
Sink
Flink没有类似spark中foreach方法 让用户进行迭代操作
虽有对外的输出操作 都要利用Sink完成
最后通过类似如下方式完成整个任务最终输出操作
stream.addSink(new MySink(xxxx))
官方提供了一部分框架的Sink 除此之外 需要用户自定义实现sink

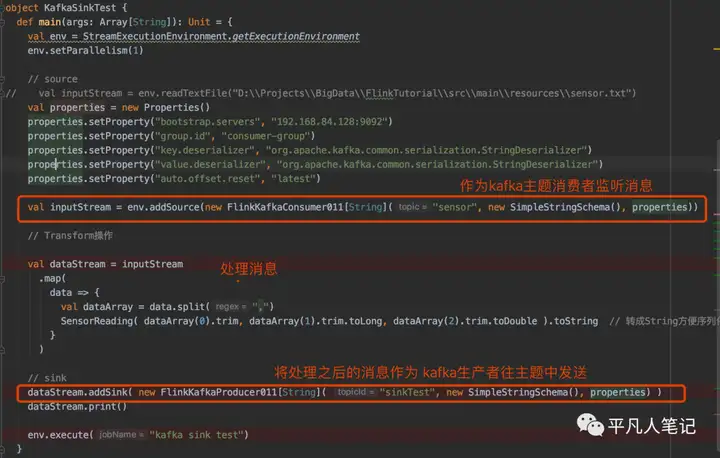
Kafka
./bin/kafka-console-producer.sh –broker-list localhost:9092 –topic sensor
往sinkTest主题中生产消息 所以需要有一个监听该主题的消费者./bin/kafka-console-consumer.sh –bootstrap-sever localhost:9092 –topic sinkTest
具体演示过程在这里面有详细说明Flink原理简介和使用
Redis Sink
源码https://gitee.com/pingfanrenbiji/Flink-UserBehaviorAnalysis/blob/master/FlinkTutorial/src/main/scala/com/xdl/apitest/sinktest/RedisSinkTest.scala
源码分析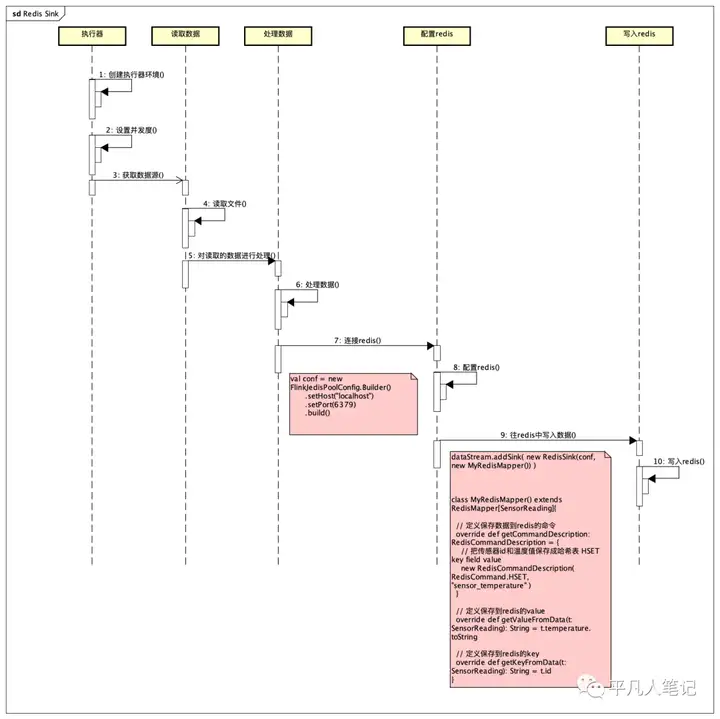
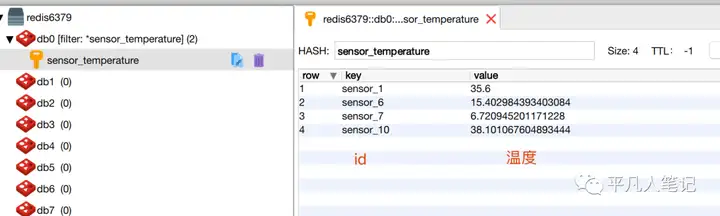
set :
1、普通的key-value方式存储数据
2、可以设置过期时间
3、时间复杂度为O(1)
4、每执行一个set 在redis中就会多一个key
hset:
1、以hash散列表的形式存储
2、超时时间只能设置在大key上
3、单个filed则不能设置超时时间
4、时间复杂度是O(N) N是单个hash上filed的个数
5、hash上不适合存储大量的filed 多了比较消耗cpu
6、但以散列表存储比较节省内存
使用场景总结:
1、在实际的使用过程中 使用set应该保存单个大文本非结构化数据
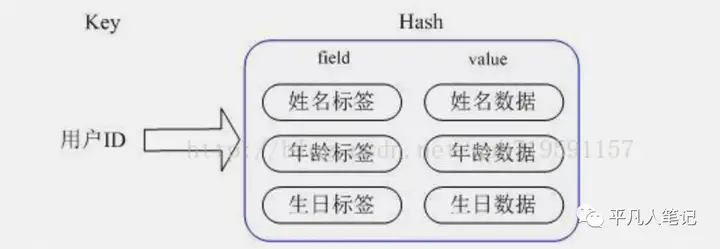
2、hset则存储结构化数据 一个hash存储一条数据 一个filed存储一条数据中的一个属性 value则是属性对应的值
举例说明:
用户表
id,name,age,sex
