

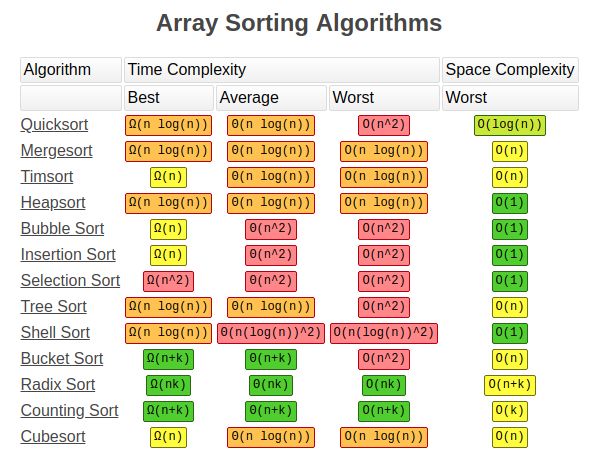
参考书籍:项亮. 推荐系统实践[M]. 人民邮电出版社, 2012.
推荐系统与搜索引擎为了解决信息过载(Information overload)的问题,人们提出了推荐系统和搜索引擎两种解决方案。
搜索引擎更倾向于人们有明确的目的,可以将人们对于信息的寻求转换为精确的关键字,然后交给搜索引擎最后返回给用户一系列列表,用户可以对这些返回结果进行反馈,并且是对于用户有主动意识的,但它会有马太效应的问题,即会造成越流行的东西随着搜索过程的迭代会越流行,使得那些越不流行的东西石沉大海。
推荐引擎更倾向于人们没有明确的目的,或者说他们的目的是模糊的,通俗来讲,用户连自己都不知道他想要什么,这时候正是推荐引擎的用户之地,推荐系统通过用户的历史行为或者用户的兴趣偏好或者用户的人口统计学特征来送给推荐算法,然后推荐系统运用推荐算法来产生用户可能感兴趣的项目列表,同时用户对于搜索引擎是被动的。其中长尾理论(人们只关注曝光率高的项目,而忽略曝光率低的项目)可以很好的解释推荐系统的存在,试验表明位于长尾位置的曝光率低的项目产生的利润不低于只销售曝光率高的项目的利润。推荐系统正好可以给所有项目提供曝光的机会,以此来挖掘长尾项目的潜在利润。
2.推荐算法分类
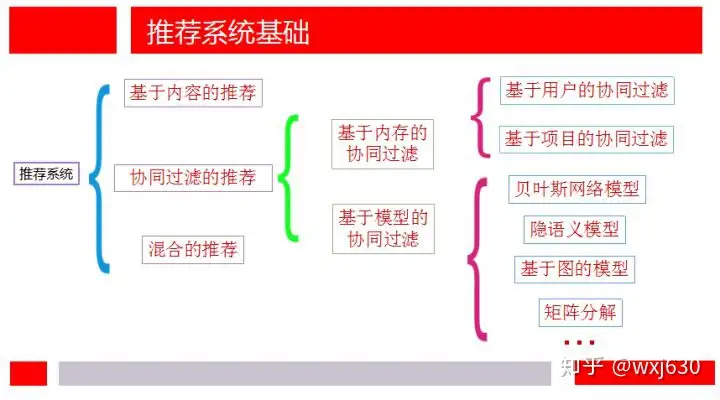
3.User_CF算法
import math
# 两两用户计算余弦相似度,但其实很多用户没有买过同一物品,即N(u)并N(v)=0
def UserSimijlarity(train):
W=dict()
for u in train.keys():
for v in train.keys():
if u==v:
continue
W[u][v]=len(train[u] & train[v])
W[u][v]/=math.sqrt(len(train[u])*len(train[v])*1.0)
# 简化计算,先建立物品-用户的倒排表
def UserSimailarity_v2(train):
# building inverse table for item_users
item_users=dict()
for u,items in train.items():
for i in items.keys():
if i not in item_users():
item_users[i]=set()
item_users[i].add(u)
# calculate co-rated items between users
C=dict()
N=dict()
for i,users in item_users.items():
for u in users:
N[u]=N[u]+1
for v in users:
if u==v:
continue
C[u][v]+=1
# calculate final simalarity matrix W
W=dict()
for u,related_users in C.items():
for v,cuv in related_users.items():
W[u][v]=cuv/math.sqrt(N[u]*N[v])
return W
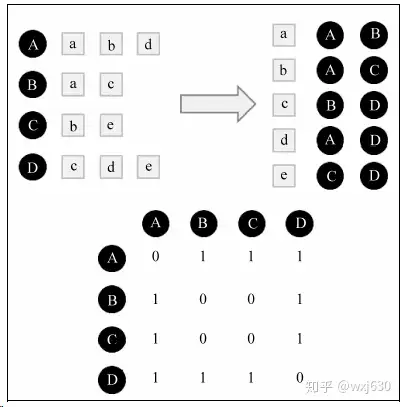
4.Item-CF算法
import math
# ItemCF算法
def ItemSimilarity(train):
C = dict()
N = dict()
for u,items in train.items():
for i in items.keys():
N[i] += 1
for j in items.keys():
if i == j:
continue
C[i][j] += 1
W = dict()
for i,related_items in C.items():
for j,cij in related_items.items():
W[i][j] = cij / math.sqrt( N[i] * N[j])
return W
# ItemCF-IUF算法
def ItemSimilarity_v2(train):
C = dict()
N = dict()
for u,items in train.items():
for i in items.keys():
N[i] += 1
for j in items.keys():
if i == j:
continue
C[i][j] += 1 / math.log(1+len(items)*1.0)
W = dict()
for i,related_items in C.items():
for j,cij in related_items.items():
W[i][j] = cij / math.sqrt( N[i] * N[j])
return W
def Recommend(train,user_id,W,K):
rank = dict()
ru = train[user_id]
for i,pi in ru.items():
for j,wj in sorted(W[i].items,key=itemgetter(1),reverse=True)[0:K]:
if j in ru:
continue
rank[j] += pi*wj
return rank
图是一个根据上面的程序计算物品相似度的简单例子。图中最左边是输入的用户行为记录,每一行代表一个用户感兴趣的物品集合。然后,对于每个物品集合,我们将里面的物品两两加一,得到一个矩阵。最终将这些矩阵相加得到上面的C矩阵。其中C[i][j]记录了同时喜欢物品i和物品j的用户数。最后,将C矩阵归一化可以得到物品之间的余弦相似度矩阵W。
MovieLens数据集:
wiwi
THE END


















暂无评论内容