
内容介绍
Rust 性能优化总则Rust 性能优化准备工作Rust 性能剖析工具介绍日常 Rust 开发性能优化的技巧总结Rust 编译大小和编译时间优化技巧本次分享将围绕 Rust 性能评估和调优主题,比较系统地介绍 Rust 代码的性能优化经验。先从大的总原则出发,介绍在编写 Rust 过程中应该遵循哪些原则对后续优化有帮助。接下来会分享一些代码优化的方法和技巧,然后介绍可以用于 Rust 代码性能评估的工具,也会包括 Rust专用的一些异步并发测试工具介绍。
引子
Rust 语言天生为并发和安全而设计,并且借鉴了面向过程/面向对象/函数式等语言的特点。Rust 的目标在性能方面对标 C 语言,但在安全和生产力方面则比 C 更胜一筹。
虽说 Rust 语言性能对标 C 语言,但开发者写出的Rust 代码如果不经任何优化,也有可能比 Python 更慢。导致 Rust 代码性能慢的因素有很多种,本文就是尝试来梳理这些情况,并且给出一套方法论和一些工具集,来帮助开发者编写高性能的 Rust 代码。
Rust 性能优化总则
原则一: 不要过早优化性能
“ 过早优化(Premature Optimization)
Premature optimization is the root of all evil. — DonaldKnuth
在 DonaldKnuth 的论文 《 Structured Programming With GoTo Statements 》中,他写道:”程序员浪费了大量的时间去考虑或担心程序中非关键部分的速度,而当考虑到调试和维护时,这些对效率的尝试实际上会产生强烈的负面影响。我们应该忘记这种微小的效率,比如说因为过早优化而浪费的大约97%的时间。然而,我们不应该放弃那关键的 3% 的机会”。
想把代码优化到最佳,需要花很多精力。不应该在开发的时候去想着优化的事情,不需要一步到位。先完成再完美。
但是并非所有优化过早。在编写代码的过程中,优化代码的可读性是你持续要做的。Rust 是一门讲究显式语义的语言,在命名上体现出类型的语义,对于提升可读性非常重要。
原则二: 不要过度优化性能
RustConf 2021 一个演讲就举了一个过度优化例子:
某个用户只是想写一些比 Python 程序性能更好的代码。第一版 Rust 实现的代码已经达到了这个要求,比 Python 代码快 20倍。但是他们花了九牛二虎之力写的第二个 Rust 版本,和第一个版本差距并不大。
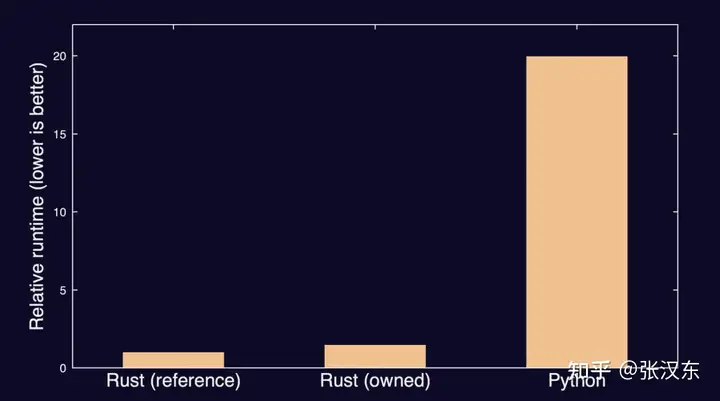
性能够用就好,否则就容易浪费不必要的时间。
原则三: Rust 代码的性能、安全、编译速度和编译大小之间需要权衡
Rust 是同时注重安全和性能的语言。但是在优化性能的同时,是有可能损失安全性的。比如使用 Unsafe Rust 来提升性能,而忽略安全检查在某些调用环境比较安全的地方是允许的,但是并非通用的做法。所以在优化性能之前,要考虑是否要牺牲安全性。
另外 Rust 优化性能的同时,可能会导致编译速度变慢 和 编译文件大小膨胀。这也是需要权衡的地方。
Rust 优化准备工作
在性能优化之前,你还需要做一些准备工作,用于测量你的优化是否有效。
基准测试
第一步是建立一套一致的基准,可以用来确定性能的基线水平,并衡量任何渐进的改进。
“ 参考:
mongodb 的案例中,标准化的`MongoDB` 驱动微基准集[1]在这方面发挥了很好的作用,特别是因为它允许在用其他编程语言编写的MongoDB驱动之间进行比较。由于这些是 “微 “基准,它们还可以很容易地测量单个组件的变化(例如,读与写),这在专注于在特定领域进行改进时是非常有用的。
一旦选择了基准,就应该建立一个稳定的环境,可以用来进行所有的定时测量。确保环境不发生变化,并且在分析时不做其他 “工作”(如浏览猫的图片),这对减少基准测量中的噪音很重要。
