本课目标
安装Flink集群 理解Flink的基本原理 掌握Flink的编程模型 掌握Flink的资源管理
Flink简介
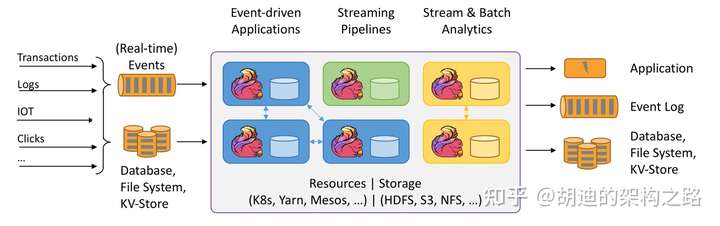
Apache Flink 是一个分布式处理引擎框架,用于在无边界和有边界数据流上进行有状态的计算。 Flink能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。Events -> 一般指的是消息系统(kafka,roketMQ,activeMQ),偏向于实时数据处理 DB,FS,Nosql -> 偏向于数据的批处理SparkStreaming -> 批处理 Flink -> 完全的实时流数据处理
Flink的特性
特性1-处理无界和有界数据
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
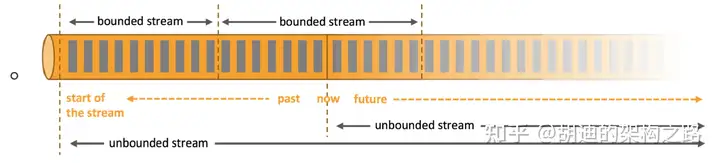
数据可以被作为无界或者有界流来处理。
无界流有定义流的开始 ,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。有界流有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
Apache Flink 擅长处理无界和有界数据集,精确的时间控制和状态化使得 Flink 的运行时(runtime)能够运行任何处理无界流的应用。有界流则由一些专为固定大小数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
特性2-部署应用到任意地方
Apache Flink 是一个分布式系统,它需要计算资源来执行应用程序。Flink 集成了所有常见的集群资源管理器,例如 Hadoop YARN、 Apache Mesos 和 Kubernetes,但同时也可以作为独立集群运行(Standalone模式)。Flink 被设计为能够很好地工作在上述每个资源管理器中,这是通过资源管理器特定(resourcemanager-specific)的部署模式实现的。Flink 可以采用与当前资源管理器相适应的方式进行交互。部署 Flink 应用程序时,Flink 会根据应用程序配置的并行性自动标识所需的资源,并从资源管理器请求这些资源。在发生故障的情况下,Flink 通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信都是通过 REST 调用进行的,这可以简化 Flink 与各种环境中的集成
特性3-运行任意规模应用
Flink 旨在任意规模上运行有状态流式应用。因此,应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO。而且Flink 很容易维护非常大的应用程序状态。其异步和增量的检查点算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
