
Kubernetes简介
Kubernetes是Google开源的一个容器编排引擎,一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,采用声明式配置[1],支持自动化部署、大规模可伸缩、应用容器化管理。
举个例子说明:通常情况下,在生产环境中部署一个应用程序时我们需要部署该应用的多个实例以便进行负载均衡,传统方式需要我们逐台服务器进入Docker进行部署,而如果使用Kubernetes,我们就可以将全部服务器建立一个集群,在集群中任意一个Master节点创建一个Service与多个容器Pod,每个容器Pod内运行一个应用实例,然后通过Kubernetes内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些过程的细节无需运维人员自行配置和处理,Kubernetes将全部自动完成。除此之外,运维或开发人员可以指定Pod的数量,Kubernetes将自动监控并确保集群始终处于预期的工作状态。
Kubernetes核心架构简析
Kubernetes是属于主从设备模型(Master-Slave架构),即有Master节点负责核心的调度、管理和运维,Slave节点则执行用户的程序。在Kubernetes中,主节点一般被称为Master Node 或者 Head Node,而从节点则被称为Worker Node 或者 Node。
Master节点通常包括API Server、Scheduler、Controller Manager等组件(他们在官方文档中被称为Control Plane Components[2],我们通常用Master组件代替),Node节点通常包括Kubelet、Kube-Proxy等组件(在官方文档中被称为Node组件)。
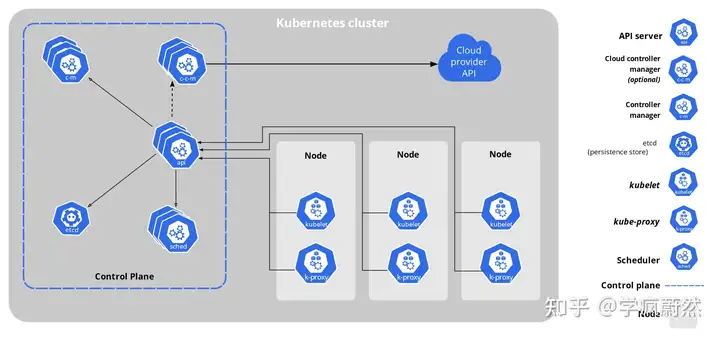
Kubernetes可简称K8S,是用8代替名字中间的8个字符“ubernete”而成的缩写。为读者阅读方便,在下文中,我们将以K8S代替Kubernetes,除非特别说明,否则K8S均指代Kubernetes。
Kubernetes API server
K8S控制层的核心,是整个系统的数据总线和数据中心。K8S通过kube-apiserver这一进程API Server提供服务,该进程运行在K8S的Master节点上,默认有两个端口。API Server负责提供Http API,以供用户、集群中的不同部分和集群外部组件相互通信。[3]
K8S API Server在负责集群各功能模块之间的通信时,各模块通过API Server将信息存入ETCD,当需要获取和操作这些数据时,再通过API Server提供的REST接口(GET\LIST\WATCH方法)来进行操作,从而实现各模块之间的信息交互。
通过API Server用户可以查询和操纵K8S API 中对象(如:Pod、Namespace、ConfigMap 和 Event)的状态。[3]用户大部分操作都可以通过 kubectl 命令行接口或类似 kubeadm 这类命令行工具来执行,这些工具在背后也是调用 API,此外用户也可以使用 REST 调用来访问这些 API。[3]
Kubernetes Scheduler
K8S所有Worker Node 的调度器。K8S Scheduler 运行在Master节点上,它通过监听API Server将发现的每一个未调度的 Pod (PodSpec.NodeName为空的Pod)通过创建Binding 指示调度到一个合适的Worker Node上来运行。调度器会依据下文的调度原则来做出调度选择。
在一个集群中,满足一个Pod调度请求的所有 Node 称之为可调度节点。如果没有任何一个Node能满足Pod的资源请求,那么这个Pod将一直停留在未调度状态直到调度器能够找到合适的Node。[4]调度器先在集群中找到一个Pod的所有可调度节点,然后根据一系列函数对这些可调度节点打分,选出其中得分最高的Worker Node来运行Pod。之后,调度器将这个调度决定通知给API Server,这个过程即为Binding。[4]
Kubernetes Controller Manager