推荐工具:
使用 cargo bench 和 `criterion`[2] 来进行基准测试
因为 Rust 自带的基准测试只能用于Nightly Rust ,所以需要使用这个第三方库 criterion 在 Stable Rust 下进行基准测试。
Criterion 会将每次运行的时间记录、分析到一个 HTML 报告中。
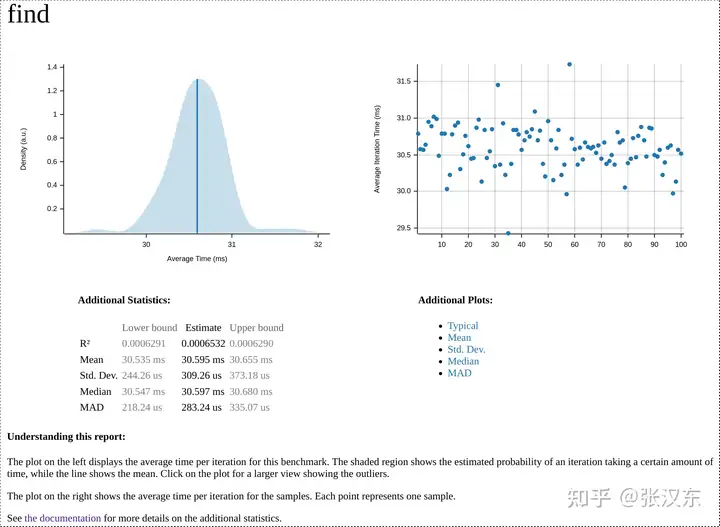
在报告的底部,有两个最近的运行之间的比较,较早的运行(基线)为红色,最近的运行(优化的)为蓝色。这些报告是非常有用的工具,用于可视化由于性能调整而发生的变化,并且它们对于向其他人展示结果特别有用。
它们还可以作为过去性能数据的记录,无需手动记录结果。如果有性能回归的情况,也会得到及时的反映。
压力/负载测试
基准测试是开发过程中对程序性能的一种预判。而项目最终发布之后,还需要在实际环境对其进行真正的负载测试,来判断系统的延时和吞吐量。
常用的负载测试工具基本都可以使用,比如 locust,wrk之类。这里介绍一个 Rust 基金会成员公司的一个用 Rust 实现的开源分布式负载测试工具 :goose[3]。
Goose 每 CPU 核产生的流量至少是 Locust 的 11 倍,对于更复杂的负载测试(例如使用第三方库抓取表单内容的负载测试),收益甚至更大。虽然 Locust 要求您管理分布式负载测试,只是为了在单个服务器上使用多个 CPU 内核,但 Goose 使用单个进程利用所有可用的 CPU 内核,从而大大简化了运行更大负载测试的过程。对代码库的持续改进继续带来新功能和更快的性能。Goose 的扩展性远远优于 Locust,可以有效地利用可用资源来实现其目标。它还支持异步流程,使更多的同步流程能够轻松且一致地从单个服务器上增加数千名用户。
Goose 拥有许多其他负载测试工具所没有的独特调试和日志记录机制[4],简化了负载测试的编写和结果的分析。Goose 还通过对数据的多个简单视图提供了更全面的指标[5],并且可以轻松地确认负载测试在您按比例放大或缩小时按照您的预期执行。它公开了用于分配任务和任务集的算法,对操作的顺序和一致性进行更精细的控制[6],这对于易于重复的测试很重要。
明白高性能系统的标准
在进行性能剖析之前,还应该明白高性能系统的一个标准。
性能 = 产出 / 资源消耗
产出 = 事务次数(比如,qps)和 吞吐的数据量
消耗资源 = cpu时间片,磁盘/网络 I/O 次数、流量 等
而高性能的系统是要求在固定资源消耗之下来提高产出。
对于高性能系统的设计一般遵循两个标准:
最大化地利用资源。使用流水线技术减少程序中任务总耗时。比如 Rust 编译器优化编译时间,也使用了流水线技术来对crate进行并行编译。常见瓶颈类型:
CPU : CPU 占用过高,那么就需要减少计算的开销。CPU 负载过高,那么就需要查看是否线程过多,以及多个线程的切换太过频繁,多线程交互是否有必要。
I/O: 磁盘 IOPS(Input/Output Operations Per Second) 达到了上限。那么需要减少读写次数,提高 cache命中率。IO 带宽(bandwidth) 上限。那么就需要减少磁盘的读写流量,比如使用更紧凑的数据存储格式,更小的读写放大(本来只需要读取100字节,结果触发了好多个page的读写,产生了放大的效果)。I/O 并发达到上限。那么就需要考虑使用 异步I/O。锁、计时器、分页/交换等被阻塞。Rust 性能剖析工具介绍
在做好准备工作之后,就可以开启我们的性能剖析工作了。
性能剖析,就是要发现程序中真正存在的性能瓶颈。而不是你自以为的想象中的性能瓶颈。如果不遵守这点,就会导致过早优化或过度优化。
因为常见的性能瓶颈一般都是两类,CPU 和 I/O 。所以工具也基本面向这两类。
