
平台的数据集版块,共有200个不同类别,不同应用的数据集。
本周在此基础上,又上新12种人体姿态识别相关的数据集,目前总共有212种数据集。
① 文本摘要
数据集名称:CurationCorpus数据集
数据集图片:

数据集内容:Curation Corpus数据集是一个新闻报道,专业撰写的摘要集合,并带有新闻本身的链接。便于用户从摘要获取到文本的所有关键信息点,而无需阅读整个文档。
数据集数量:Curation Corpus数据集,包含40000篇摘要数据
数据集功能:文本摘要生成
下载链接:点击查看
② 机器翻译
(1)XNLI数据集
数据集内容:XNLI是一种评估语料库,用于15种语言的语言迁移和跨语言句子分类。
许多NLP系统(例如,情绪分析,主题分类)都依赖于高资源语言的训练数据,但是在测试时不能直接用于其他语言的预测。在涉及跨语言数据的几乎所有应用中,都会遇到此问题。
机器翻译可用于将任意语言,翻译成高资源语言,以缓解此问题。但是,在每个方向上都有MT系统,成本很高,而且并不是跨语言分类的最佳解决方案。跨语言编码器是一种更便宜,更优雅的选择。
为了评估这种跨语言的句子理解方法,构建了XNLI,这是SNLI / MultiNLI语料库的15种语言的扩展 。
数据集数量:XNLI语料库是针对MultiNLI语料库的5000个测试和2500个开发对文字。两对文字均带有文字注释,并被翻译成14种语言:法语,西班牙语,德语,希腊语,保加利亚语,俄语,土耳其语,阿拉伯语,越南语,泰语,中文,北印度语,斯瓦希里语和乌尔都语。
这将产生112.5万个带注释的对。每个文字可以与15种语言中的相应文字进行关联,总计超过1.5M的组合集合。
数据集功能:机器翻译
下载链接:点击查看
(2)PAWS-X数据集
数据集内容:PAWS-X数据集包含23659组人工翻译的PAWS扩展句子对,和296406组机器翻译的训练对,这些对以六种语言进行翻译:法语,西班牙语,德语,中文,日语和韩语。
数据集数量:23659组PAWS扩展句子对、296406组机器翻译的训练对
数据集功能:机器翻译
下载链接:点击查看
(3)TED talks Translate数据集
数据集图片:
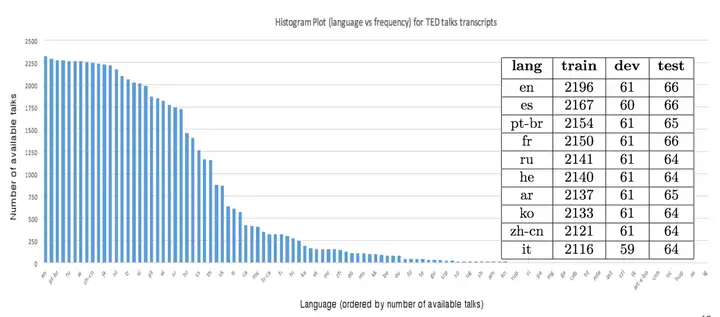
数据集内容:TED talks Translate数据集收集了2017年初,TED演讲的通用语料库,该语料库已被翻译成许多罕见的语言。上图显示了各类语言数据中,训练划分时的直方图。
数据集数量:TED talks Translate数据集包含109种语言的2400多个演讲文稿。
数据集功能:机器翻译
下载链接:点击查看
③ 智能助理
(1)TaskMaster-2数据集
数据集内容:与Taskmaster-1数据集不同,TaskMaster-2中既包括书面的“自我对话”,又包括口语的两人对话,Taskmaster-2完全由口语的两人对话组成。
此外,虽然Taskmaster-1几乎完全基于任务,但Taskmaster-2包含大量面向搜索和推荐的对话框,例如在饭店,航班,旅馆和电影院中就可以看到。
音乐浏览和体育对话几乎完全基于搜索和推荐,此版本中的所有对话框都是使用“绿野仙踪”(Wizard-of-Oz 平台)方法创建的。
数据集数量:Taskmaster-2数据集由以下七个域中的17,289个对话框组成。每个域的对话框都可以在该目录的“数据”文件夹中的七个json文件中找到,即Taskmaster / TM-2-2-20 / data /。
● 餐厅(3276)
● 订餐(1050)
● 电影(3047)
● 酒店(2355)
● 航班(2481)
● 音乐(1602)
● 运动(3478)
数据集功能:智能助手、会话推荐
下载链接:点击查看
④ 机器阅读理解
(1)DuReader数据集
数据集内容:
机器阅读理解(Machine Reading Comprehension,MRC)是一种利用算法,使计算机理解文章语义并回答相关问题的技术。由于文章和问题均采用人类语言的形式,因此机器阅读理解属于自然语言处理(NLP)的范畴,也是其中最新最热门的课题之一。
下图是一个机器阅读理解的样例,其中,模型需要用文章中的一段原文回答问题。

