

作业调度
作业提交给 JobManager 生成 ExecutionGraph 之后,就进入了作业调度执行的阶段。在作业调度阶段中,调度器根据调度模式选择对应的调度策略,申请所需要的资源,将作业发布到 TaskManager 上,启动作业执行,作业开始消费数据,执行业务逻辑。在作业的整个执行过程中,涉及计算任务的提交、分发、管理和容错。
调度
调度器是 Flink 作业执行的核心组件,管理作业执行的所有相关过程,包括 JobGraph 到 ExecutionGraph 的转换、作业生命周期管理(作业的发布、取消、停止)、作业的 Task 生命周期管理( Task 的发布、取消、停止) 、资源申请与释放、作业和 Task 的容错等。
在调度相关的体系中有几个非常重要的组件。
调度器:SchedulerNG 及其子类、实现类。调度策略:SchedulingStrategy 及其实现类。调度模式:ScheduleMode 包含流和批的调度,有各自不同的调度模式。1、调度器
作业调度器是作业的执行、异常处理的核心,具备如下基本能力。
作业的生命周期管理,如作业开始调度、挂起、取消。作业执行资源的申请、分配、释放。作业的状态管理,作业发布过程中的状态变化和作业异常时的容错等。作业的信息提供,对外提供作业的详细信息。在 Flink 中有两个调度器的实现。
DefaultScheduler
该调度器是当前版本的默认调度器,是 Flink 新的调度设计,使用 SchedulerStrategy 来实现调度。
LegacyScheduler
该调度器是遗留的调度器,实际上使用了原来的 ExecutionGraph 的调度逻辑,在后文中不再阐述该调度器的调度过程。
2、调度行为
SchedulerStrategy 接口定义了调度行为,其中定义了四种行为。
startScheduling:调度入口,触发调度器的调度行为。restartTasks:重启执行失败的 Task,一般是 Task 执行异常导致的。onExcutionStateChange:当 Execution 的状态发生改变时。onPartitionConsumable:当 IntermediateResultPartition 中的数据可以消费时。3、调度模式
Flink 一共提供了 3 种调度模式:Eager 调度、分阶段调度、分阶段 Slot 重用调度。不同的调度模式分别适用于不同的场景。
Eager 调度
该模式适用于流计算。一次性申请所有需要的资源,如果资源不足,则作业启动失败。
分阶段调度
分阶段调度(Lazy_From_Sources)适用于批处理。从 Source Task 开始分阶段调度,申请资源的时候,一次性申请本阶段所需要的所有资源。上游 Task 执行完毕后开始调度执行下游的 Task,读取上游的数据,执行本阶段的计算任务,执行完毕之后,调度后一个阶段的 Task,依次进行调度,直到作业执行完成。
分阶段 Slot 重用调度
分阶段 Slot 重用调度(Lazy_From_Sources_With_Batch_Slot_Request)适用于批处理,与分阶段调度基本一样,区别在于该模式下使用批处理资源申请模式,可以在资源不足的情况下执行作业,但是需要确保在本阶段的作业执行中没有 Shuffle 行为。
4、调度策略
流和批的调度策略是不同的,如流计算作业在调度的时候需要一次性获取所有需要的Slot,部署 Task 并开始执行,而对于批处理作业,则可以分阶段调度执行,上一阶段执行完毕,数据可消费的时候,开始调度下游的执行。
调度策略目前有两种实现。
EagerSchedulerStrategy :该调度策略用来执行流计算作业的调度。LazyFromSourceSchedulingStrategy:该调度策略用来执行批处理作业的调度。作业生命周期
关键组件
1.JobMaster
在新版本的 Flink 中已经没有 JobManager 这个类对象,取而代之的是 JobMaster。而 JobManagerRunner 则依然延续旧的名称,用于启动 JobMaster,提供作业级别的 leader 选举、处理异常。旧版本中 JobManager 的作业调度、管理等逻辑现在由 JobMaster 实现。在之前的实现中所有的作业共享 JobManager,引入 JobMaster 之后,一个 JobMaster 对应于一个作业,一个 JobManager 中可以有多个 JobMaster,这样的实现能够更好地隔离作业,减少相互影响的可能性。
