生分布式应用大规模复杂的流量治理问题。比如,标准的 Ingress 不支持流量分流、跨域、重写、重定向等较为常见的流量策略。针对这种问题,存在两种比较主流的解决方案。一种是在 Ingress 的 Annotation 中定义 Key-Value 的方式来拓展;另一种是利用 Kubernetes CRD 来定义新的入口流量规则。如下图所示:

Kubernetes Ingress 最佳实践
本节将从以下 5 个方面展开 Kubernetes Ingress 最佳实践。
流量隔离:部署多套 IngressProvider,缩小爆炸半径灰度发布:如何利 用 IngressAnnotation 来进行灰度发布业务域拆分:如何按照业务域进行 API 设计零信任:什么是零信任,为什么需要零信任,怎么做性能调优:一些实用的性能调优方法流量隔离
在实际业务场景中,集群中后端服务需要对外部用户或者内部其他集群提供服务。通常来说,我们将外部访问内部的流量称为南北向流量, 将内部服务之间的流量称为东西向流量。为了节省机器成本和运维压力,有些用户会选择将南北向流量和东西向流量共用一个 Ingress Provider。这种做法会带来新的问题,无法针对外部流量或者内部流量做精细化的流量治理,同时扩大了故障影响面。最佳的做法是针对外网、内网的场景分别独立部署 Ingress Provider,并且根据实际请求规模控制副本数以及硬件资源,在缩小爆炸半径的同时尽可能提供资源利用率。
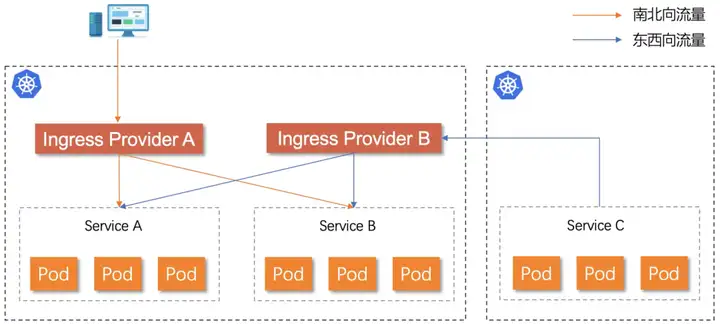
灰度发布
在业务持续迭代发展过程中,业务的应用服务面临着版本频繁升级的问题。最原始最简单的方式,是停掉线上服务的旧版本,然后部署、启动服务的新版本。这种直接将服务的新版本提供给所有用户的方式会带来两个比较严重的问题。首先,在停掉服务旧版本与启动新版本这段时间内,该应用服务是不可用,流量请求的成功率跌零。其次,如果新版本中存在严重的程序 BUG,那么新版本回滚到旧版本的操作又会导致服务出现短暂的不可用,不仅影响用户体验,而且也会对业务整体系统产生诸多不稳定因素。
那么,如何既能满足业务快速迭代的诉求,又能保证升级过程中业务应用对外的高可用?
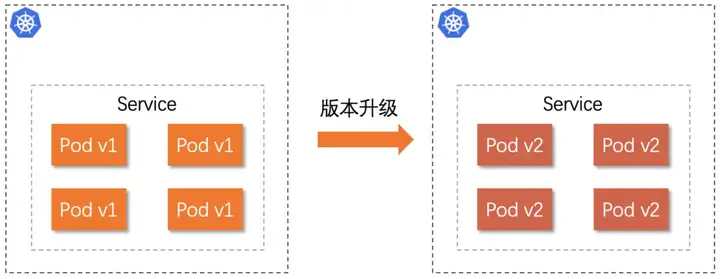
我认为需要解决以下几个核心问题:
如何减小升级的影响面?新版本出现 Bug 时如何快速回滚到稳定版本?如何解决标准 Ingress 不支持流量分流的缺陷?针对前两个问题,业界共识比较通用的做法是采用灰度发布,俗称金丝雀发布。金丝雀发布的思想则是将少量的请求引流到新版本上,因此部署新版本服务只需极小数的机器。验证新版本符合预期后,逐步调整流量,使得流量慢慢从老版本迁移至新版本,期间可以根据当前流量在新老版本上的分布,对新版本服务进行扩容,同时对老版本服务进行缩容,使得底层资源得到最大化利用。
