
前言
Spark Streaming 准确来说算是一个微批处理伪实时的做法,可是 Flink 是真的来一条就会处理一条,而且在 Spark Streaming 和 Kafka 进行整合时我们需要手动去管理偏移量的问题,而在 Flink 当中,它就会自动地去帮助我们去管理。
而且 Flink 的算子比 Spark Streaming 的丰富多了,Flink是未来的趋势,起码我是这么认为的
一、Flink基础
Flink起源于一个名为Stratosphere的研究项目,目的是构建下一代的大数据分析平台,于14年4月16日成为Apache的孵化项目。
对于实时的程序,我们关注的点其实有下面3个,分别是数据的输入,数据的处理与数据的输出。下面的图是来自 Flink 1.9版本 官方网站的图
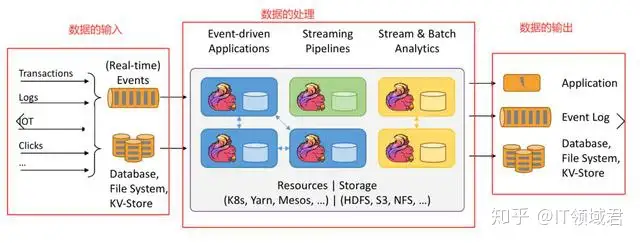
这图就分割得十分清楚了,前面数据的输入这一块,有两种数据来源,一种是Real-Time Events带来的,这种是属于实时方向的,而下方的DataBase,FileSystem,和kv类型的存储系统就是离线方向的业务
数据的处理中写着我们的 Flink 可以被部署在K8s,Yarn,Mesos···等,后面的输出有可能是一个Application,应用的意思,也有可能是Event log,比如Kafka嘛,也有可能又给带回去前面提到的持久化组件中。
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
1.1 Flink 的四个特点
1.1.1 Flink的数据处理思想
Flink认为数据的处理就是流处理,数据可分为有界或者无界两种。
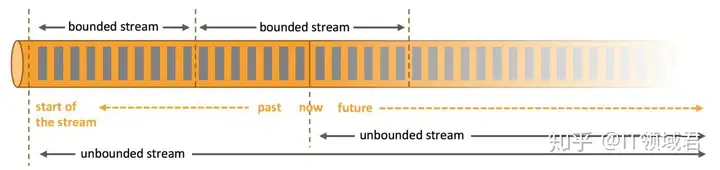
在最一开始的时候,Spark只存在RDD这么一说,之后Flink的那套出来后Spark就借鉴过去了,Flink是靠实时起家的,因为这玩意一开始搞离线也搞不过Spark。所以它们其实也挺相爱相杀的
1.1.2 多场景的部署方式
Apache Flink 它需要计算资源来执行应用程序。Flink 集成了所有常见的集群资源管理器,例如 Hadoop YARN、 Apache Mesos 和 Kubernetes,但同时也可以作为独立集群运行。
Flink 被设计为能够很好地工作在上述每个资源管理器中,这是通过资源管理器特定(resource-manager-specific)的部署模式实现的。Flink 可以采用与当前资源管理器相适应的方式进行交互。
部署 Flink 应用程序时,Flink 会根据应用程序配置的并行性自动标识所需的资源,并从资源管理器请求这些资源。在发生故障的情况下,Flink 通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信都是通过 REST 调用进行的,这可以简化 Flink 与各种环境中的集成
1.1.3 数据的多种规模应用
Flink 旨在任意规模上运行有状态流式应用。因此,应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO。
而且 Flink 很容易维护非常大的应用程序状态。其异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。Flink 可以做到
每天处理数万亿的事件 可以维护几TB大小的状态 可以部署上千个节点的集群 复制代码
1.1.4 充分利用内存的性能
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
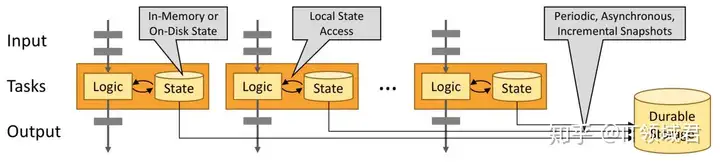
1.2 Flink架构
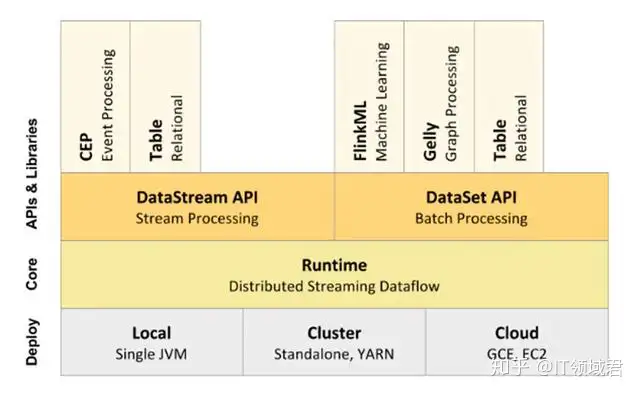
1.3 Flink的小案例
我们实时统计每隔1秒统计最近2秒单词出现的次数,建议使用IDEA去开发
1.3.1 添加POM依赖
