
Ben,多本数据科学畅销书作家,先后在亚信、德勤、百度等企业从事电信、金融行业数据挖掘工作。
配套学习教程:数据科学实战:Python篇 https://edu.hellobi.com/course/270推荐系统近年来非常欢迎并应用于各行业。它是一种信息过滤系统,用于了解用户对物品的偏好。
4.1 推荐系统概述
推荐系统可以将商品推荐给用户,在互联网领域有着广泛运用。推荐系统可以根据应用、设计目的、使用的数据和推荐方法的不同进行分类。
1.基于应用,推荐系统可以分为电子商务推荐、社交好友推荐、搜索引擎推荐、信息内容推荐等。
2.基于设计目的,推荐系统可以分为协同过滤、内容的推荐、知识的推荐、混合推荐。
3.基于使用的数据的推荐以及推荐系统可以分为基于用户行为数据的推荐、基于用户标签的推荐、基于社交网络数据、基于上下文信息(时间上下文、地点上下文等)的推荐。
4.基于推荐方法,推荐系统可以分为基于用户需求的推荐、基于购物篮的推荐、基于用户商品的推荐、基于用户相似性的推荐、基于市场细分的推荐等。
(1)基于用户需求的推荐
这类推荐的算法主要是分类模型,比如Logistic回归、神经网络等。这类推荐根据用户的属性、行为数据对用户的需求进行建模,进而预测用户的(购买等)行为,由于其需要训练数据,因此只适用于有销售记录的产品,而且这类算法的建模过程比较复杂。
(2)基于购物篮的推荐
这类推荐的算法的典型代表为关联规则,其用于发现不同商品被同时购买的规则,从而反映了顾客的需求模式,其适用于有销售记录的商品,可以向老客户推荐相关商品。
(3)基于用户/商品的推荐
基于用户(User)和商品(Item)的推荐统称为协同过滤,该方法通过对用户/商品购买或评价矩阵的转换,获取用户与用户或商品与商品的相似性。一般用户较多的电商会使用基于商品的推荐,而社交网站更偏爱基于用户的推荐。这类方法也会使用到奇异值分解算法进行稀疏矩阵的存储。
(4)基于用户相似性的推荐
这类推荐是以用户之间的相似性为基础,典型算法就是各种相似度的计算、KNN算法以及基于用户的协同过滤,其可以找出有相似行为的用户并向他们推荐产品。其一般适用于有过购买行为的老用户,而且推荐的产品也不能是全新的产品。
(5)基于市场细分的推荐
市场细分以k-means算法为代表,相似的用户具有相似的需求,其可以适用于全新的产品,全新的用户,但是模型效果只能事后检验。
本节会主要介绍基于内容与基于用户相似性的推荐方法。
4.2 计算相似度
1.收集用户偏好
对于某种商品,用户对于该商品的评分、投票、某文章或微博的转发、点击量、页面停留的时间等可以反映用户偏好。评分、投票、转发等可以比较精确地得到用户对于该商品的偏好信息;而点击量、页面停留则含有噪声,需要对这类数据事先进行处理;对于用户评论,则需要进行文本分析来得知用户的情感倾向,从而可以一定程度地反映用户的偏好。
2.相似度的度量
相似度的度量有很多方法,这里介绍欧氏距离(Euclidean),皮尔森相似度(Pearson)、余弦相似度(Cosine)与杰卡德距离(Jaccard)。
(1)欧氏距离,即平面几何中两点间距离的计算公式::

欧氏距离值越大代表两个变量的相似程度越低。例如在下图中,Ma和Yang无疑是最相似的,其次是Zhao和Li,而Wang与Qi则相差较大。

(2)皮尔森相似度,即皮尔森相关系数,值域为-1~1,一般用于衡量两个连续随机变量的线性关系,其计算公式如下所示。

皮尔森相似度侧重于两个随机变量的线性关系。线性关系越强,相似程度越高。
使用皮尔森相关系数进行相似度衡量时,其优点在于有助于克服所谓的“夸大评价”现象对结果的影响,例如下图中,虽然Li对电影的评价比Ma更为极端(更容易给出高分和低分),但这个坐标系中的点相当靠近拟合曲线(图中虚线),可以认为两人品味偏好比较接近。