On-CPU 性能剖析
使用 Perf 寻找“热点”
做cpu性能剖析有很多常用的 Linux 命令行工具,比如 linux 命令行工具 perf。它功能强大:它可以检测 CPU 性能计数器、跟踪点、kprobes 和 uprobes(动态跟踪)。
你可以使用 perf 工具对 CPU 进行采样分析。以一个指定的频率对CPU进行采样,进而拿到正在CPU上运行的指令乃至整个函数调用栈的快照,最后对采样的数据分析。比如说在100次采样中有20次在运行A指令或者A函数,那么perf就会认为A函数的CPU使用率为20%。
可以在 Cargo.toml 中加入:
然后执行:
就可以看到报告了。
火焰图工具
但我们 Rust 程序中要通过`flamegraph` [7]crate,来生成 火焰图(flamegraph),它可以与cargo一起工作,非常方便。
因为火焰图有助于阅读源码,它以可视化的图案非常明确地展示调用栈之间的关系。火焰图可以让开发者从整体上看出各个线程的开销比例和子函数占有的比例,指引我们从整体上找到优化的优先级。
火焰图中,在被测量的执行过程中调用的每个函数会被表示为一个矩形,每个调用栈被表示为一个矩形栈。一个给定的矩形的宽度与在该函数中花费的时间成正比,更宽的矩形意味着更多的时间。火焰图对于识别程序中的慢速部分非常有用,因为它们可以让你快速识别代码库中哪些部分花费的时间不成比例。
用 Mongodb 调优的示例来说:
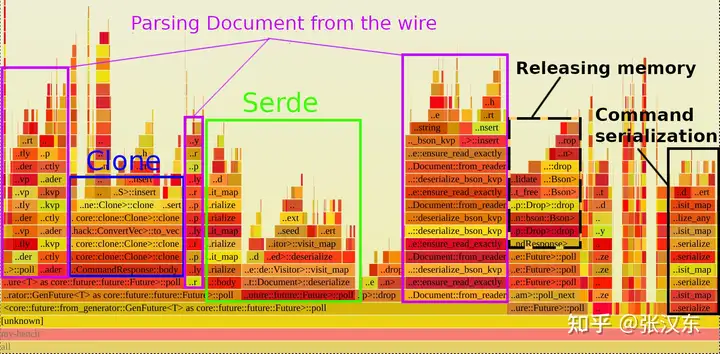
火焰图中的栈从底部开始,随着调用栈的加深而向上移动(左右无所谓),通常这是开始阅读它们的最佳方式。看一下上面火焰图的底部,最宽的矩形是Future::poll,但这并不是因为Rust 的 Future 超级慢,而是因为每个.await都涉及轮询(poll)Future。考虑到这一点,我们可以跳过任何轮询矩形,直到我们在mongodb中看到我们关心的信息的函数。
蓝色方块包含了调用CommandResponse::body所花费的时间,它显示几乎所有的时间都花在了clone()上。各个紫色矩形对应的是将BSON(MongoDB使用的二进制格式)解析到Document中所花费的时间,绿色矩形对应的是Document的serde::Deserialize实现中所花费的时间。最后,黑色虚线矩形对应的是释放内存的时间,黑色实线对应的是将命令序列化为BSON的时间。
所以从火焰图中反映出性能瓶颈在于:
Clone 过多。序列化 bson 耗费更多时间修复完这些性能瓶颈之后,再使用基准测试测试一次。
如果可能的话,再使用 goose 这样的压测工具进行一次负载测试更好。
perf 适合测试 Rust 异步代码
对于异步 Rust 程序而言,火焰图的效果可能并不是很好,因为异步调度器和执行器几乎会出现在火焰图中每一块地方,看不出瓶颈所在。这个时候使用 perf 工具会更加清晰。
检查内存泄露和不必要的内存分配
可以使用 Valgrind[8] 工具来检查程序是否存在内存泄露,或者在关键的调用路径上存在不必要的内存分配。
不仅仅要考察堆分配,也需要考虑栈上的分配,特别是异步操作时。
有一个非常有用的 Rust 编译标志(仅在 Rust nightly 中可用)来验证数据结构有多大及其缓存对齐。
除了通常的 Cargo 输出之外,包括异步 Future 在内的每个数据结构都以相应的大小和缓存对齐方式打印出来。比如:
Rust 异步编程非常依赖栈空间,异步运行时和库需要把所有东西放到栈上来保证执行的正确性。如果你的异步程序占用了过多的栈空间,可以考虑将其进行优化为 平衡的同步和异步代码组合,把特定的异步代码隔离出来也是一种优化手段。
其他性能剖析/监控工具
如果允许,可以使用 英特尔出品的 VTune [9] 工具进行 CPU 性能剖析。
