Flink的Transformation转换主要包括四种:单数据流基本转换、基于Key的分组转换、多数据流转换和数据重分布转换。读者可以使用Flink Scala Shell或者Intellij Idea来进行练习:
Flink Scala Shell使用教程Intellij Idea开发环境搭建教程Flink单数据流基本转换:map、filter、flatMapFlink基于Key的分组转换:keyBy、reduce和aggregations
很多情况下,我们需要对多个数据流进行整合处理,Flink为我们提供了多流转换算子,本文主要介绍多流转换。
union
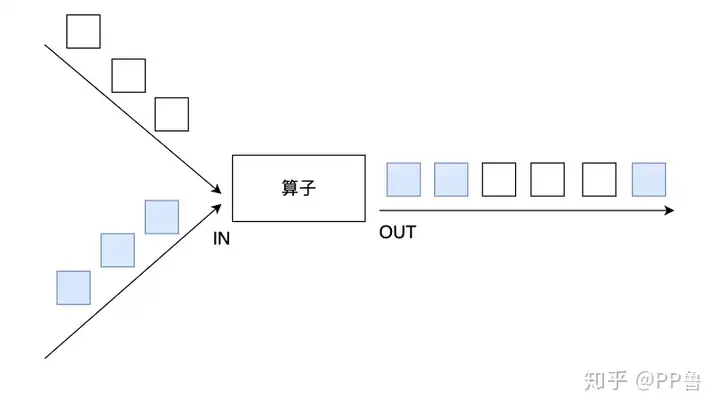
在DataStream上使用union算子可以合并多个同类型的数据流,并生成同类型的数据流,即可以将多个DataStream[T]合并为一个新的DataStream[T]。数据将按照先进先出(First In First Out)的模式合并,且不去重。下图union对白色和深色两个数据流进行合并,生成一个数据流。
假设股票价格数据流来自不同的交易所,我们将其合并成一个数据流:
val shenzhenStockStream: DataStream[StockPrice] = …
val hongkongStockStream: DataStream[StockPrice] = …
val shanghaiStockStream: DataStream[StockPrice] = …
val unionStockStream: DataStream[StockPrice] = shenzhenStockStream.union(hongkongStockStream, shanghaiStockStream)
connect
union虽然可以合并多个数据流,但有一个限制,即多个数据流的数据类型必须相同。connect提供了和union类似的功能,用来连接两个数据流,它与union的区别在于:
connect只能连接两个数据流,union可以连接多个数据流。connect所连接的两个数据流的数据类型可以不一致,union所连接的两个数据流的数据类型必须一致。两个DataStream经过connect之后被转化为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,且双流之间可以共享状态。
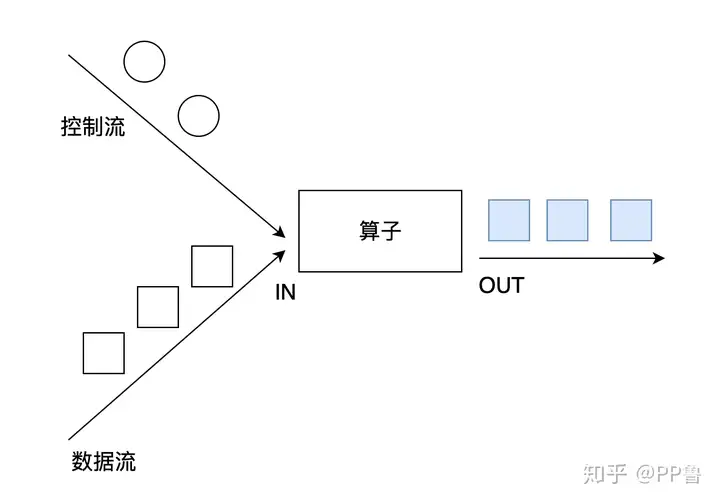
connect经常被应用在对一个数据流使用另外一个流进行控制处理的场景上,如下图所示。控制流可以是阈值、规则、机器学习模型或其他参数。
对于ConnectedStreams,我们需要重写CoMapFunction或CoFlatMapFunction。这两个接口都提供了三个泛型,这三个泛型分别对应第一个输入流的数据类型、第二个输入流的数据类型和输出流的数据类型。在重写函数时,对于CoMapFunction,map1处理第一个流的数据,map2处理第二个流的数据;对于CoFlatMapFunction,flatMap1处理第一个流的数据,flatMap2处理第二个流的数据。Flink并不能保证两个函数调用顺序,两个函数的调用依赖于两个数据流数据的流入先后顺序,即第一个数据流有数据到达时,map1或flatMap1会被调用,第二个数据流有数据到达时,map2或flatMap2会被调用。下面的代码对一个整数流和一个字符串流进行了connect操作。
val intStream: DataStream[Int] = senv.fromElements(1, 0, 9, 2, 3, 6)
val stringStream: DataStream[String] = senv.fromElements(“LOW”, “HIGH”, “LOW”, “LOW”)
val connectedStream: ConnectedStreams[Int, String] = intStream.connect(stringStream)
// CoMapFunction三个泛型分别对应第一个流的输入、第二个流的输入,map之后的输出
class MyCoMapFunction extends CoMapFunction[Int, String, String] {
override def map1(input1: Int): String = input1.toString
override def map2(input2: String): String = input2
}
val mapResult = connectedStream.map(new MyCoMapFunction)
我们知道,如果不对DataStream按照Key进行分组,数据是随机分配在各个TaskSlot上的,而绝大多数情况我们是要对某个Key进行分析和处理,Flink允许我们将connect和keyBy或broadcast结合起来使用。例如,我们将之前的股票价格数据流与一个媒体评价数据流结合起来,按照股票代号进行分组。
// 先将两个流connect,再进行keyBy
val keyByConnect1: ConnectedStreams[StockPrice, Media] = stockPriceRawStream
.connect(mediaStatusStream)
.keyBy(0,0)
// 先keyBy再connect
val keyByConnect2: ConnectedStreams[StockPrice, Media] = stockPriceRawStream.keyBy(0)
.connect(mediaStatusStream.keyBy(0))
无论先keyBy还是先connect,我们都可以将含有相同Key的数据转发到下游同一个算子实例上。这种操作有点像SQL中的join操作。Flink也提供了join算子,join主要在时间窗口维度上,connect相比而言更广义一些,关于join的介绍将在后续文章中介绍。
下面的代码展示了如何将股票价格和媒体正负面评价结合起来,当媒体评价为正且股票价格大于阈值时,输出一个正面信号。完整代码在我的github上:https://github.com/luweizheng/flink-tutorials
package com.flink.tutorials.demos.stock