在 Ingress 现状小节里,我们提到了目前比较流行的两种扩展 Ingress 的方案,其中通过为 Annotation 新增 Key-Value 的方式可以解决第三个问题。我们可以在 Annotation 中定义灰度发布需要的策略配置,比如配置灰度流量的 Header、Cookie 以及对应值的匹配方式 (精确匹配或者正则匹配)。之后由 Ingress Provider 识别新定义的 Annotation 并解析为自身的路由规则,也就是关键在于用户选择的 Ingress Provider 要支持丰富的路由方式。
灰度发布——按照 Header 灰度
在进行小流量验证服务新版本是否符合预期的环节中,我们可以有选择的将线上具有一部分特征的流量认为是小流量。请求内容中 Header、Cookie 都可以认为是请求特征,因此针对同一个 API,我们可以按照 Header 或者 Cookie 对线上流量进行切分。如果真实流量中 Header 无差别,我们可以基于线上环境手动制造一些带有灰度 Header 的流量进行验证。此外,我们也可以按照客户端的重要性来分批进行新版本验证,比如对于普通用户的访问请求优先访问新版本,待验证完毕后,再逐步引流 VIP 用户。一般这些用户信息、客户端信息都会存在 Cookie 中。
以 Nginx-Ingress 为例,通过 Annotation 支持 Ingress 的流量分流,按照 Header 灰度的示意图如下:
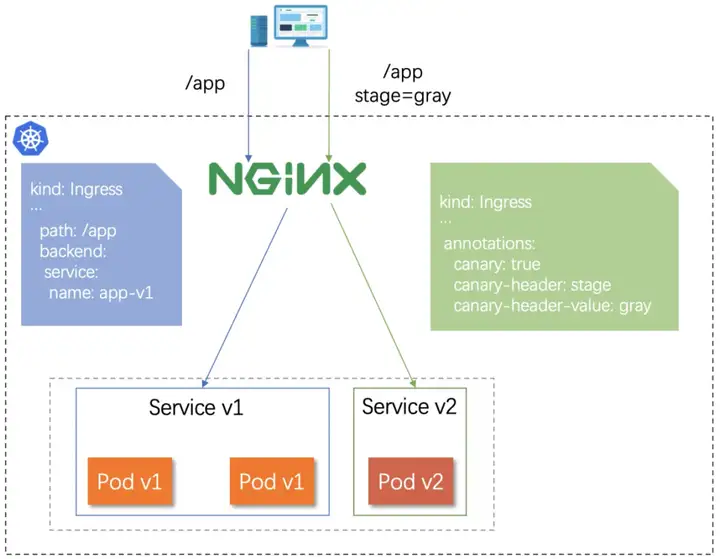
灰度发布——按照权重灰度
按照 Header 灰度的方式可以对特定的请求或者用户提供服务新版本,但是无法很好评估访问新版本的请求规模,因此在为新版本分配机器时可能无法做到资源最大化利用。而按照权重进行灰度的方式可以精确控制流量比例,在机器资源分配上游刃有余。通过前期小流量验证后,后期通过调整流量权重,逐步完成版本升级,这种方式操作简单,易于管理。然而线上流量会无差别地导向新版本,可能会影响重要用户的体验。按照权重灰度的示意图如下:
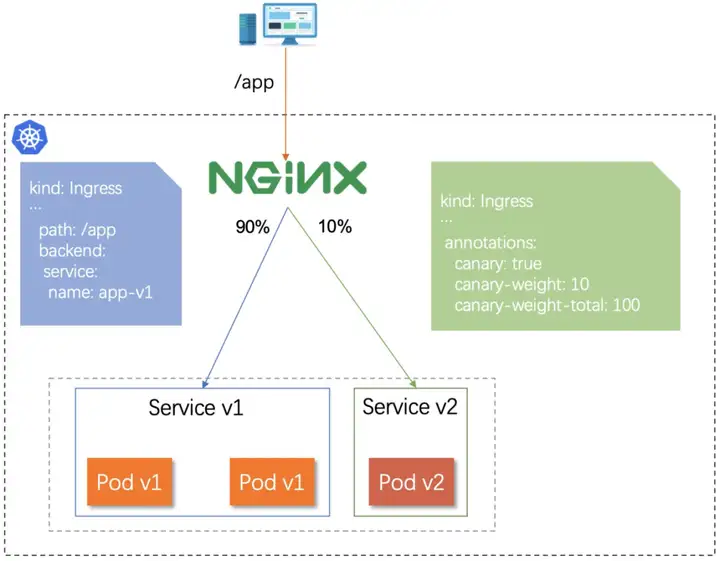
业务域拆分