或者使用在线的性能监控平台,比如 Logrocket[10],支持 Rust 程序,可以监控应用程序的性能,报告客户端 CPU 负载、客户端内存使用等指标。
也可以使用开源的链路追踪工具来监控你自己的 Rust 项目:使用 OpenTelemetry 标准。OpenTelemetry 也支持 Rust 。
opentelemetry是一款数据收集中间件。我们可以使用它来生成,收集和导出监测数据(Metrics,Logs and traces),这些数据可供支持OpenTelemetry的中间件存储,查询和显示,用以实现数据观测,性能分析,系统监控,服务告警等能力。
PingCAP 也开源了一款高性能的 tracing 库 : minitrace-rust[11]
Off-CPU 性能剖析
Off-CPU 是指在 I/O、锁、计时器、分页/交换等被阻塞的同时等待的时间。
Off-CPU 的性能剖析通常可以在程序运行过程中进行采用链路跟踪来进行分析。
还有就是使用 offcpu 火焰图进行可视化观察。
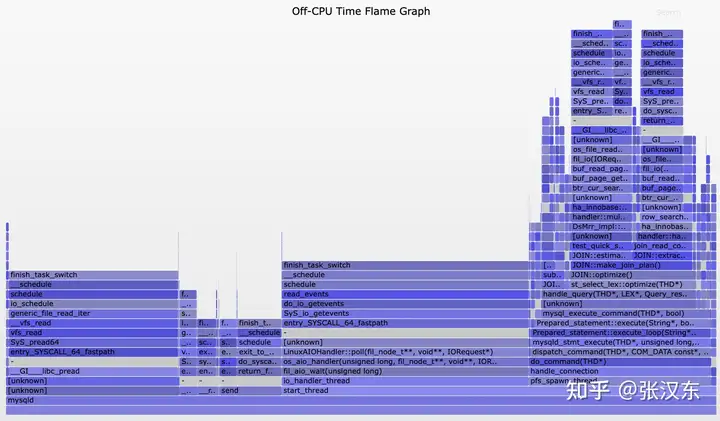
这里推荐的工具是 eBPF的前端工具包bcc[12]中的offcputime-bpfcc工具。
这个工具的原理是在每一次内核调用finish_task_switch()函数完成任务切换的时候记录上一个进程被调度离开CPU的时间戳和当前进程被调度到CPU的时间戳,那么一个进程离开CPU到下一次进入CPU的时间差即为Off-CPU的时间。
比如这里一段代码:
程序中一共有两种会导致进程被调度出CPU的任务,一个是test1()函数中的sleep(),一个是在test2()函数中的读文件操作。
这里需要使用debug编译,因为offcputime-bpfcc依赖于frame pointer来进行栈展开,所以我们需要开启RUSTFLAGS=”-C force-frame-pointers=yes”的编译选项以便打印出用户态的函数栈。我们使用如下的命令获取Off-CPU的分析数据。
然后使用 火焰图工具将其生成 off-cpu 火焰图:
得到下面火焰图:

与On-CPU的火焰图相同,纵轴代表了函数调用栈,横轴代表了Off-CPU时间的比例,跨度越大代表Off-CPU的时间越长。
其他适合 Rust 性能剖析的工具介绍
除了 perf 和 火焰图 工具,下面还有一些 Rust 程序适用的工具。
Hotspot[13]和Firefox Profiler[14]是查看perf记录的数据的好工具。Cachegrind[15]和Callgrind[16]给出了全局的、每个函数的、每个源线的指令数以及模拟的缓存和分支预测数据。DHAT[17]可以很好的找到代码中哪些部分会造成大量的分配,并对峰值内存使用情况进行深入了解。heaptrack[18]是另一个堆分析工具。`counts`[19]支持即席(Ad Hoc)剖析,它将eprintln!语句的使用与基于频率的后处理结合起来,这对于了解代码中特定领域的部分内容很有帮助。Coz[20]执行因果分析以衡量优化潜力。它通过coz-rs[21]支持Rust。因果分析技术可以找到程序的瓶颈并显示对其进行优化的效果。日常 Rust 开发性能优化技巧总结
虽然我们需要通过完善的性能测试方法来剖析系统中存在的瓶颈,保证不会过早优化和过度优化。但是在日常编码过程中,Rust 社区内也总结出来一些优化技巧来供参考:
1. 对于只被调用一次的函数可能并不需要进行优化。
比如读取配置文件,这种多慢都没有关系。
不要只优化程序中最慢的函数,要优化占用大部分运行时间的函数。
在一个被调用 1000 次的函数上得到 2 毫秒的改进,那比在一个被调用一次的函数上获得 1 秒的改进要好。
2. 优先改进你的算法
很多时候性能不佳,很可能是由于算法不佳而不是实现不佳。请检查你的代码中循环的使用,只需尝试尽可能少的循环。