现在提到 JobManager 的时候,其实是说 Flink 的 JobManager 角色,是一个独立运行的进程,该进程中包含了一系列的服务,如 Dispatcher、ResourManager 等。
JobMaster 负责单个作业的管理,提供了对作业的管理行为,允许通过外部的命令干预作业的运行,如提交、取消等。同时 JobMaster 也维护了整个作业及其 Task 的状态,对外提供对作业状态的查询功能。JobMaster 负责接收 JobGraph,并将其转换为 ExecutionGraph ,启动调度器执行 ExecutionGraph 。
1、调度执行和管理
将 JobGraph 转化为 ExecutionGraph ,调度 Task 的执行,并处理 Task 的异常,进行作业恢复或者中止。根据 TaskManager 汇报的状态维护 ExecutionGraph 。
InputSplit 分配在批处理中使用,为批处理计算任务分配待计算的数据分片。
结果分区跟踪
结果分区跟踪器 (PartitionTracker) 跟踪非 Pipelined 模式的分区,其实就是跟踪批处理中的结果分区,当结果分区消费完之后,具备结果分区释放条件时,向 TaskExeculor 和 ShuffleMaster 发出释放请求。
作业执行异常
根据作业的执行异常,选择重启作业或者停止作业。
2、作业 Slot 资源管理
Slot 资源的申请、持有和释放。JobMaster 将具体的管理动作交给 SlotPool 来执行,SlotPool 持有资源,资源不足时负责 与 ResourceManager 交互申请资源。
释放 TaskManager 的情况:作业停止、闲置 TM、TM 心跳超时。
3、检查点与保存点
CheckpointCoordinator 负责进行检查点的发起、完成确认,检查点异常或者重复时取消本次检查点的执行。保存点由运维管理人员手动触发或者通过接口调用触发。
4、监控运维相关
反压跟踪、作业状态、作业各算子的吞吐量等监控指标。
5、心跳管理
JobMaster、ResourceManager、TaskManager 是三个分布式组件,相互之间通过网络进行通信,那么不可避免地会遇到各种导致无法通信的情况。所以三者之间通过两两心跳相互感知对方。对方一旦出现心跳超时,则进入异常处理阶段,或是进行切换,或是进行资源清理。
2.TaskManager
TaskManager 是 Flink 集群中负责执行计算任务的角色,其实现类是 TaskExecutor。
TaskExecutor 是 Flink 中非常重要的角色,绝大部分组件都与 TaskExecutor 有关系,其在生命周期中需要对外与 JobManager、ResourceManager 进行通信,对内需要管理 Task 及其相关的资源,结果分区等。
TaskManager 是 Task 的载体,负责启动、执行、取消 Task,并在 Task 异常时向 JobManager 汇报。TaskManager 作为 Task 执行者,为 Task 之间的数据交换提供基础框架。
从集群资源管理的角度,TaskManager 是计算资源的载体,一个 TaskManger 通过 Slot 切分其 CPU、内存等计算资源。
为了实现 Exactly-Once 和容错,从整个集群的视角来看。JobManager 是检查点的协调管理者,TaskManager 是检查点的执行者。
从集群管理的角度,TaskManager 和 JobManager 之间通过心跳保持相互感知。与 ResourceManager 保持心跳,汇报资源的使用情况,以便 ResourceManager 能够掌握全局资源的分布和剩余情况。集群内部的信息交换基于 Flink 的 RPC 通信框架。
TaskManager 提供数据交换基础框架,最重要的是跨网络的数据交换、内存资源的申请和分配以及其他需要在计算过程中 Task 共享的组件,如 ShuffleEnvironment 等。
Task
Task 是 Flink 作业的子任务,由 TaskManager 直接负责管理调度,为 StreamTask 执行业务逻辑的时候提供基础的组件,如内存管理器、IO管理器、输入网关、文件缓存等。