(3)杰卡德(Jaccard)相似度用于衡量两个集合的相似情况,即两个集合的交集元素的个数除以并集元素的个数。
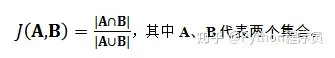
杰卡德相似度会对集合中的每个评过分的项进行计数,这不同于其它计算公式——例如欧式距离或皮尔森相关系数要求提取出两个用户均评过分的商品才能进行计算。如果两个用户评过分的商品数量很不平衡(例如一个评了100项,而另一个仅评了20项),则杰卡德相似度可能与实际产生较大偏差。此外,杰卡德相似度仅考虑评过分的商品的重叠度,忽略了实际的评分数值大小,也可能会有问题。例如下面的数据集:
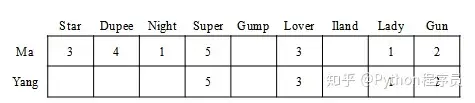
可以看到,Ma和Yang在4项重叠商品上的评分完全一致,可以认为他们十分相似,但是Ma总共对7项产品进行了评分,Yang则仅评了重叠的4项,因此杰卡德相似度为4/7,这可能与实际情况偏离较大。
(4)余弦相似度,即计算两个向量的点积除以两个向量的模。
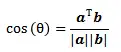
余弦相似度被广泛运用于文档的相似度计算,它与皮尔森相关系数有着同样的优良特性——可以避免“夸大评价”。这是因为余弦相似度仅考虑两个向量的夹角大小,而忽略了向量的长度,示例如下:

可以看到Li比Ma更容易对商品给出高分,但相对来说,他们都更喜欢Lovers商品胜过Superman,可以说他们的偏好是很相似的(对应的夹角余弦值很接近于1)。
实际上,余弦相似度可以视作是去中心化后的数据的皮尔森相关系数,这可以从他们的计算公式推理得到。
3.找到相似的用户
在得到每个用户的偏好后,就可以进一步分析用户之间的相似情况。以一个超市数据为例,这个超市收集了N个用户购买M个商品后的评价记录,数据如表15-3所示。
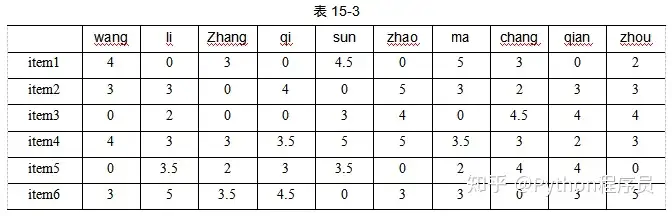
其中,列表示某用户,行表示某商品,单元格内的分数代表用户对商品的偏好(评分)。现在用户wang对6种商品评分为4、3、0、4、0、3,需要找出与该用户最相似的前三个用户。
对于相似度计算方法,这里以欧氏距离、皮尔森距离、杰卡德距离、余弦距离为例对相似度进行计算。可以看到在欧氏距离下,用户zhang、用户ma、用户zhou与用户wang的距离最近即他们之间相似度比较高。在皮尔森相似度下,用户wang与用户ma、用户zhang、sun比较相似;在杰卡德相似度下,用户wang与用户ma、用户zhou比较相似;在余弦相似度下,用户wang与用户ma、用户zhang和用户zhou相似度较高。
四种相似度计算方式的结果比较相似。
通过相似度的计算,就找到了相似的用户,从而可以进行下一步的推荐。除了计算用户相似度,数据集同样也可以使用相同的方法计算商品的相似度,以item1为例,计算出的相似情况如表15-4所示。
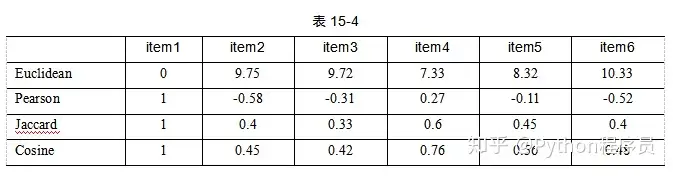
从表中可以看出,四种相似度在计算商品相似度时,最相似的商品计算出来也都非常一致。
4.3 协同过滤
1.基于用户的协同过滤
基于用户的协同过滤的基本思想非常简单,根据用户对商品的偏好找到相似的邻近用户,然后将邻近用户喜欢的商品推荐给当前用户。
协同过滤在计算上,就是将一个用户对所有商品的偏好作为一个向量用以计算用户之间的相似度,找到K个相似用户,然后根据相似用户的相似度权重以及他们对商品的偏好,预测当前用户没有偏好的未涉及商品,计算得到一个排序的物品列表作为推荐。
沿用之前的数据,对于新用户zeng,其对6个商品的打分为4、1、0、0、0、3,通过余弦距离计算出用户zeng与其他用户的距离从小到大排序表15-5所示。