1、1,张三,16,1
2、2,李四,22,1
3、3,王五,28,0
4、4,赵六,32,1
如果要整表缓存到 redis 中则使用 hash ,一条数据一个hash 一个hash 里则包含4个filed。
hset user_1 id 1 name 张三 age 16 sex 1
hset user_2 id 2 name 李四 age 16 sex 1
如果用户的某个属性值改变,还可以单个修改
把张三的年龄改为30 则可以使用命令 hset user_1 age 30
set存储举例:
1、缓存应用整个首页 html
2、某个商品的详情介绍
a、一般来说商品的详情介绍是makdown语法的富文本信息
b、html 格式的富文本信息
3、应用中的 某个热点数据
ElasticSearch Sink
安装elasticSearch
下载安装包https://www.elastic.co/cn/downloads/elasticsearch
elasticsearch-7.10.1-darwin-x86_64.tar.gz
如果想选择其他版本
引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_2.11</artifactId>
<version>1.11.0</version>
</dependency>
代码分析
源码https://gitee.com/pingfanrenbiji/Flink-UserBehaviorAnalysis/blob/master/FlinkTutorial/src/main/scala/com/xdl/apitest/sinktest/EsSinkTest.scala
分析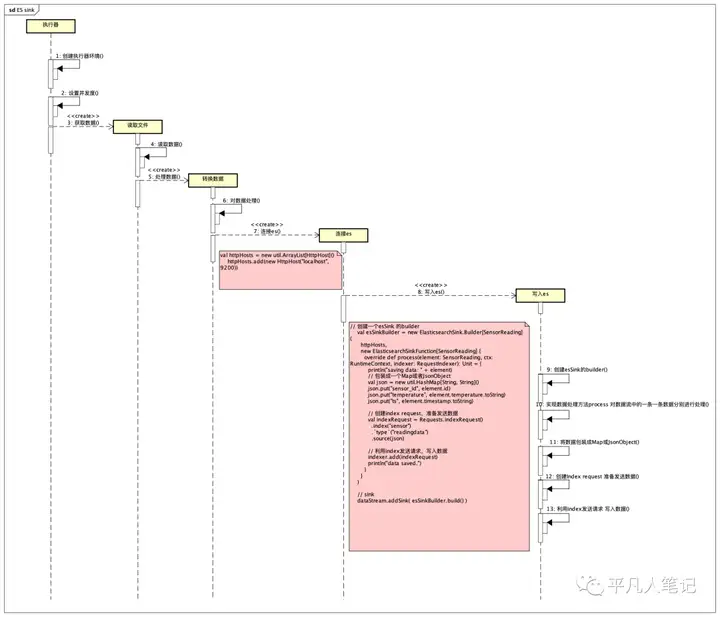

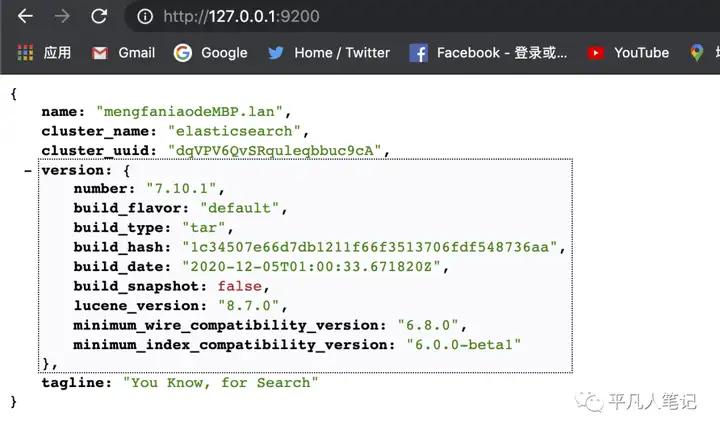
确认是否保存进入es
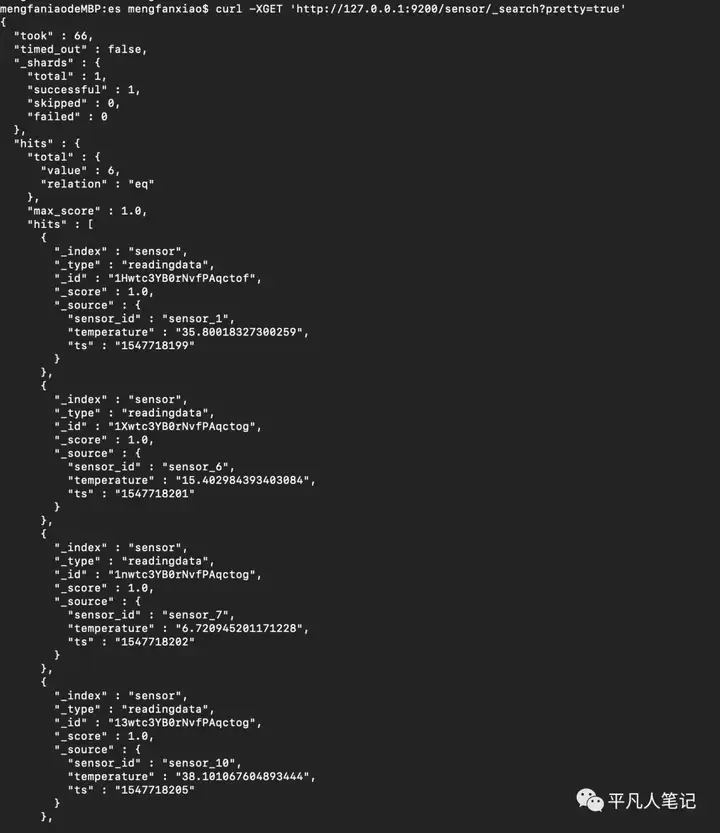
查询所有索引curl -XGET http://127.0.0.1:9200/_cat/indices?v

curl -XGET http://127.0.0.1:9200/sensor/_search?pretty=true
Flink中的Windows
Windows概述
一般真实的流都是无解的 怎么处理无解的数据?