TaskManager、Task、StreamTask 和 算子的关系如下图所示。
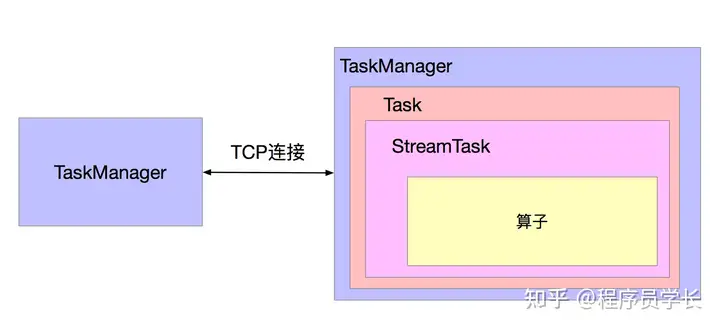
Flink 中流计算执行层面使用 StreamTask 体系,批处理执行层面使用 BatchTask 体系,两套体系互不相通,所以通过 Task 可以解耦 TaskManager,使得 TaskManager 本身无须关心计算任务是流计算作业还是批处理作业。未来版本中批流在底层统一为流执行模型之后,此处的抽象其实是可以简化的。
Task 执行所需要的核心组件如下。
TaskStateManager:负责 State 的整体协调。其中封装了 CheckpointResponder,在 StreamTask 中用来跟 JobMaster 交互,汇报检查点的状态。MemoryManager:Task 通过该组件申请和释放内存。LibraryCacheManager:开发者开发的 Flink 作业打包成 jar 提交给 Flink 集群,在 Task 启动的时候,需要从此组件远程下载所需要的 Jar 文件等,在 Task 的类加载器中加载,然后才能够执行业务逻辑。InputSplitProvider:在数据源算子中,用来向 JobMaster 请求分配数据集的分片,然后读取该分片的数据。ResultPartitionConsumableNotifier:结果分区可消费通知器,用于通知消费者,生产者生产的结果分区可消费。PartitionProducerStateChecker:分区状态检查器,用于检查生产端分区状态。TaskLocalStaleStore:在 TaskManager 本地提供 State 的存储,恢复作业的时候,优先从本地恢复,提高恢复速度。但是本地 State 存储的方式可能因为硬件问题丢失,所以如果不能从本地恢复,需要再从可靠分布式存储中恢复。IOManager:IO 管理器,在批处理计算中(如排序、Join等场景),经常会遇到内存中无法放下所有数据的情况,IOManager 就负责将数据溢写到磁盘,并在需要的时候将其读取回来。ShuflleEnvironment:数据交换的管理环境,其中包含了数据写出、数据分区的管理等组件。BroadcastVariableManager:广播变量管理器,Task 可以共享该管理器,通过引用数跟踪广播变量的使用,没有使用的时候则清除。TaskEventDispatcher:任务事件分发器,从消费者任务分发事件给生产者任务。StreamTask
StreamTask 是所有流计算作业子任务的执行逻辑的抽象基类,是算子的执行容器。
StreamTask 的类型与算子的类型一一对应。
StreamTask 的实现分为几类。
TwolnpulStreamTask
两个输入的 StreamTask,对应于 TwoInputStreamOperator
OnelnpulStreamTask
单个输入的 StreamTask,对应于 OneInputStreamOperator
SourceStreamTask
SourceStreamTask 是用在流模式的执行数据读取的 StreamTask
BoundedStreamTask
该 StreamTask 是用在模拟批处理的数据读取行为
SourceReaderStreamTask
SourceReaderStreamTask 用来执行 SourceReaderStreamOperator。用来重构Soruce接口,目前还未实现。
StreamTask 的生命周期有 3 个阶段:初始化、运行、关闭与清理。如下图所示。
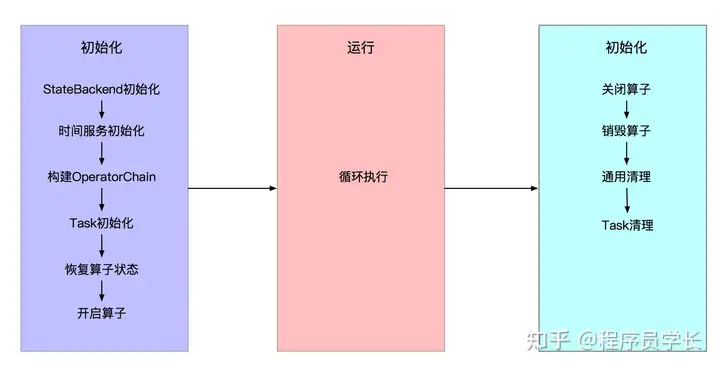
1、初始化阶段
StateBackend 初始化,这是实现有状态计算和 Exactly-Once 的关键组件。
时间服务初始化,此处的时间服务即最终管理定时器的服务。
构建 OperatorChain,实例化各个算子。
算子构建完毕,然后开始 Task 的初始化。根据 Task 的类型的不同,其初始化略有不同。