取前三个用户为邻近用户,即用户ma、用户wang、用户zhang。此时以每个邻近用户的相似度为权重,以相应物品的评分为值,进行相乘,计算出商品推荐打分。例如,对于zeng未打分而其他用户打过分的商品item4,其商品推荐打分计算为:
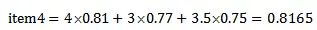
同理,可以计算出所有商品的推荐打分,以矩阵形式写出,如图15-16所示。
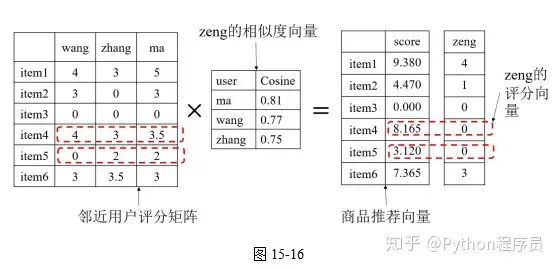
显然,根据计算出的商品推荐打分向量,应该向用户zeng首先推荐item4,然后推荐item5。
2.基于商品的协同过滤
基于商品的协同过滤和基于用户的原理类似,只是在计算好友时采用商品本身,而不是从用户的角度,即基于用户对商品的偏好找到相似的商品,然后根据用户的历史偏好,推荐相似的商品给他。??
从计算的角度看,就是将所有用户对某个商品的偏好作为一个向量用以计算商品之间的相似度,得到某商品的相似商品后,根据用户历史的偏好预测当前用户还没有表示偏好的商品,计算得到一个排序的商品列表作为推荐。
对于新用户zeng,其对6个商品的打分为4、1、0、0、0、3,计算出6个商品的余弦距离矩阵,如表15-6所示。
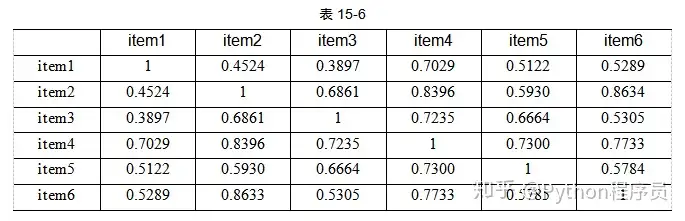
这个矩阵便是商品的相似度矩阵,基于商品的协同过滤会以商品的相似度为权重,在本例中以用户zeng的商品打分为基础,计算商品推荐打分,例如用户zeng未打分的商品item3,其计算公式应为
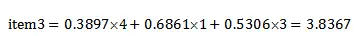
同理,可以计算出所有商品的推荐打分,以矩阵形式写出,如图15-17所示。
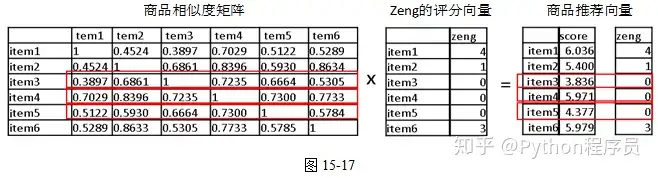
因此,基于商品的协同过滤会依次向用户zeng推荐商品item4、item5和item3。
3.两种协同过滤的比较
对于电子商务,用户数量一般远超过商品数量,此时基于商品的协同过滤计算复杂度较低。
在非社交网络的网站中,内容内在的联系是很重要的推荐原则,它比基于相似用户的协同过滤更加有效。比如在购书网站上,当你在看一本书时,推荐引擎会向你推荐相关的书籍,这个推荐的重要性远远超过了网站首页对该用户的综合推荐。可以看到在这种情况下,基于商品的协同过滤成为引导用户浏览的重要手段。基于商品的协同过滤算法,是目前电子商务最广泛使用的推荐算法。
基于商品的协同过滤的缺点是倾向于推荐热门商品,在长尾推荐方面不够强大;从用户体验的角度上看,缺少惊喜的体验。
在社交网络或者新闻媒体类网站中,基于用户的协同过滤更为适用,一方面这类网站每天都会产生大量的新内容;另一方面,这类协同过滤加上社会网络信息,可以增加用户对推荐解释的信服程度。但基于用户的协同过滤要求用户有比较多的好友,因此更适用于社交属性站点。
4.4 基于商品的协同过滤:电影评分案例