DuReader是用于机器阅读理解(MRC)和问答(QA)的大规模现实世界中文数据集。
数据集中的所有问题均来自真实的匿名用户查询,使用百度搜索引擎,从网络和百度知道中提取有答案的问题,且答案是人为产生的。
与现有数据集相比,DuReader的优势总结如下:
● 真正的问题
● 真实文章
● 真实答案
● 实际应用场景
● 丰富的注释
数据集数量:DuReader 2.0版包含30万多个问题,140万个证据文档和660K个人工生成的答案。它可以用于训练或评估MRC模型和系统。
数据集功能:机器阅读理解
下载链接:点击查看
(2)PD&CFT数据集
数据集内容:PD&CFT数据集是一个中文阅读理解数据集,其中包括《人民日报》和《儿童童话》(PD&CFT)相关资料。
数据集数量:PD&CFT数据集的统计信息如下所示。
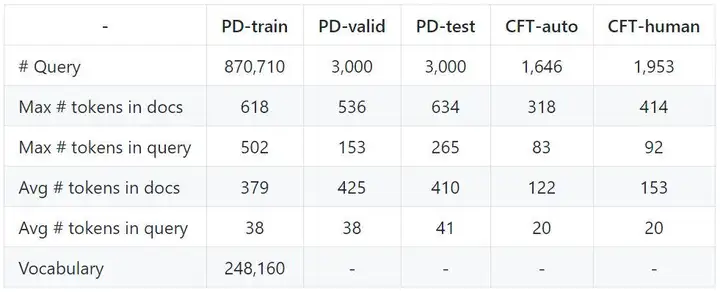
数据集功能:机器阅读理解
下载链接:点击查看
(3)C3数据集
数据集内容:C3数据集是首个中文多项选择,机器阅读理解数据集。收集的主要是形式自由的多项选择题,来自汉语水平考试和民族汉语考试的阅读材料,包括试卷和练习。
数据集数量:C3数据集包含13369篇文章和19577个问题,其中的60%用是训练集,20%是开发集,20%是测试集。
数据集功能:机器阅读理解
下载链接:点击查看
(4)Delta Reading Comprehension Dataset(DRCD)数据集
数据集内容:Delta Reading Comprehension数据集,是通用领域繁体中文机器阅读理解数据集,适用于迁移学习之简体中文阅读理解使用。
数据集数量:

数据集功能:繁体机器阅读理解
下载链接:点击查看
⑤ VQA视觉问答
(1)KnowIT VQA数据集
数据集内容:VQA是一个将NLP与图像处理相结合的任务,通常以一张图片和一个关于这张图片自由、开放式的自然语言问题作为输入,以生成一条自然语言答案作为输出。
简单来说,VQA就是给定的图片进行问答,因此VQA涉及到多方面的AI技术。
以下面图像为例:

● 细粒度识别(这位女士是白种人吗?)
● 物体识别(图中有几个香蕉?)
● 行为识别(这位女士在哭吗?)
● 对问题所包含文本的理解(NLP)
KnowIT VQA是一个视频数据集,将视觉,文本和时间连贯性推理,与基于知识的问题结合在一起。
数据集数量:KnowIT VQA数据集包含24282个有关“大爆炸理论”的人工生成的问题-答案对。
数据集功能:VQA视觉问答
下载链接:点击查看
⑥ 成语理解
(1)ChID数据集
数据集内容:ChID数据集是第一个成语完形填空数据集,主要对于候选词语的选择,和成语的表示Representation进行了研究。
数据集功能:成语理解
下载链接:点击查看
⑦ 文本分类
(1)THUCTC工具包
数据集内容:文本分类任务的目的,是想办法预测出文本对应的类别,是NLP的基础任务。
比如对新闻分类:政治、体育、军事、社会,微博评论分类:好评、中评、差评。
文本分类的过程,通常包括特征选取、特征降维、分类模型学习三个步骤。如何选取合适的文本特征并进行降维,是中文文本分类的挑战性问题。
THUCTC(THU Chinese Text Classification)是由清华大学自然语言处理实验室,推出的中文文本分类工具包,能够自动高效地实现用户自定义的文本分类语料的训练、评测、分类功能。
数据集功能:中文文本分类
下载链接:点击查看






















暂无评论内容