记住每次使用collect必须至少会迭代整个集合一次,所以最好只 collect 一次。警惕你使用的标准库方法和第三方库方法内部实现中隐藏的循环。3. 要充分理解 Rust 中数据结构的内存布局
要学会区分 Rust 中数据类型的内存布局,它们在栈上和堆上如何分配的。
比如 String,Vec,HashMap和Box<Trait>/Box<[T]>所有分配都在堆上。
在栈上分配的数据,移动的时候只能是 按位复制的方式。所以即便内存是在栈上分配,也要考虑这个 Copy 的成本。
堆上的数据,要尽可能地避免深拷贝(显式 Clone) 。
并且要尽可能地缓存数据,而避免频繁的内存分配发生。比如可以使用诸如 slab 之类的第三方库,可以合理复用内存。
4. 避免 Box<Trait> 动态分发
创建 trait 对象的规范方法是Box<Trait>,但大多数代码都可以使用&mut Trait,它也具有动态分派但节省了分配。如果您绝对需要所有权,请使用Box,但大多数用例都可以使用&Trait或&mut Trait。
有些场景也可以使用 Enum 来代替 trait 对象。参见 `enum_dispatch`[22]。
5. 使用基于栈的可变长度数据类型
定长度的数据类型可以简单地存储在堆栈上,但对于动态大小的数据,它并不是那么简单。但是,`smallvec`[23], `smallstring`[24]和`tendril`[25]都是可变长度数据类型,允许在栈上存储少量元素。像smallvec这样的库非常适合缓存局部性,可以减少分配。
6. 合理使用断言避免数组越界检查
Safe Rust 会被编译器自动塞入数组越界检查,比如下面代码:
可以通过编译输出 MIR 看到,编译器会给数组索引访问插入断言检查:
有几个数组索引访问就会被插入几次,上面的代码会被插入 6 次,这极大影响性能。
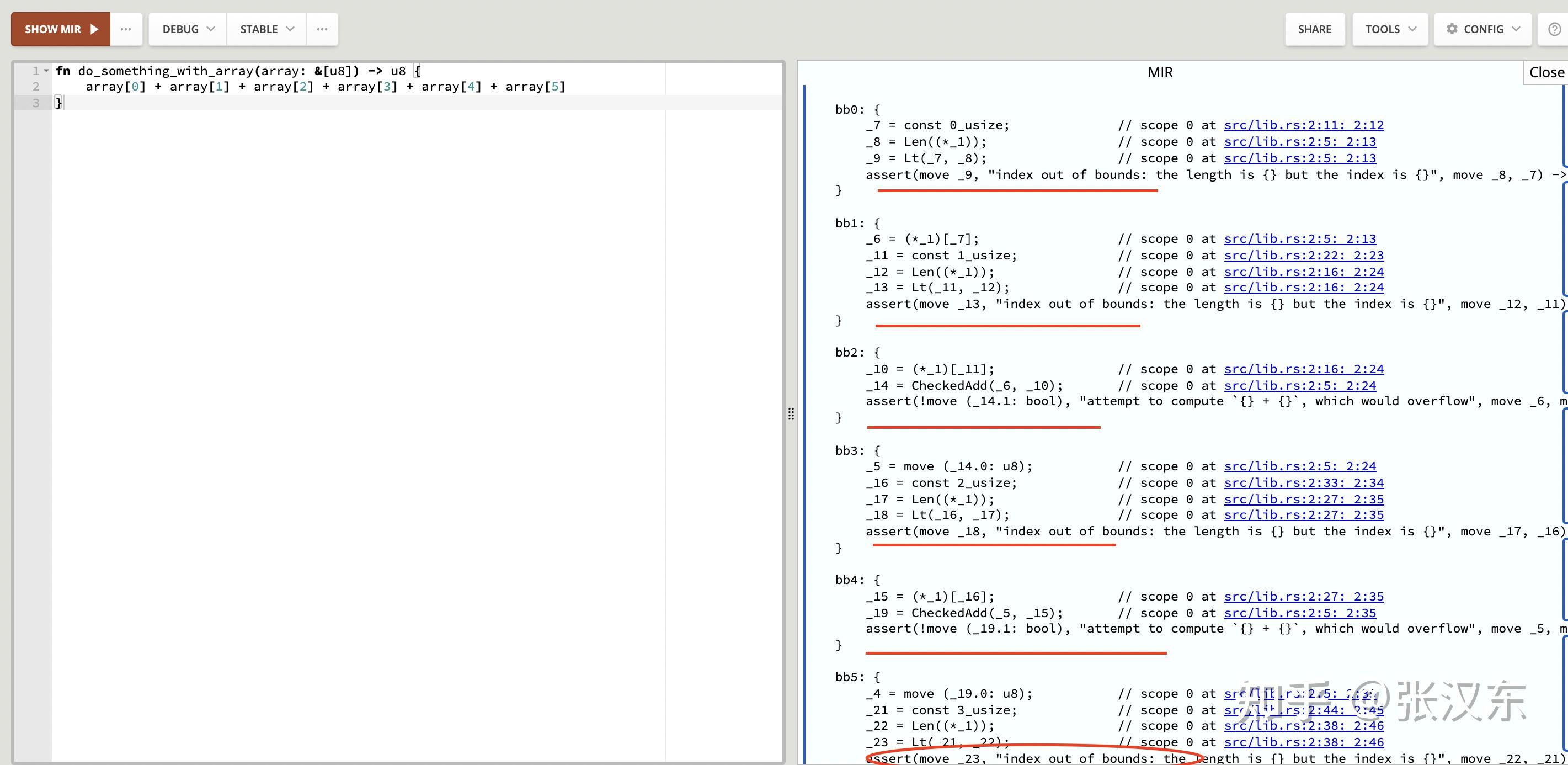
所以我们可以手工插入一次断言检查,就可以消除编译器的自动插入。
这一条也是可以举一反三的,比如 Rust 也会为普通的加法操作添加防止计算溢出的断言,但是你如何手工使用了 wrapped_add 之类的方法,那就可以避免编译器自动插入这类断言。
7. 使用链接时优化(LTO)
链接时优化允许编译器跨 crate 进行内联,但是这样做的代价是减慢编译时间。但我认为,编译时间如何能换取性能提升,那么这个时间值得牺牲。
8. 不要使用 #[inline(always)]
Rust 编译器自身的优化可以计算出何时需要内联一些函数,不需要你手工明确指定。除非这个函数调用十分频繁。
因为这种显式的指定会导致编译大小的膨胀,如果你的硬件资源不受限可能不太重要。但是对于资源受限的环境,比如嵌入式,则需要进行权衡。
对于一些小的函数,如果没有使用 LTO,但是需要跨 crate 内联的话,也可以显式指定 #[inline]。
9. 避免显式 Clone
尽可能地使用引用,避免过多的 Clone 。因为Clone 可能伴随内存分配。
10. 使用 Unsafe 方法消除一些不必要的安全检查
在 Rust 标准库中,你可以看到很多 _unchecked后缀的方法。
比如 String::from_utf8 和 String::from_utf8_unchecked,是一对 Safe 和 Unsafe 的方法。
一般情况下,应该使用 String::from_utf8 将 u8序列转换为合法的字符串,这个方法对 u8序列进行了合法 utf8编码的检查。但是这个检查也会有一定开销。
如果开发者能确保调用环境的 u8序列来源是完全合法的 utf8 编码,那么这个安全检查就完全可以忽略。此时就可以使用 String::from_utf8_unchecked 来替换 String::from_utf8 用来提升性能。