1.3.2 Java代码开发
在这里我们使用了Java来进行开发,其实使用Scala也行,不过其实企业中大部分都是使用Java的
敲代码的时候注意导包的时候别导了Scala的
public class WindowWordCountJava { public static void main(String[] args) throws Exception { // Flink提供的获取传递的参数的工具类 ParameterTool parameterTool = ParameterTool.fromArgs(args); String hostname = parameterTool.get(“hostname”); int port = parameterTool.getInt(“port”); //步骤一:获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //步骤二:获取数据源 DataStream
Scala的版本
也是添加Flink的Scala依赖,Scala开发依赖和编译插件
1.9.0 2.11.8
Scala重写刚刚的逻辑
import org.apache.flink.api.java.utils.ParameterTool import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.windowing.time.Time /** * 滑动窗口 * 每隔1秒钟统计最近2秒内的数据,打印到控制台。 */ object WindowWordCountScala { def main(args: Array[String]): Unit = { //获取参数 val hostname = ParameterTool.fromArgs(args).get(“hostname”) val port = ParameterTool.fromArgs(args).getInt(“port”) //TODO 导入隐式转换 import org.apache.flink.api.scala._ //步骤一:获取执行环境 val env = StreamExecutionEnvironment.getExecutionEnvironment //步骤二:获取数据源 val textStream = env.socketTextStream(hostname,port) //步骤三:数据处理 val wordCountStream = textStream.flatMap(line => line.split(“,”)) .map((_, 1)) .keyBy(0) .timeWindow(Time.seconds(2), Time.seconds(1)) .sum(1) //步骤四:数据结果处理 wordCountStream.print() //步骤六:启动程序 env.execute(“WindowWordCountScala”) } } 复制代码
1.4 local模式安装
安装jdk,配置JAVA_HOME,建议使用jdk1.8以上安装包下载地址:http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.9.1/flink-1.9.1-bin-scala_2.11.tgz直接上传安装包到服务器解压安装包:tar -zxvf flink-1.9.1-bin-scala_2.11.tgz创建快捷方式: ln -s flink-1.9.1-bin-scala_2.11.tgz flink配置FLINK_HOEM环境变量启动服务local模式,什么配置项都不需要配,直接启动服务器即可cd $FLIKE_HOME./bin/start-cluster.sh 启动服务./bin/stop-cluster.sh 停止服务Web页面浏览localhost:8081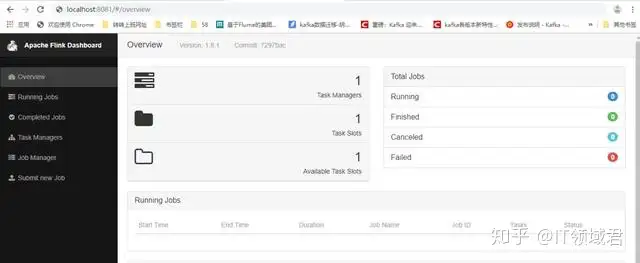