随着云原生应用规模不断扩大,开发者开始对原来的单体架构进行细粒度的拆分,将单体应用中的服务模块拆分成一个个独立部署运行的微服务,并且这些微服务的生命周期由对应的业务团队独自负责,有效的解决了单体架构中存在的敏捷性不足、灵活性不强的问题。但任何架构都不是银弹,在解决旧问题同时势必会引入一些新的问题。单体应用通过一个四层 SLB 即可完成对外暴露服务,而分布式应用依赖 Ingress 提供七层流量分发能力,这时如何更好的设计路由规则尤为重要。
通常我们会根据业务域或者功能域进行服务拆分,那么我们在通过 Ingress 对外暴露服务时同样可以遵循该原则。为微服务设计对外 API 时可以在原有的 Path 上添加具有代表性意义的业务前缀,在请求完成路由匹配之后和转发请求到后端服务之前时,由 Ingress Provider 通过重写 Path 完成业务前缀消除的工作,工作流程图如下:
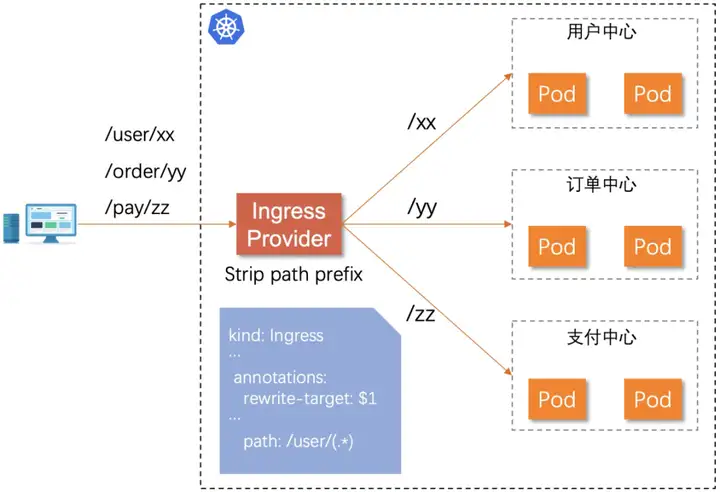
该 API 设计原则易于管理对外暴露的服务集合,基于业务前缀做更细粒度的认证鉴权,同时方便对各个业务域服务进行统一的可观测建设。
零信任
安全问题始终是业务应用的头号公敌,伴随着业务发展的整个生命周期。此外,外部互联网的环境越来越复杂,内部业务架构日益庞大,部署结构涉及公有云、私有云以及混合云多种形态,安全问题愈演愈烈。零信任作为安全领域的一种新型设计模型应用而生,认为应用网络内外的所有用户、服务都不可信,在发起请求、处理请求之前都要经过身份认证,所有授权操作遵循最小权限原则。简单来说就是 trust no-one, verify everything.
下图是关于外部用户->Ingress Provider->后端服务整个端到端落地零信任思想的架构图:
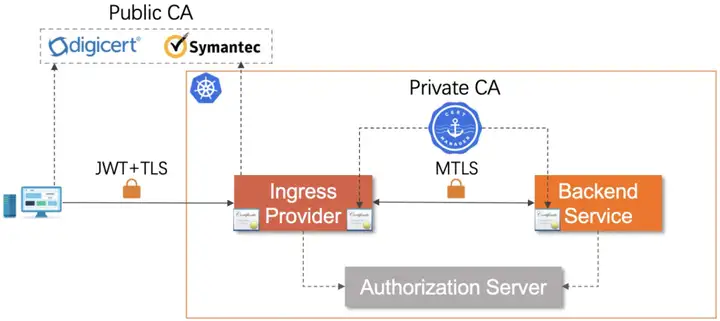
性能调优
所有的外部访问流量都需要先经过 Ingress Provider,因此主要性能瓶颈体现在 Ingress Provider,在高并发、高性能上有了更高的要求。抛开各个 Ingress Provider 之间的性能差异,我们可以通过调整内核参数来进一步释放性能。经过阿里巴巴多年在集群接入层的实践经验,我们可以适当调整以下内核参数:
调大 TCP 连接队列的容量:net.core.somaxconn调大可用端口范围:net.ipv4.ip_local_port_range复用 TCP 连接:net.ipv4.tcp_tw_reuse另一个优化角度是从硬件着手,充分释放底层硬件算力来进一步提高应用层的性能。当下 HTTPS 已经成为公网请求的主要使用方式,全部使用 HTTPS 后由于其要做 TLS 握手,相比 HTTP 势必性能上会有很大损耗。目前随着 CPU 性能的大幅提升,利用 CPU 的 SIMD 机制可以很好的加速 TLS 的性能。该优化方案依赖机器硬件的支持以及 Ingresss Provider 内部实现的支持。