11. 并发/并行化你的程序
用 Rust 写多线程和异步并发程序是非常便利的。
推荐的库有很多:
rayon[26],并行迭代器crossbeam[27] / flume[28],多线程channel/ 无锁并发结构Tokio[29] ,高性能异步运行时 loom[30], Tokio 提供的并发代码测试工具,支持 C11 内存模型。console[31],Tokio 提供的 Rust 异步诊断和调试工具,可以将其视为异步代码的 Clippy。通过监控应用程序中任务的运行时操作,可以检测可能暗示错误或性能问题的行为模式,并突出显示它们以供用户分析。
跨平台 SIMD,并行化你的计算。12. 并发程序中,合理使用锁,或替换无锁数据结构
在某些场景中,可能读并发访问要比写并发更频繁,那么可以用 读写锁来替换互斥锁。另外,使用第三方库 parking_lot 中定义的并发锁来代替标准库中的锁。
或者合理选择无锁数据结构来替换用锁来同步的数据结构,并不是说无锁一定比锁同步性能更好,也是需要看场景和选择高质量的第三方实现。
13. 使用 Clippy
使用 Clippy 工具对代码进行静态分析,它可以针对性能改进提供一些建议。
关于 Clippy 性能改进 lint 可以在这里找到:https://rust-lang.github.io/rust-clippy/master/index.html[32]
同样可以遵循 Rust 编码规范 [33] 中的一些规范,也会包括 Clippy 的一些建议。如果你有什么性能优化的小技巧,欢迎提交贡献。
编译大小和编译时间的优化总结
1. 优化编译大小
设置 codegen-units=1 ,codegen-units 叫做代码生成单元,Rust 编译器会把crate 生成的 LLVMIR进行分割,默认分割为16个单元,每个单元就叫 codegen-units,如果分割的太多,就不利于 Rust编译器使用内联优化一些函数调用,分割单元越大,才越容易判断需要内联的地方。但是这也有可能增大编译文件大小,需要大小和性能间寻找平衡。设置panic=abort。可以缩减编译文件的大小。设置编译优化等级为 z,意为最小二进制体积。编译器的优化级别对应的是LLVM函数内联的阈值,z 对应的是 25,而 级别 3则对应 275 。评估代码中泛型和宏的使用,是否可以精简其他参考:https://github.com/johnthagen/min-sized-rust2. 优化编译时间的一些技巧
使用 cargo check 代替 cargo build
使用最新 Rust 工具链
使用 Rust Analyzer 而不是 Rust Language Server (RLS)
删除未使用的依赖项
替换依赖过多的第三方库
使用 workspace,将项目拆分为多个crate,方便并行编译
将针对模块的测试单独拆分为一个测试文件
将所有集成测试组合在一个文件中
禁止 crate 依赖未使用功能
使用 ssd或Ramdisk(虚拟内存盘) 进行编译
使用 sccache[34] 缓存依赖项
切换到更快的链接器:mold[35] (Linux)/ zld[36] (MacOS) / (Windows),可以使用以下命令检查链接所花时间:
cargo clean
cargo +nightly rustc –bin
Rust 针对 MacOS 用户也提升了增量编译性能,在 Cargo.toml 中进行以下配置:
[profile.dev]
split-debuginfo = “unpacked”
调整更多 Codegen 选项/编译器标志。这是完整的 codegen 选项列表[37] 。为了获得灵感,这里是bevy 的用于更快编译的配置[38]。