对于 SourceStreamTask 而言,主要是启动 SourceFunction 开始读取数据,如果支持检查点,则开启检查点。对于 OneInputStreamTask 和 TwoInputStreamTask,构建 InputGate,包装到 StreamTask 的输入组件 StreamTaskNetWorkInput。此处需要注意,StreamTask 之间的数据传递关系由下游的 StreamTask 负责建立数据传输通道,上游的 StreamTask 只负责写入内存。然后初始化 StreamInputProcessor ,将输入(StreamTaskNetWorkInput)、算子处理数据、输出(StreamTaskNetWorkOutput)关联起来,形成 StreamTask 的数据处理完整通道。
之后设置监控指标,使之在运行时能够将各种监控数据与监控模块打通。
对 OperatorChain 中的所有算子恢复状态,如果作业是从快照恢复的,就把算子恢复到上一次保存的快照状态。如果是无状态算子或者作业第一次执行,则无需恢复。
算子状态恢复之后,开启算子,将 UDF 函数加载、初始化进入执行状态。不同的算子也有一些特殊的初始化行为。
2、运行阶段
初始化 StreamTask 完成后,进入运行状态,StreamInputProcessor 持续读取数据,交给算子执行业务逻辑,然后输出。
3、关闭与清理阶段
当作业取消、异常的时候,中止当前的 StreamTask 的执行,StreamTask 进入关闭与清理阶段。
管理 OperatorChain 中的所有算子,同时不再接收新的 Timer 定时器,处理完剩余的数据 ,将算子的数据强制清理。销毁算子,销毁算子的时候,关闭 StateBackend 和 UDF。通用清理,停止相关的执行线程。Task 清理,关闭 StreamInputProcessor ,本质上是关闭了 StreamTaskInput,清理 InputGate,释放序列化器。作业启动
Flink 作业被提交之后,JobManager 中会为每个作业启动一个 JobMaster,并将剩余的工作交给 JobMaster。JobMaster 负责整个作业生命周期中的资源申请释放、调度、容错等细节。
在作业启动过程中,JobMaster 会与 ResourceManager 、TaskManager 频繁交互,经过一系列复杂的过程之后,作业才真正在 Flink 集群中运行起来,进入执行阶段,开始读取、处理、写出数据的过程。
1、JobMaster 启动作业
作业启动涉及 JobMaster 和 TaskManager 两个位于不同进程的组件。在 JobMaster 中完成作业图的转换,为作业申请资源,分配 Slot,将作业的 Task 交给 TaskManager,TaskManager 初始化和启动 Task。通过 JobMaster 管理作业的取消、检查点保存等,Task 在执行过程中持续地向 JobMaster 汇报自身的状况,以便监控和异常时重启作业或者 Task。如下图所示:
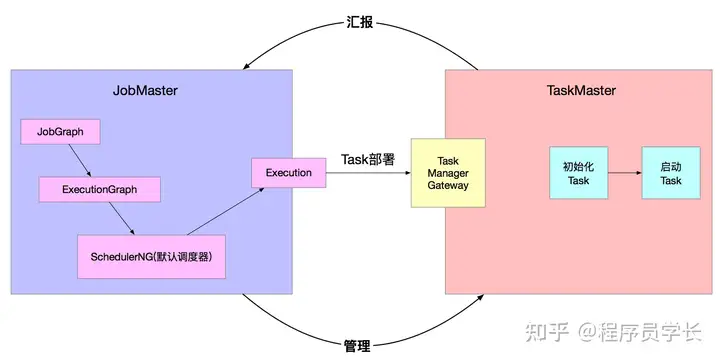
作业调度的入口在 JobMaster 中,由 JobMaster 发起调度。
2、TaskManger 启动 Task
JobMaster 通过 TaskManagerGateway#submit() RPC 接口将 Task 发送到 TaskManager 上,TaskManager 接收到 Task 的部署消息后,分为两个阶段执行:第一个阶段从部署消息获取 Task 执行所需要的信息,初始化 Task,然后触发 Task 的执行,Task 完成一系列的初始化动作后,进入 Task 执行阶段。在部署和执行的过程中,TaskExecutor 与 JobMaster 保持交互,将 Task 的状态汇报给 JobMaster,并接受 JobMaster 的 Task 管理操作。
Task 启动
Task 部署TaskManager 的实现类是 TaskExecutor,JobMaster 将 Task 的部署信息封装为 TaskDeploymentDescriptor 对象,通过 SubmitTask 消息发送给 TaskExecutor。而处理该消息的入口方法是 SubmitTask。
该方法的核心逻辑是初始化 Task。
启动 Task在上一个阶段中,TaskExecutor 准备好了 Task,然后进入 Task 的执行阶段。在这个阶段中,Task 被分配到单独的线程中,循环执行。