目前,依托 Istio-Envoy 架构的 MSE 云原生网关结合阿里云第七代 ECS 率先完成了 TLS 硬件加速,在不增加用户资源成本的同时大幅度提升 HTTPS 的性能。

Ingress Provider 新选择——MSE 云原生网关
随着云原生技术持续演进,云原生应用微服务化不断深入,Nginx Ingress 在面对复杂路由规则配置、支持多种应用层协议(Dubbo 和 QUIC 等)、服务访问的安全性以及流量的可观测性等问题上略显疲惫。另外,Nignx Ingress 在处理配置更新问题上是通过 Reload 方式来生效配置,在面对大规模长连接的情况下是会出现闪断情况,频繁变更配置可能会造成业务流量有损。
为了解决用户对大规模流量治理的强烈诉求,MSE 云原生网关应运而生,这是阿里云推出的兼容标准 Ingress 规范的下一代网关,具备低成本、安全、高集成和高可用的产品优势。将传统的 WAF 网关、流量网关和微服务网关合并,在降低 50% 资源成本的同时为用户提供了精细化的流量治理能力,支持 ACK 容器服务、Nacos、Eureka、固定地址、FaaS 等多种服务发现方式,支持多种认证登录方式快速构建安全防线,提供全方面、多视角的监控体系,如指标监控、日志分析以及链路追踪,并且支持解析单、多 Kubernetes 集群模式下的标准 Ingress 资源,帮助用户在云原生应用场景下以声明式进行统一流量治理,此外我们引入了 WASM 插件市场满足用户定制化的需求。
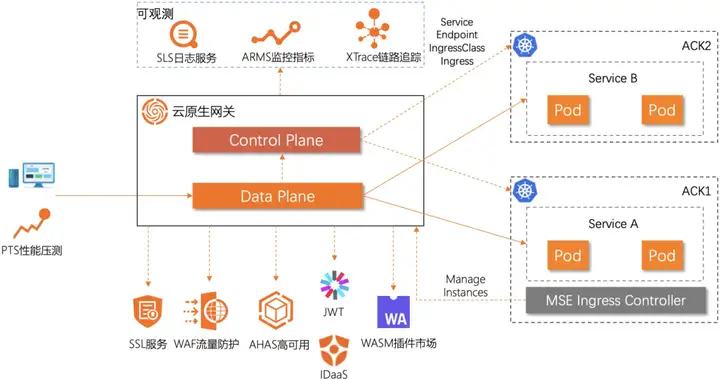
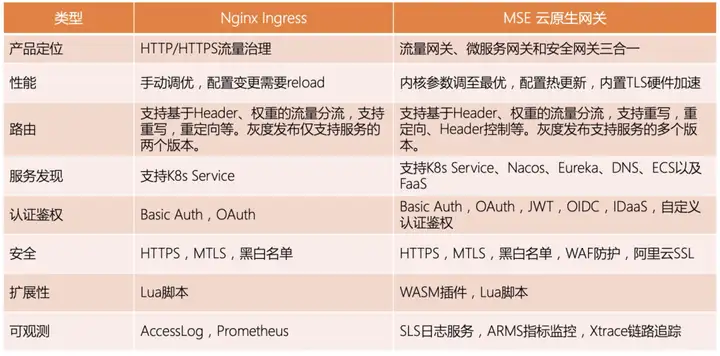
Nginx Ingress VS MSE 云原生网关
以下是 Nginx Ingress 与 MSE 云原生网关的对比总结:
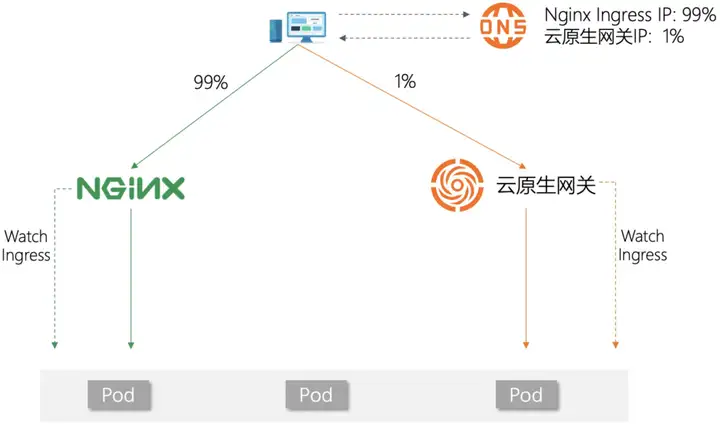
平滑迁移
MSE 云原生网关由阿里云托管,免运维,降成本,功能丰富,且与阿里云周边产品深度集成,下图是从 Nginx Ingress 如何无缝迁移至 MSE 云原生网关,其他 Ingress Provider 也可以参考该方法。
动手实践
接下来,我们会基于阿里云容器服务 ACK 进行 Ingress Provider——MSE 云原生网关相关的实践操作,您可以了解到如何通过 MSE Ingress Controller 来管理集群入口流量。
操作文档地址:https://help.aliyun.com/document_detail/426544.html