剖析文件编译时间。使用 `cargo rustc — -Zself-profile`[39]生成的跟踪文件可以使用火焰图或 Chromium 分析器进行可视化。还有一个`cargo -Z timings`[40]功能可以提供有关每个编译步骤需要多长时间的一些信息,并随着时间的推移跟踪并发信息。
避免过程宏 Crates,主要是因为使用了 syn 。过程宏是 Rust 开发的热点:它们会消耗 CPU 周期,因此请谨慎使用。serde 库中包含了过程宏,它在很多地方都用到,所以需要注意是否一定需要serde 进行序列化和反序列化。
避免过多的泛型。过多的泛型单态化也会导致编译时间增加。
提升你的硬件,或者在云端(比如http://Gitpod.io[41],可免费使用 16 核 Intel Xeon 2.80GHz,60GB RAM的主机)使用更好的硬件环境进行编译。
下载所有的依赖 crate。编译过程中有很大一部分时间用于下载,提前下载好crate是有帮助的。参考 https://github.com/the-lean-crate/criner使用 docker 进行编译。`cargo-chef`[42]可用于充分利用 Docker 层缓存,从而大大加快 Rust 项目的 Docker 构建。
超频 cpu ?谨慎。
优化 CI 构建速度。参考 https://matklad.github.io/2021/09/04/fast-rust-builds.html。
你自己开发 crate 的时候尽量保持精简,利人利己。
参考资料
[1]
MongoDB 驱动微基准集: https://github.com/mongodb/specifications/blob/master/source/benchmarking/benchmarking.rst
[2]
criterion: https://crates.io/crates/criterion
[3]
goose: https://github.com/tag1consulting/goose
[4]
调试和日志记录机制: https://book.goose.rs/logging/overview.html
[5]
全面的指标: https://book.goose.rs/getting-started/metrics.html
[6]
更精细的控制: https://book.goose.rs/config/scheduler.html
[7]
flamegraph : https://crates.io/crates/flamegraph
[8]
Valgrind: https://www.valgrind.org/
[9]
VTune : https://www.intel.com/content/www/us/en/develop/documentation/vtune-help/top.html
[10]
Logrocket: https://logrocket.com/
[11]
minitrace-rust: https://github.com/tikv/minitrace-rust
[12]
bcc: https://github.com/iovisor/bcc
[13]
Hotspot: https://github.com/KDAB/hotspot
[14]
Firefox Profiler: https://profiler.firefox.com/
[15]
Cachegrind: https://www.valgrind.org/docs/manual/cg-manual.html
[16]
Callgrind: https://www.valgrind.org/docs/manual/cl-manual.html
[17]
DHAT: https://www.valgrind.org/docs/manual/dh-manual.html