1.背景
某电影点评网站主要提供的产品服务包括电影介绍、电影排行、网友对电影打分、网友影评、影讯及购票、用户在看、想看、看过的电影。
用户在完成注册后,可以浏览网站的电影介绍、电影排行榜,选择自己喜欢的分类以及找到自己想看的电影并将其设置为“想看”,还可以对自己已经看过的电影打分、写影评。
(1)通过以上描述,我们可以看出这个网站提供个性化推荐电影服务,其核心包括以下几点。
①网站提供所有电影信息,吸引用户浏览。
②网站收集用户行为,包括浏览行为、评分行为、评论行为,从而推测用户的爱好。
③网站帮助用户找到感兴趣但还没有看过的电影列表。
④网站通过海量数据的积累,预测未来新片的市场影响和票房。
由此可见,电影推荐将成为这个网站的核心功能。
(2)在构建推荐系统时,需要考虑以下几点:
①推荐算法选型:基于商品的协同过滤算法ItemCF,并行实现。
②数据量:是否需要基于大数据架构,支持GB、TB、PB级数据量。
③算法检验:可以通过准确率、召回率、覆盖率、流行度等指标评判。
④结果解读:通过ItemCF的定义,合理给出结果解释。
2.数据集描述
本案例的数据集是“商品—用户”倒排表,如图15-18所示(数据是人工建立的,并且设定了对应的数据类型)。
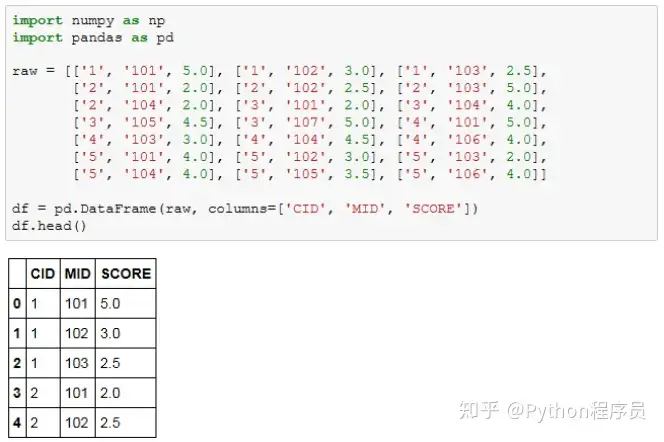
图15-18
CID表示用户的ID标识,MID表示电影,score表示相应用户对电影的打分,接下来可以使用协同过滤的方式对用户进行产品推荐。
3.在Python中实现基于商品的协同过滤
原始数据是在事务型数据库中常见的形式,为了计算各商品间的相似度,需要将其进行转换,生成评分矩阵如下:
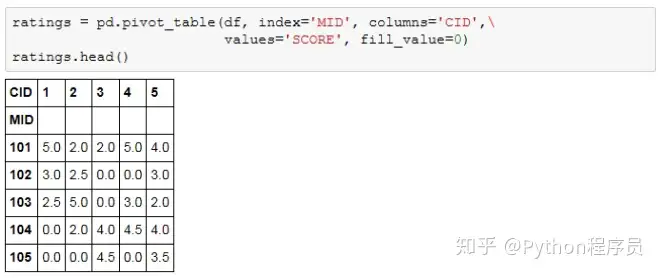
转换后的行是商品,每列是用户对应的评分,在此表的基础上可以计算不同商品间的相似度,生成相似度矩阵,可以使用sklearn.neighbors中的DistanceMetric类进行计算,可以得到样本间的距离矩阵,然后通过简单换算就可以得到相似度矩阵。距离矩阵计算方法可参考scikit-learn官方文档。
①使用jaccard相似度
Scikit-learn提供了jaccard距离矩阵的计算方法,为了得到jaccard相似度只需要简单的换算一下即可,代码如下:
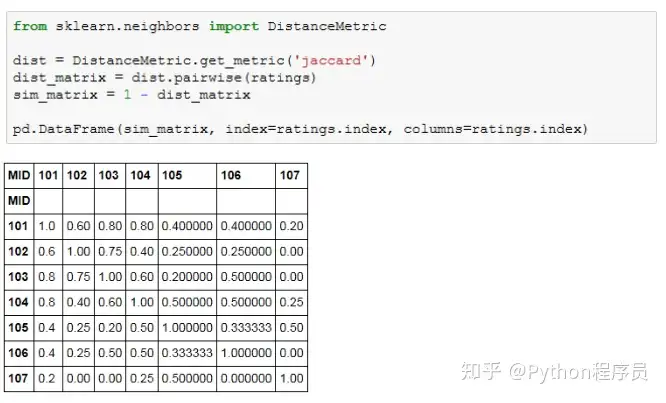
上述代码中,DistanceMetrics计算的是各个商品间的jaccard距离,要将其换算为jaccard相似度,只需要用1减去jaccard距离。如果采用其它距离公式,也同样需要先换算成相似度,可以认为相似度与距离是反比例关系,换算时用1减或者取倒数都是常用的方法。
在相似度矩阵的基础上可以对用户进行推荐,根据前一节对于协同过略算法的描述,可以发现将相似度矩阵与待推荐的用户评分向量进行点乘,即可获得该用户在未评分商品上的预测分,示例如下:

因此,在Python当中执行如下:

我们以第三个用户为例进行推荐,将其评分向量提取出来与相似度矩阵进行点乘,得到该用户的预测评分pred。
接下来,将用户已经评过分的商品过滤掉,剩下对未评分商品的预测,按照预测分值的高低进行排序,对预测评分较高的商品优先进行推荐:

从结果可以看到,用户3没有观看过的电影有102、103和106,其打分依次为3.925、4.0和4.3,所以应该向用户3推荐商品的顺序应当为电影103、106和102。
②使用欧氏距离的倒数作为相似度
在使用欧式距离计算两项item间距离时,需要找到对这两项item都评过分的用户进行计算,而我们的评分矩阵中,分为“0”实际上是代表没有评分,因此不能直接使用欧式距离公式,需要我们自定义一个,然后使用DistanceMetric进行生成距离矩阵:


在上述代码中,我们使用了距离的倒数来衡量item间的相似度,为了避免结果无意义,对欧式距离先加了1再取倒数。
后续的推荐过程与使用Jaccard相似度时的方法完全一致,故略去。
与欧氏距离类似,余弦相似度、皮尔森相关系数等计算也需要考虑提取共同评价过的商品进行计算,方法与欧式距离类似。
4.5 使用scikit-surprise做推荐
4.5.1 读取DataFrame进行建模
scikit-surprise是scikit系列推荐算法库,可以实现基于用户/商品的协同过滤、基于矩阵分解的推荐等多种算法,支持交叉验证和参数空间搜索,能够读取文本文件、pandas.DataFrame等数据类型,其接口使用方法与scikit-learn十分接近,是一款十分方便的工具。
要使用scikit-surprise首先需要进行安装——使用pip install scikit-surprise可以很方便地安装。然后我们对3.4节中的电影评分数据进行建模:

要读取评分数据,首先需要初始化一个Reader对象——读取DataFrame是该对象的参数设置很简单,只需指定评分的值域范围即可。读取的数据是一个默认进行k折交叉验证的可迭代类型,因此为了训练可以使用train_test_split将数据集切分为训练集和测试集,然后使用fit进行模型训练——与scikit-learn十分相似。训练好的模型可以使用test进行测试,或者使用predict进行预测:

推荐模型常用的评估指标有RMSE(均方根误差)、MAE(平均绝对误差)等,当然,我们可以使用交叉验证来进行模型评估:

此处cross_validate中传入的参数需要是一个自动K折验证的数据集(即从DataFrame或文件中读取的包含全部评分数据的对象)。cross_validate返回的验证结果可以看到5折交叉的验证集上的RMSE从1.021到1.700不等。
4.5.2 读取文本文件数据进行建模
在实际工作当中,推荐模型的训练集一般可以从文件中直接读取,并以交叉验证的方式搜索最优超参数。为了更贴近实际情况,我们给出这样的一个示例如下:

示例中,我们读取开源的电影评分数据集MovieLens,这需要在Reader中指定了文件格式(包含用户user、物品item、评分rating、时间戳timestamp四个变量,采用tab键\t作为分隔符),然后使用Dataset.load_from_file方法就可以从文件中将需要的数据解析出来了。因为该数据集已经内置在surprise当中,所以也可以直接使用Dataset.load_builtin(ml-100k)进行装载。在数据正常读取后,我们使用了GridSearchCV,以3折交叉验证的方式对param_grid中的参数进行搜索,判断标准为rmse和mae,搜索结果可以使用如下代码展示:

结果显示rmse最优可以达到0.987,对应的最优参数reg_all为0.4, k为20。其中reg_all代表全局的正则化强度,k代表了在汇总数据时最多使用的邻居数量。
scikit-learn提供了多种推荐算法,如SVD、SlopeOne等,只需将上述代码中的模型更换一下即可,相对应不同模型的参数也需要进行调整,感兴趣的读者可以参考其官方文档。


















暂无评论内容