Flink 用户报告了其生产环境中一些令人印象深刻的扩展性数字:
每天处理数万亿的事件 可以维护几TB大小的状态 可以部署上千个节点的集群
特性4-利用内存性能
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
Flink架构图
Flink核心概念
Flink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态计算。Flink被设计成可以在所有常见的集群环境中运行,以内存速度和任何规模执行计算)有状态:每一步计算都是有状态的,会根据前面的状态进行累加
分布式
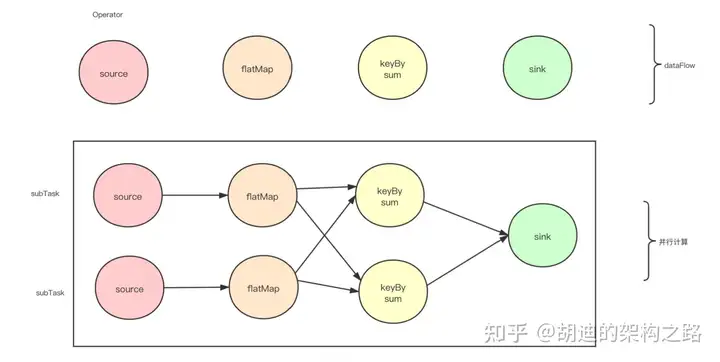
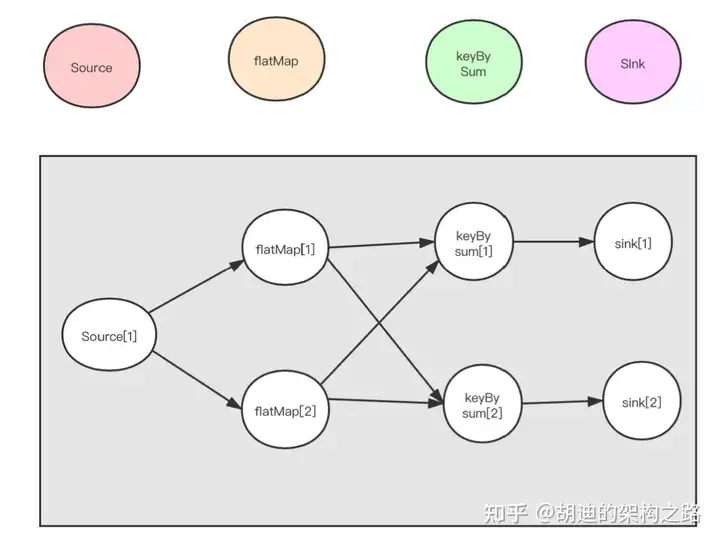
算子( Operator )将一个或多个 DataStream 转换为新的 DataStream 。程序可以将多个转换组合成复杂的数据流拓扑
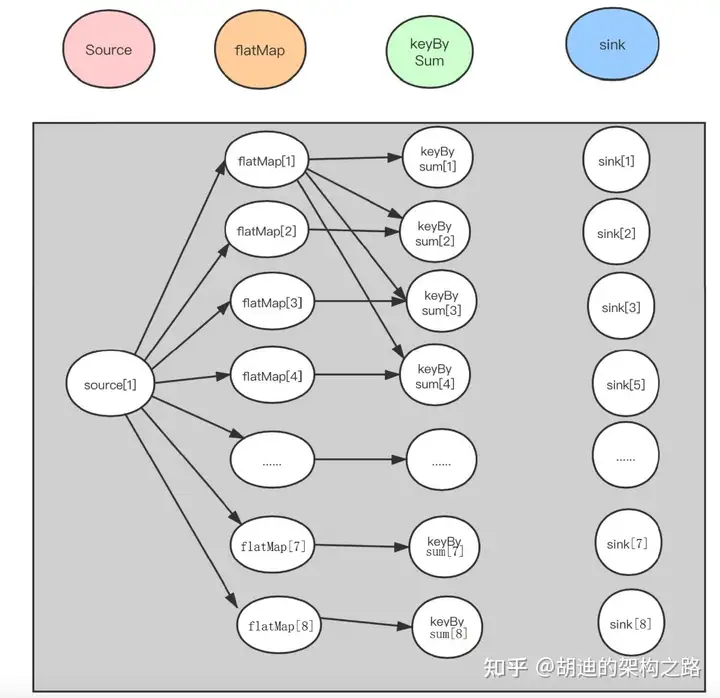
并行度
#案例6,使用默认并行度和设置并行度
/**
* 单词计数:计算并行度
1. 使用默认并行度
2. 自定义并行度为2
* 打开页面:http://localhost:8081
*/
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// env.setParallelism(2);
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String hostname = parameterTool.get(“hostname”);
int port = parameterTool.getInt(“port”);
/**
* socket无论如何就只能有一个并行度
*
*/
DataStreamSource<String> myDataStream = env.socketTextStream(hostname,
port);
SingleOutputStreamOperator<WordAndOne> result = myDataStream.flatMap(new
StringSplitTask())
.keyBy(“word”)
.sum(“count”);
result.print();
env.execute(“word count…”);
}
设置并行度为2:env.setParallelism(2);
集群模式和本地模式安装
Local模式安装(无需任何配置)
#安装jdk,配置JAVA_HOME,建议使用jdk1.8以上
#安装包下载地址: Apache Download Mirrors
1.10.1–bin–scala_2.11.tgz
#解压安装包:tar –zxvf f flink–1.10.1–bin–scala_2.11.tgz
#配置FLINK_HOEM环境变量
#启动服务()