可以把无限的流进行切分 得到有限的数据流进行处理 也就是得到了有界流
窗口是将无限流切割为有限流的一种方式
它会将流数据分发到有限大小的通(bucket)中进行分析
Windows类型
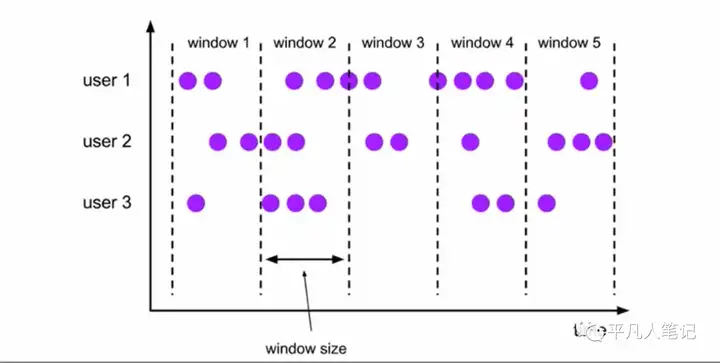
时间窗口(Time window)将数据依据固定的窗口长度对数据进行切分时间堆积 窗口长度固定 没有重叠滚动事件窗口(Tumbling Windows)
滚动窗口分配器将每个元素分配到一个指定窗口的窗口中 滚动窗口有一个固定的大小 并且不会出现重叠
例如指定了5分钟大小的滚动窗口 窗口的创建如何所示
适用场景:
适合做BI统计等(每个时间段的聚合计算)
滑动事件窗口
滑动窗口分配器将元素分配到固定元素的窗口中 与滚动窗口类似
窗口的大小由窗口大小参数配置
另一个滑动窗口参数控制滑动窗口开始的频率
因此滑动窗口如果滑动参数小于窗口大小的话 窗口是可以重叠的
在这种情况下会被分配到多个窗口中
例如:
有10分钟的窗口和5分钟的滑动 那么窗口中每5分钟的窗口里包含着上个10分钟产生的数据
滑动窗口是固定窗口的更广义的一种形式 滑动窗口由固定的窗口长度和滑动间隔组成窗口的长度固定 可以由重叠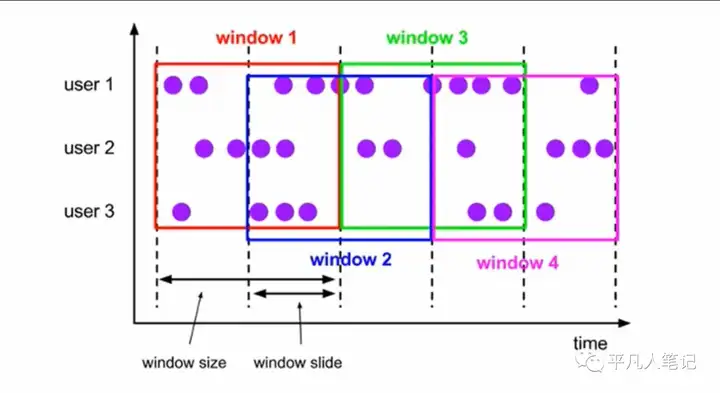
适用场景:
对最近一段时间内的统计(求某接口最近 5min的失败率来决定是否要报警)
会话窗口
session窗口分配器通过session活动来对元素进行分组
session窗口根滚动窗口和滑动窗口相比
不会有重叠和固定的开始时间和结束时间的情况
相反 当它在一个固定的时间周期内不再收到元素 即非活动间隔产生
那么这个窗口就会关闭
一个session窗口通过一个session间隔来配置
这个session间隔定义了非活跃周期的长度 当这个非活跃周期产生 那么当前session将关闭并且后续的元素将会被分配到新的session窗口中去
由一系列事件组合一个指定时间长度的timeout间隙组成 类似于web应用的session 也就是一段时间内没有接收到新数据就会生成新窗口特点:时间无对齐
Windows API
窗口分配器 window()可以用 .window()定义一个窗口
基于这个window去做一些聚合或者其他处理操作
注意:这个方法必须在keyBy之后才能用
Flink提供了更简单的方法 .timeWindow(时间窗口)和.countWindow(计数窗口)