[18]
heaptrack: https://github.com/KDE/heaptrack
[19]
counts: https://github.com/nnethercote/counts/
[20]
Coz: https://github.com/plasma-umass/coz
[21]
coz-rs: https://github.com/plasma-umass/coz/tree/master/rust
[22]
enum_dispatch: https://docs.rs/enum_dispatch/latest/enum_dispatch/
[23]
smallvec: https://github.com/servo/rust-smallvec
[24]
smallstring: https://github.com/jFransham/smallstring
[25]
tendril: https://github.com/servo/tendril
[26]
rayon: https://github.com/rayon-rs/rayon
[27]
crossbeam: https://docs.rs/crossbeam/latest/crossbeam/
[28]
flume: https://github.com/zesterer/flume
[29]
Tokio: https://github.com/tokio-rs/tokio
[30]
loom: https://github.com/tokio-rs/loom
[31]
console: https://github.com/tokio-rs/console
[32]
https://rust-lang.github.io/rust-clippy/master/index.html: https://rust-lang.github.io/rust-clippy/master/index.html
[33]
Rust 编码规范 : https://rust-coding-guidelines.github.io/rust-coding-guidelines-zh/
[34]
sccache: https://github.com/mozilla/sccache
[35]
mold: https://github.com/rui314/mold
[36]
zld: https://github.com/michaeleisel/zld
[37]
完整的 codegen 选项列表: https://doc.rust-lang.org/rustc/codegen-options
[38]
bevy 的用于更快编译的配置: https://github.com/bevyengine/bevy/blob/3a2a68852c0a1298c0678a47adc59adebe259a6f/.cargo/config_fast_builds
[39]
cargo rustc — -Zself-profile: https://blog.rust-lang.org/inside-rust/2020/02/25/intro-rustc-self-profile.html#profiling-the-compiler
[40]
cargo -Z timings: https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#timings
[41]
Gitpod.io: https://gitpod.io/
[42]
cargo-chef: https://www.lpalmieri.com/posts/fast-rust-docker-builds/


















暂无评论内容