K8S所有Worker Node的监控器。Controller Manager作为集群内部的管理控制中心,运行在Master节点上,是一个永不休止的循环。它实质上是群内的Node、Pod、服务(Server)、端点(Endpoint)、命名空间(Namespace)、服务账号(ServiceAccount)、资源定额(ResourceQuota)的监视与守护进程的合集,每个资源的Controller通过API Server提供的接口实时监控每个资源对象的当前状态,当某个Node意外宕机时,Controller Manager会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
ETCD
K8S的存储服务。ETCD是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。[2]K8S集群中只有API server有ETCD的读写权限。
Kubelet
K8S中Master节点在每个Worker Node节点上运行的主要“节点代理”,也可以说是Master 的“眼线”。它会定期向Master Node汇报自己Node上运行服务的状态,并接受来自Master Node的指示采取调整措施。负责控制由 K8S 创建的容器的启动停止,保证节点工作正常。
Kubelet基于PodSpec来工作的,每个PodSpec是一个描述Pod的YAML或JSON对象。Kubelet接受通过各种机制(但主要是通过 API Server)提供的一组 PodSpec,并确保这些 PodSpec中描述的容器处于运行状态且运行状况良好。[5]
Kube-Proxy
K8S的网络代理,在每个节点上运行,负责Node在K8S的网络通讯、以及对外网络流量的负载均衡。Kube-proxy维护节点上的网络规则,实现了K8S Service 概念的一部分,它的作用是使发往Service的流量负载均衡到正确的Pod。由于性能问题,目前大部分企业用K8S进行实际生产时,都不会直接使用Kube-proxy作为服务代理,而是通过Ingress Controller来集成HAProxy, Nginx来代替Kube-proxy。
Kubernetes高可用(HA)分析
Kubernetes 采用的是中心辐射型(Hub-and-Spoke)API 模式。 所有从集群(或所运行的 Pods)发出的 API 调用都终止于 API server,[6]而API Server直接与ETCD数据库通讯。若仅部署单一的API server ,当API server所在的 VM 关机或者 API 服务器崩溃将导致不能停止、更新或者启动新的 Pod、服务或副本控制器[7];而ETCD存储若发生丢失,API 服务器将不能启动。若要实现Kubernetes高可用,则Master组件必须是冗余的,尤其是ETCD、ApiServer必须部署在多个节点上。
根据这一核心要求,我们尝试构建如图2所示的集群,包含几个负载均衡的主节点,每个主节点包含完整的主组件和ETCD组件:
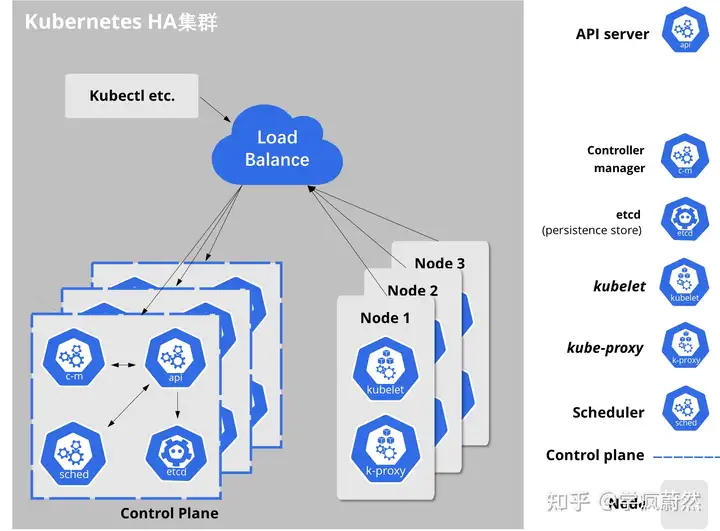
Node可靠性:Systemd作为Linux CentOS系统的管理守护进程,可确保Docker 后台支撑服务和Kubelet在发生故障时自动重启,以此确保Worker Node可靠。
集群状态维持:K8S集群状态信息存储在ETCD集群中,该集群非常可靠,且可以分布在多个节点上。需要注意的是,在ETCD群集中至少应该有3个节点,且为了防止2网络分裂,节点的数量必须为奇数。
API服务器冗余灾备:K8S的API server服务器是无状态的,从ETCD集群中能获取所有必要的数据。这意味着K8S集群中可以轻松地运行多个API服务器,而无需要进行协调,因此我们可以把负载均衡器(LB)放在这些服务器之前,使其对用户、Worker Node均透明。
Master选举:一些主组件(Scheduler和Controller Manager)不能同时具有多个实例,可以想象多个Scheduler同时进行节点调度会导致多大的混乱。由于Controller Manager等组件通常扮演着一个守护进程的角色,当它自己失败时,K8S将没有更多的手段重新启动它自己,因此必须准备已经启动的组件随时准备取代它。高度可扩展的Kubernetes集群可以让这些组件在领导者选举模式下运行。这意味着虽然多个实例在运行,但是每次只有一个实例是活动的,如果它失败,则另一个实例被选为领导者并代替它。[8]
K8S高可用:只要K8S集群关键结点均高可用,则部署在K8S集群中的Pod、Service的高可用性就可以由K8S自行保证。