1.5 Standalone模式安装
1.5.1 集群规划
主机名JobManagerTaskManagerhadoop01是hadoop02是hadoop03是
1.5.2 依赖
jdk1.8以上,配置JAVA_HOME
主机之间免密码
flink-1.9.1-bin-scala_2.11.tgz
1.5.3 安装步骤
修改conf/flink-conf.yamljobmanager.rpc.address: hadoop01修改conf/slaveshadoop02hadoop03拷贝到其他节点scp -rq /usr/local/flink-1.9.1 hadoop02:/usr/localscp -rq /usr/local/flink-1.9.1 hadoop03:/usr/local在hadoop01(JobMananger)节点启动start-cluster.sh访问http://hadoop01:80811.5.4 StandAlone模式需要考虑的参数
jobmanager.heap.mb — jobmanager 节点可用的内存大小taskmanager.heap.mb — taskmanager 节点可用的内存大小taskmanager.numberOfTaskSlots — 每台机器可用的cpu数量parallelism.default — 默认情况下任务的并行度taskmanager.tmp.dirs — taskmanager的临时数据存储目录1.6 Flink on Yarn模式安装
flink on yarn有两种方式:
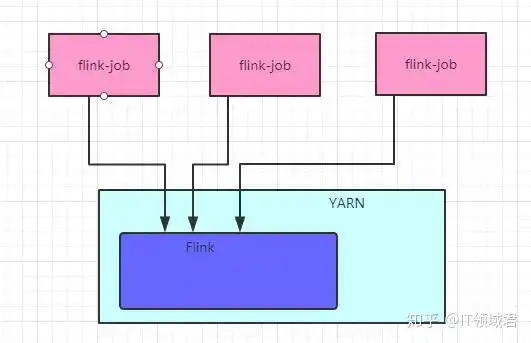
1.6.1 第一种方式
在YARN里面启动一个flink集群,然后我们再往flink集群提交任务,除非把Flink集群停了,不然资源不会释放,这种方式会造成资源的浪费
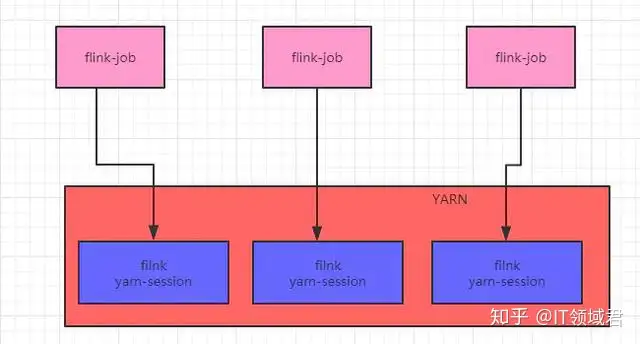
1.6.2 第二种方式
每提交一个任务就在yarn上面启动一个flink小集群(推荐使用),任务运行完了资源就自动释放
1.7 不同模式的任务提交
1.7.1 yarn-session.sh(开辟资源)+flink run(提交任务)
这种方式是基本不会使用的,所以就不说明了
启动一个一直运行的flink集群 /bin/yarn-session.sh -n 2 -jm 1024 -tm 1024 [-d] 把任务附着到一个已存在的flink yarn session •./bin/yarn-session.sh -id application_1463870264508_0029 •执行任务 •./bin/flink run ./examples/batch/WordCount.jar -input hdfs://hadoop100:9000/LICENSE -output hdfs://hadoop100:9000/wordcount-result.txt 停止任务 【web界面或者命令行执行cancel命令】 复制代码
1.7.2 flink run -m yarn-cluster(开辟资源+提交任务)
启动集群,执行任务 ./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar 复制代码
这里只要知道yjm就是Yarn JobManager,ytm就是Yarn taskManager即可,还有其它一些相关参数的含义百度可以搜索得到
Options for yarn-cluster mode: -d,–detached 以独立模式运行任务 -m,–jobmanager
Finally
下一篇开始介绍算子
小编今天就分享到这里了,希望大家喜欢,想看下一篇介绍算子的文章记得关注我奥,请大家提携小编,转发关注走起(最大的支持,嘿嘿)
小编也给大家准备了一些Flink的学习资料,希望能够对大家有帮助,想获取资料的可以私信小编“学习”进行获取!感谢大家阅读!

















暂无评论内容