代码
val minTempPerWindow = dataStream
.map(r => (r.id, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(15))
.reduce((r1, r2) => (r1._1, r1._2.min(r2._2)))
窗口分配器(window assigner)滚动窗口(tumbling window)滑动窗口(sliding window)会话窗口(session window)全局窗口(global window)window方法接受的输入参数是一个 WindowAssignerWindowAssigner负责将每条输入的数据分发到正确的window中Flink提供了通用的 WindowAssigner创建不同类型的窗口– 滚动时间窗口(tumbling time window)
.timeWindow(Time.seconds(15))
– 滑动事件窗口(sliding time window)
.timeWindow(Time.seconds(15), Time.seconds(5))
– 会话窗口(session window)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
– 滚动计数窗口(tumbling count Window)
.countWindow(5)
– 滑动计数窗口(sliding count window)
.countWindow(10,2)
窗口函数
window function 定义了要对窗口中收集的数据做的计算操作
增量聚合函数(incremental aggregation functions)每条数据到来就进行计算 保持一个简单的状态
全窗口函数(full window functions)先把窗口所有数据收集起来 等到计算的时候会遍历所有数据
其他可选API
.trigger()一触即发定义了window什么时候关闭 触发计算并输出结果
.evitor 移除器定义了移除某些数据的逻辑
.allowLateness()允许处理迟到的数据
.sideOutputLateData()将迟到的数据放入侧输出流
.sideOutputLateData()将迟到的数据放入侧输出流

THE END

















暂无评论内容