特别的,负载均衡节点承担着Worker Node集群和Master集群通讯的职责,同时Load Balance没有部署在K8S集群中,不受Controller Manager的监控,倘若Load Balance发生故障,将导致Node与Master的通讯全部中断,因此需要对负载均衡做高可用配置。Load Balance同样不能同时有多个实例在服务,因此使用Keepalived对部署了Load Balance的服务器进行监控,当发生失败时将虚拟IP(VIP)飘移至备份结点,确保集群继续可用。
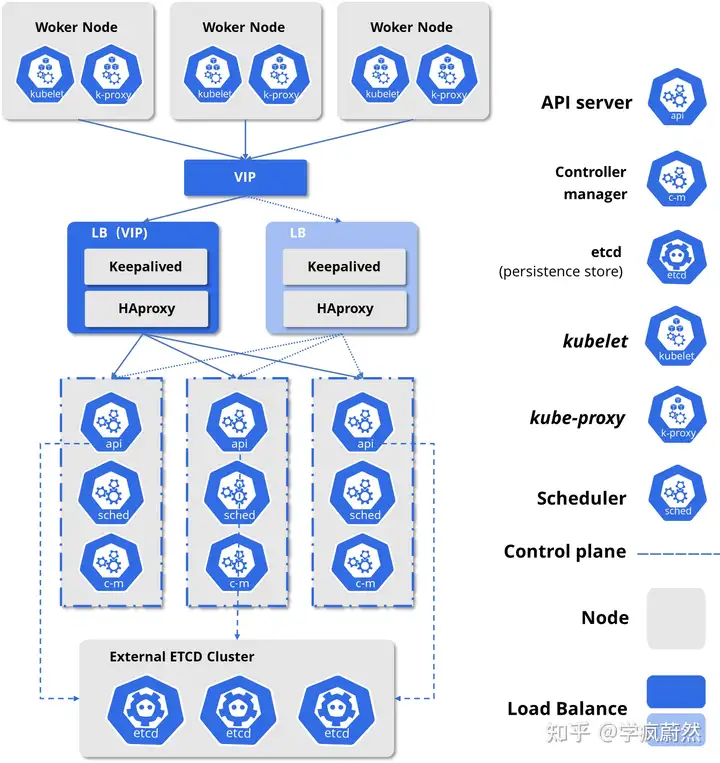
经过上述分析,可知在正式环境中确保Master高可用,并启用访问安全机制,至少应包括以下几个方面:[9]
1. Master的kube-apiserver、kube-controller-mansger和kube-scheduler服务至少三个结点的多实例方式部署。
2. ETCD至少以3个结点的集群模式部署。
3. Master、ETCD集群启用基于CA认证的HTTPS安全机制,Master启用RBAC授信机制。
4. Load Balance使用双机热备,向Node暴露虚拟IP作为入口地址,供客户端访问。
细节架构图如下:
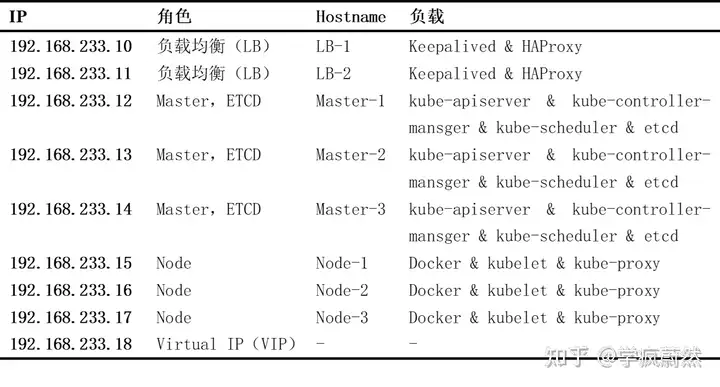
为了表述更加清晰,集群内各服务器情况如下:
部署高可用负载均衡器
为三个API Server服务部署HAProxy和Keepalived,使用VIP 192.168.233.18作为Mater结点的唯一入口地址,供客户端访问。
将HAProxy和Keepalived分别部署两个实例,组成高可用架构以避免单点故障。HAProxy负责将客户端请求转发到后端的3个kube-apiserver实例上,Keepalived负责维护VIP 192.168.233.18的高可用。
HAProxy部署配置
运行以下命令,安装 HAproxy:
在LB-1、LB-2服务器上运行以下命令以配置HAProxy(两台机器的 Proxy 配置相同):
HAProxy配置文件haproxy.cfg清单如下(代码清单1-1 haproxy.cfg):
其中:frontend声明了前端(HAProxy)的监听协议和端口号,在这里我们使用TCP协议,端口号为6443,为了安全起见,实际部署时应选用其他端口;backend声明了后端转发的API Server地址,使用IP:Port方式进行表示,在这里我们使用了TCP协议,以roundrobin(轮询)为负载平衡方式,当然我们也可采用其他方式,有以下八种可供选择:
static-rr,表示根据权重;leastconn,表示最少连接者先处理;source,表示根据请求源IP;uri,表示根据请求的URI;url_param,表示根据请求的URl参数‘balance url_param’;
hdr(name),表示根据HTTP请求头来锁定每一次HTTP请求;rdp-cookie(name),表示根据据cookie(name)来锁定并哈希每一次TCP请求。[10]
在LB-1、LB-2上的部署配置是相同的。
为了更直观的察看负载情况,额外配置HAProxy的监控页面,在代码清单1-1中继续添加:
其中:bind为开放的端口号;stats auth为鉴权所需的账号名和密码。如清单1-2所示的配置完成后,访问VIP及端口号(即 http://192.168.233.18:8080/admin),并使用用户名admin 密码admin验证后即可进入。
Keepalived部署配置
运行以下命令,安装 Keepalived:
在LB-1服务器上运行以下命令以配置 Keepalived(两台机器的 Keepalived配置不同):
Keepalived配置文件keepalived.cfg清单如下(代码清单2 keepalived.cfg):
其中:vrrp_instance中声明了名为haproxy-vip的虚拟路由器VRRP,启动时state为后备(可指定MASTER,但若集群中没有MASTER状态的路由器将自动选举产生,非抢占式部署);VIP绑定的设备端口为ens33;virtual_ipaddress即VIP地址为192.168.233.18。