import java.util.Calendar
import com.flink.tutorials.demos.stock.StockPriceDemo.{StockPrice, StockPriceSource, StockPriceTimeAssigner}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.co.RichCoFlatMapFunction
import org.apache.flink.streaming.api.functions.source.RichSourceFunction
import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
import scala.util.Random
object StockMediaConnectedDemo {
def main(args: Array[String]) {
// 设置执行环境
val env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration())
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 每5秒生成一个Watermark
env.getConfig.setAutoWatermarkInterval(5000L)
// 股票价格数据流
val stockPriceRawStream: DataStream[StockPrice] = env
// 该数据流由StockPriceSource类随机生成
.addSource(new StockPriceSource)
// 设置 Timestamp 和 Watermark
.assignTimestampsAndWatermarks(new StockPriceTimeAssigner)
val mediaStatusStream: DataStream[Media] = env
.addSource(new MediaSource)
// 先将两个流connect,再进行keyBy
val keyByConnect1: ConnectedStreams[StockPrice, Media] = stockPriceRawStream
.connect(mediaStatusStream)
.keyBy(0,0)
// 先keyBy再connect
val keyByConnect2: ConnectedStreams[StockPrice, Media] = stockPriceRawStream.keyBy(0)
.connect(mediaStatusStream.keyBy(0))
val alert1 = keyByConnect1.flatMap(new AlertFlatMap).print()
val alerts2 = keyByConnect2.flatMap(new AlertFlatMap).print()
// 执行程序
env.execute(“connect stock price with media status”)
}
/** 媒体评价
*
* symbol 股票代号
* timestamp 时间戳
* status 评价 正面/一般/负面
*/
case class Media(symbol: String, timestamp: Long, status: String)
class MediaSource extends RichSourceFunction[Media]{
var isRunning: Boolean = true
val rand = new Random()
var stockId = 0
override def run(srcCtx: SourceContext[Media]): Unit = {
while (isRunning) {
// 每次从列表中随机选择一只股票
stockId = rand.nextInt(5)
var status: String = “NORMAL”
if (rand.nextGaussian() > 0.9) {
status = “POSITIVE”
} else if (rand.nextGaussian() < 0.05) {
status = “NEGATIVE”
}
val curTime = Calendar.getInstance.getTimeInMillis
srcCtx.collect(Media(stockId.toString, curTime, status))
Thread.sleep(rand.nextInt(100))
}
}
override def cancel(): Unit = {
isRunning = false
}
}
case class Alert(symbol: String, timestamp: Long, alert: String)
class AlertFlatMap extends RichCoFlatMapFunction[StockPrice, Media, Alert] {
var priceMaxThreshold: List[Double] = List(101.0d, 201.0d, 301.0d, 401.0d, 501.0d)
var mediaLevel: String = “NORMAL”
override def flatMap1(stock: StockPrice, collector: Collector[Alert]) : Unit = {
val stockId = stock.symbol.toInt
if (“POSITIVE”.equals(mediaLevel) && stock.price > priceMaxThreshold(stockId)) {
collector.collect(Alert(stock.symbol, stock.timestamp, “POSITIVE”))
}
}
override def flatMap2(media: Media, collector: Collector[Alert]): Unit = {
mediaLevel = media.status
}
}
}





















暂无评论内容