Task 是容器,其中 StreamTask 才是用户逻辑执行的起点。在 Task 中通过反射机制实例化 StreamTask 的子类,触发 StreamTask#invoke() 启动真正业务逻辑的执行。
StreamTask 启动
StreamTask 是算子的执行容器。在 JobGraph 中将算子连接在一起进行了优化,在执行层面上对应的是 OperatorChain。在 Task 启动前,无论是单个算子还是连接在一起的一组算子,都会首先被构造成 OperatorChain,构造 OperatorChain 的过程中,包含了算子的实例化,同时也构造了算子的输出(Output)。
因为不符合链接条件,所以 Source 算子 和 FlatMap 算子都是单个的算子,单个算子构成的 OperatorChain 如下图所示:
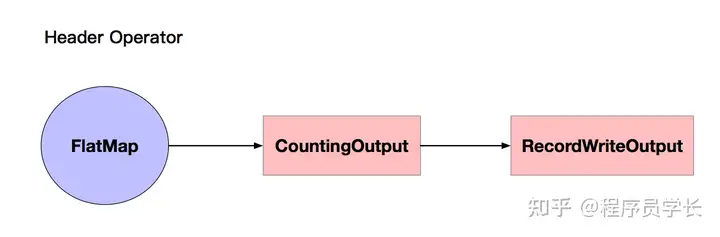
算子输出计算结果的时候,包含了两层 Output,其中 CountingOutput 用来统计算子的输出数据元素个数,RecordWriterOutput 用来序列化数据,写入 NetworkBuffer ,交给下游算子,同时计算两个监控指标:向下游发送的字节总数、向下游发送的 Buffer 总数。
KeyedAgg 算子和 Flink 算子符合算子链接的条件,构成两个算子的 OperatorChain,如下图所示:
两个或以上算子构成的 OperatorChain,算子之间包含了两层 Output,其中 CountingOutput 用来统计上游算子(KeyedAgg )输出的数据元素个数。ChainingOutPut 提供了 Watermark 的统计和下游算子(sink)的输入数据元素个数。
Task 启动完毕后,就进入了作业执行的阶段。
作业停止
当作业执行完毕(批处理作业)、执行失败无法恢复时就会进入停止状态。同时在一些场景中,也需要将作业手动停止,如集群升级、作业升级、作业迁移等,此时作业都会进入停止状态。与作业的启动相比,作业的停止要简单许多,主要是资源的清理和释放。
JobMaster 向所有的 TaskManager 发出取消作业的指令,TaskManager 执行 Task 的取消指令,进行相关的内存资源的清理,当所有的清理作业完成之后,向 JobMaster 发出通知,最终 JobMaster 停止,向 ResourceManager 归还所有的 Slot 资源,然后彻底退出作业的执行。
作业失败调度
Flink 作为低延迟的分布式计算引擎 ,在流计算中引入了分布式快照容错机制,以满足低延迟和高吞吐的要求。
Flink 所使用的容错机制是:使用分布式快照保存作业状态,与 Flink 作业恢复机制相结合,确保数据不丢失、不重复处理。发生错误时,Flink 作业能够根据重启策略自动从最近一次成功的快照中恢复状态。
Flink 对作业失败的原因做了归纳定义,有如下 4 种类型。
NonRecoverableError 不可恢复的错误。PartitionDataMissError 分区数据不可访问错误。下游 Task 无法读取上游 Task 产生的数据,需要重启上游的 Task。EnvironmentError 环境的错误。RecoverableError 可恢复的错误。默认作业失败调度
在错误发生时,首先会尝试对作业进行局部恢复,如果无法恢复或者局部恢复失败,则会将整个作业进行重启,从保存快照中恢复。
默认失败调度集成在默认调度器 DefaultScheduler, 具体的调度行为代理给 ExecutionGraph 来实现。
在运行时,Task 是 Flink 作业的最小执行单位,一个作业有不定数量的 Task,取决于计算逻辑的复杂度和并行度。可能使 Task 出问题的错误非常多,如机器故障、用户代码逻辑中未处理的异常、网络故障等。
在 Flink 的 DefaultScheduler 和细粒度的恢复策略中,Task 错误恢复策略定义如下。
RestartAllStrategy:若 Task 发生异常,则重启所有的 Task,恢复成本高,但其是恢复作业一致性的最安全策略。RestartPipelinedRegionStrategy:分区恢复策略,若 Task 发生异常,则重启该分区的所有 Task,恢复成本低,实现逻辑复杂。

















暂无评论内容