前提条件
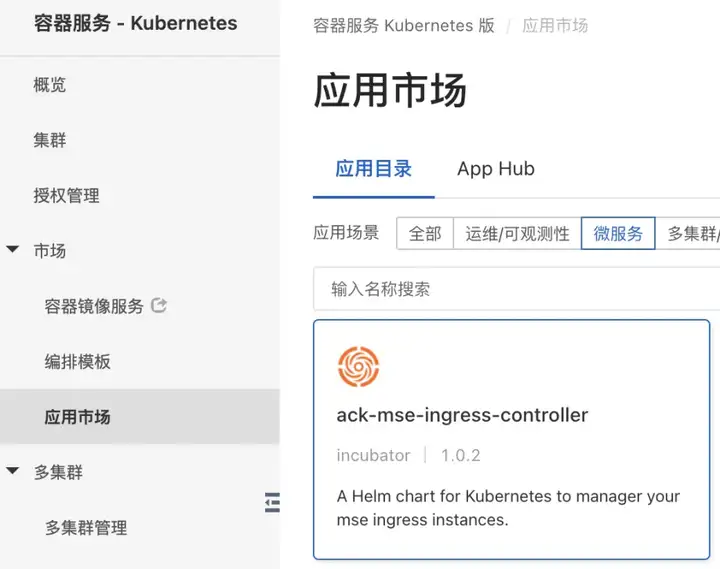
安装 MSE Ingress Controller
我们可以在阿里云容器服务的应用市场中找到 ack-mse-ingress-controller,并且按照组件下方的操作文档完成安装。
通过 CRD 的方式创建 MSE 云原生网关
MseIngressConfig 是由 MSE Ingress Controller 提供的 CRD 资源,MSE Ingress Controller 使用 MseIngressConfig 来管理 MSE 云原生网关实例的生命周期。一个MseIngressConfig 对应一个 MSE 云原生网关实例,如果您需要使用多个 MSE 云原生网关实例,需要创建多个 MseIngressConfig 配置。为了简单展示,我们以一个最小化配置的方式来创建网关。
配置 Kubernetes 标准的 IngressClass 来关联 MseIngressConfig,关联完毕后云原生网关就会开始监听集群中与该 IngressClass 有关的 Ingress 资源。
我们可以通过查看 MseIngressConfig 的 status 来查看当前状态。MseIngressConfig 会按照 Pending > Running > Listening 的状态依次变化。各状态说明如下:
Pending:表示云原生网关正在创建中,需等待 3min 左右。Running:表示云原生网关创建成功,并处于运行状态。Listening:表示云原生处于运行状态,并监听集群中 Ingress 资源。Failed:表示云原生网关处于非法状态,可以查看 Status 字段中 Message 来进一步明确原因。灰度发布实践
假设集群有一个后端服务 httpbin,我们希望在版本升级时可以按照 header 进行灰度验证,如图所示:

首先部署 httpbin v1 和 v2 版本,通过 apply 以下资源到 ACK 集群中:
发布稳定版本 v1 的 Ingress 资源
测试验证
以上就是我们利用 Ingress Annotation 的方式扩展标准 Ingress 支持灰度发布的高阶流量治理能力。
写在最后
MSE – 云原生网关,旨在为用户提供更可靠的、成本更低、效率更高的,符合 Kubernetes Ingress 标准的企业级网关产品,更多发布详情移步直播间观看:https://yqh.aliyun.com/live/detail/28477
本文为阿里云原创内容,未经允许不得转载。















暂无评论内容