特别的,对于interface字段,必须与部署的目标服务器的网卡信息一致,可以在目标服务器上运行ifconfig以获取该值。为unicast_src_ip提供的 IP 地址是当前正在部署的目标服务器的 IP 地址[11],代码清单2中的为LB-1服务器的配置,为192.168.233.10,对于LB-2服务器则为192.168.233.11。对于也安装了HAproxy和Keepalived进行负载均衡的其他目标服务器,必须在字段unicast_peer中输入其 IP 地址[11],代码清单2中的为LB-1服务器的配置,应为LB-2的服务器IP地址。更多节点集群的配置以此类推。
均安装完毕后,重启Keepalived和HAproxy节点,并添加节点自启动:
部署K8S高可用集群
Kubeadm部署高可用集群(不确保100%可以成功)
K8S在1.4版本引入了Kubeadm工具以简化集群安装过程,在高可用集群部署过程中,我们将基于此进行:
除LB结点外的所有节点安装Docker,Kubeadm,Kubectl,Kubelet;
在Master-1节点(或任意Master节点)执行:
其中:image-repository是镜像源,由于kubeadm 默认从官网http://k8s.grc.io下载所需镜像,国内无法访问,因此需要通过image-repository指定阿里云镜像仓库地址。pod-network-cidr是POD的网段,本例中将其设为10.122.0.0/16,可自行修改,需要注意Calico等网络插件安装时的配置需要用到该网段。control-plane-endpoint是负载均衡的地址,在这里使用负载均衡集群的虚拟IP地址192.168.233.18,端口为负载均衡转发的共同端口(即在haproxy.cfg配置的frontend 中bind的端口),这里为6443。
在Master-2、Master-3节点(其他两个Master节点)执行:
上述指令不可直接执行,在首个Master节点初始化完成后,会有描述为“You can now join any number of the control-plane node running the following command on each as root:”的提示,上述指令将出现在该提示后,直接复制运行即可。
在Node-1、Node-2、Node-3节点执行:
上述指令不可直接执行,在任意一个Master节点初始化完成后,会有描述为“Then you can join any number of worker nodes by running the following on each as root:”的提示,上述指令将出现在该提示后,直接复制运行即可。
在节点加入后,还应部署CNI网络插件,例如Colico等,以建立容器到虚拟机上的网络,具体过程可参考:
KubeKey快捷部署集群
鉴于2.3所描述方案在实际环境中部署可能仍然较为复杂,有一定失败的概率,我们使用一个开源工具KubeKey来部署Kubernetes。[12]KubeKey 作为一种集群安装工具,从版本 v1.2.0 开始,提供了内置高可用模式,支持一键部署高可用集群环境。
运行以下命令,从正确的区域下载 KubeKey,并创建配置文件:[12]
其中:v1.21.5 Kubernetes版本,为如果不指定 Kubernetes 版本,KubeKey 将默认安装 Kubernetes v1.21.5。
运行上述命令后,将创建配置文件 config-sample.yaml。编辑文件以添加机器信息、配置负载均衡器,该配置如下所示:[13]
其中:host部分address与internalAddress均为目标服务器的ip地址,user必须为root或其他拥有管理员权限的账号,password为该账号对应的密码,name作为该服务器的标记,与roleGroups组中的各个角色下属相对应。controlPlaneEndpoint的address为负载均衡的IP地址,这里我们配置为负载均衡高可用的VIP地址。
在安装开始前,若Kubernetes 版本 ≥ 1.18请检查所有节点是否已经安装了socat、conntrack、ebtables、ipset软件,若没有安装需要在安装开始前完成安装。此外还需检查SSH对应端口是否已经开放,是否可以使用配置文件中的用户名和密码正常访问。
为了正常安装,强烈建议关闭SELinux和Firewalld,以避免意外发生。
运行以下命令,完成集群自动部署:
整个安装过程可能需要 10 到 20 分钟,具体取决于服务器配置和网络环境。
集群故障模拟试验
考虑到实验环境,我们缩减了集群的部署规模:

由于Master节点数量未大于3个,ETCD高可用在此次实验中暂未实现。
负载均衡LB故障模拟
对两个负载均衡服务器LB1(192.168.233.10)与LB2(192.168.233.11)进行灾备测试:
当前LB1未持有VIP(192.168.233.16,采用了缩配的集群):

当前LB2持有VIP(192.168.233.16):

模拟故障状态:
当前LB2(192.168.233.11)执行:systemctl stop haproxy,使得HA-PROXY服务不可用,模拟LB2故障下线。
当前LB2(192.168.233.11)将失去VIP(192.168.233.16):
此时LB1(192.168.233.10)得到VIP(192.168.233.16),继续提供服务:

执行kubectl get nodes测试:

可见所有Node结点均未丢失,负载均衡高可用实现。
3.2.2 K8S集群故障模拟
目前集群状态良好,执行kubectl get nodes查看各节点情况:
查看部署的pod运行节点:

目前一个NFS存储服务在节点Node-2上运行。
使用VIP查看目前的负载均衡情况:

目前两个ApiServer运作均正常,且VIP访问正常。
现在模拟服务器停机故障,随机停止负载均衡LB节点、Master节点与Node节点中的一个节点,如下:

目前LB-1节点、Master-2节点与Node-2节点均停止了服务,集群进入容灾状态:
使用VIP查看目前的负载均衡情况:

VIP访问正常,LB可用性可以保证,一个ApiServer运作正常(Master-1节点的),另一个ApiServer已经停机(Master-2节点的),流量将不会向Master-2节点均衡。
执行kubectl get nodes查看各节点情况:

目前ApiServer服务器访问正常,Master可用性可以保证;Master-2节点与Node-2节点均丢失。
查看部署的pod运行节点:

Node-2节点的pod已经丢失,NFS短时降级,正在Node-1节点上创建pod取代它:

灾难状态结束,NFS存储服务目前已经恢复在节点Node-1上运行,可以继续提供服务。
通过上述实验,有力的证明了这一K8S集群的高可用性。
(*注:本文将用于课程报告,请勿抄袭。本文发布时间为2021年12月12日,若提交的课程结课论文中有部分或全部内容与本文重复,请判断作者邮箱是否为neosunjz@qq.com。)
















暂无评论内容