start–cluster.sh 启动服务
stop–cluster.sh 停止服务
#Web页面浏览 http://hadoop1:8081
集群模式安装
1.集群规划
2.安装步骤
#前置要求,jdk1.8以上,配置JAVA_HOME
#安装步骤
1.修改conf/flink–conf.yaml jobmanager.rpc.address: hadoop1
2.修改conf/slaves
hadoop1
hadoop2
hadoop3
3.拷贝到其他节点
scp –r flink–1.10.1 hadoop2:/root/install
在hadoop1节点启动:start–cluster.sh
访问http://hadoop1:8081
4.优化StandAlone模式需要考虑的参数
jobmanager.heap.mb:jobmanager节点可用的内存大小
taskmanager.heap.mb:taskmanager节点可用的内存大小
taskmanager.numberOfTaskSlots:每台机器可用的cpu数量
parallelism.default:默认情况下任务的并行度
taskmanager.tmp.dirs:taskmanager的临时数据存储目录
分布式运行环境
(1) 运行
在hadoop1 上执行 nc –lk 8888
flink run –c com.bw.flinkstreaming.job5.WordCount flink.jar —hostname hadoop1 —
port 8888
(2) 停止任务
方式一:页面上停止
方式二:命令停止
flink cancel job–id
#案例1讲解
提交:flink run –c com.bw.flinkstreaming.job7.WordCount flink.jar —hostname
hadoop1 —port 9999
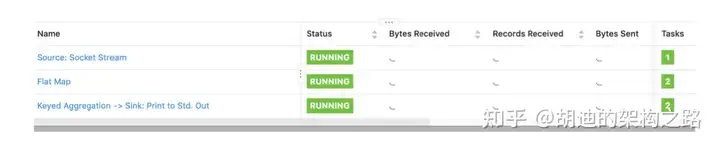
该案例运行结果? 1 2 2 1
#案例3讲解,如果设置并行度都为1那么总共需要几个task
提交:flink run –c com.bw.flinkstreaming.job9.WordCount flink.jar —hostname
hadoop1 —port 9999
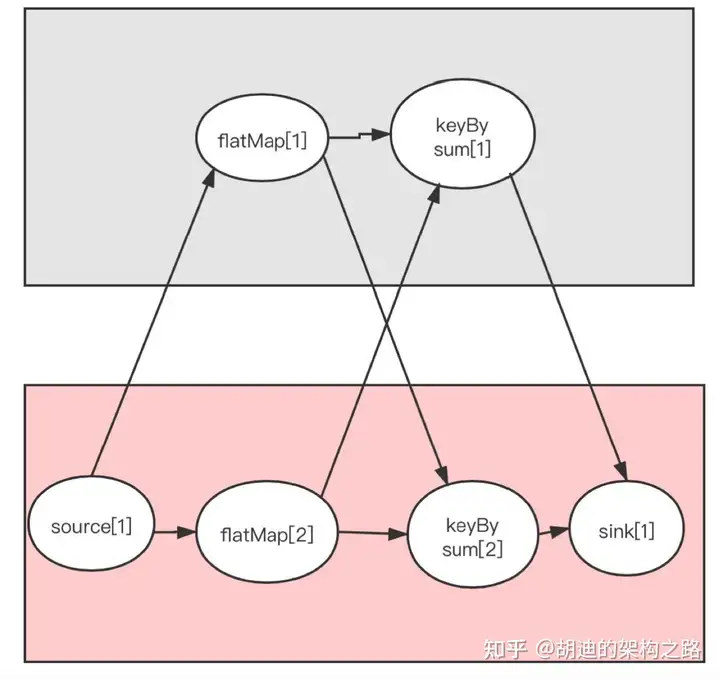
该案例运行结果? 1 2 1
合并了 task
JobManager和TaskManager保持通信
TaskManager里面的Taskslot是运行task的资源(内存,CPU,网络资源等) 默认情况下一个TakaManager只有一个Taskslottask任务运行在Taskslot JobManager会更新task的状态到Client
ActorSystem
保证系统之间通信方式,心跳检测。
TaskManager -> TaskSlot -> task -> 并行度



























暂无评论内容