程序员小王的博客:程序员小王的博客
欢迎点赞 收藏 ⭐留言
如有编辑错误联系作者,如果有比较好的文章欢迎分享给我,我会取其精华去其糟粕
一、Flink的特性
Flink 是第三代分布式流处理器,它的功能丰富而强大。flink是一个分布式,高性能,随时可用的以及准确的流处理计算框架,flink可以对无界数据(流处理)和有界数据(批处理)进行有状态计算(flink天生支持状态计算)的分布式,高性能的计算框架。1、Flink核心特性
Flink 区别与传统数据处理框架的特性如下:
高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。结果的准确性。Flink 提供了事件时间(event-time)和处理时间(processing-time)语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。精确一次(exactly-once)的状态一致性保证。可以连接到最常用的存储系统,如 Apache Kafka、Apache Cassandra、Elasticsearch、JDBC、Kinesis 和(分布式)文件系统,如 HDFS 和 S3。高可用。本身高可用的设置,加上与 K8s,YARN 和 Mesos 的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink 能做到以极少的停机时间 7×24 全天候运行。能够更新应用程序代码并将作业(jobs)迁移到不同的 Flink 集群,而不会丢失应用程序的状态支持带有事件时间的窗口(Window)操作Flink在JVM中实现了自己的内存管理
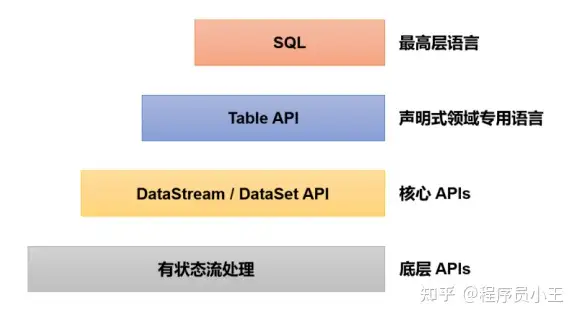
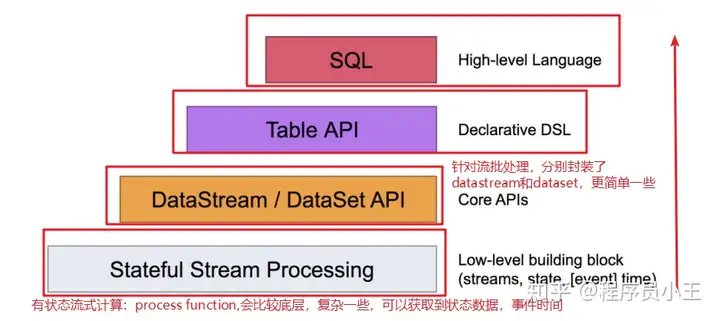
2、分层API
除了上述这些特性之外,Flink 还是一个非常易于开发的框架,因为它拥有易于使用的分层 API,整体 API 分层如图:
大多数应用并不需要上述的底层抽象,而是直接针对核心 API(Core APIs) 进行编程,比如 DataStream API(用于处理有界或无界流数据)以及 DataSet API(用于处理有界
数据集)。这些 API 为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换(transformations)、连接(joins)、聚合(aggregations)、窗口(windows)操作等。
3、大数据技术框架发展阶段
总共有四代:
mr–>DAG框架(tez)—>Spark流批处理框架,内存计算(伪实时)–>flink流批处理,内存计算(真正的实时计算)4、Flink和Spark的区别
5、Flink的基石
flink的四大基石:checkpoint,state,time,windowcheckpoint:基于chandy-lamport算法实现分布式计算任务的一致性语义;state:flink中的状态机制,flink天生支持state,state可以认为程序的中间计算结果或者是历史计算结果;time:flink中支持基于事件时间和处理时间进行计算,spark streaming只能按照process time进行处理;基于事件时间的计算我们可以解决数据迟到和乱序等问题。window:flink提供了更多丰富的window,基于时间,基于数量,session window,同样支持滚动和滑动窗口的计算。6、Flink的流处理和批处理
流处理:无界,实时性有要求,只需对经过程序的每条数据进行处理批处理:有界,持久,需要对全部数据进行访问处理;1. spark:spark生态中是把所有的计算都当做批处理,
spark streaming中流处理本质上也是批处理(micro batch);
2. flink:flink中是把批处理(有界数据集的处理)看成是一个特殊的流处理场景;
flink中所有计算都是流式计算;
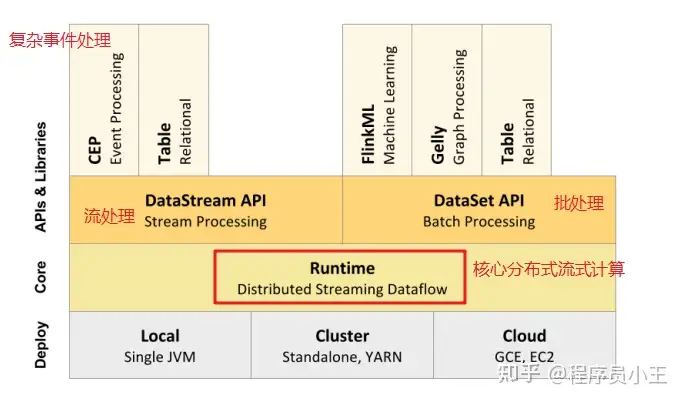
flink技术栈
二、Flink体系结构
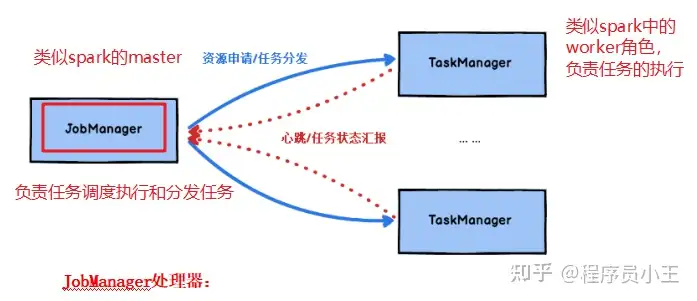
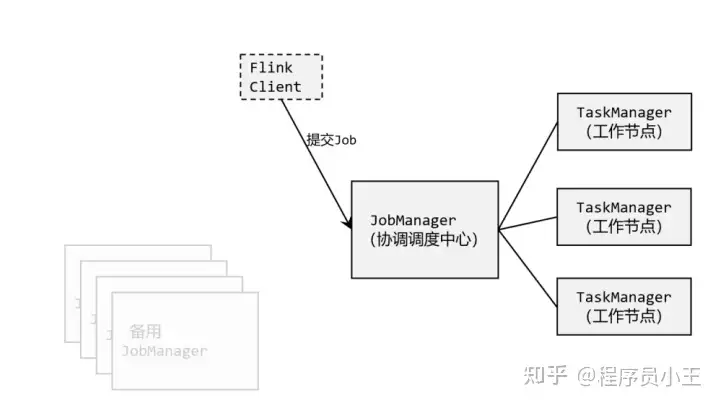
1、Flink的重要角色
JobManager:类似spark中master,负责资源申请,任务分发,任务调度执行,checkpoint的协调执行;可以搭建HA,双master。TaskManager:类似spark中的worker,负责任务的执行,基于dataflow(spark中DAG)划分出的task;与jobmanager保持心跳,汇报任务状态。
客户端(Client)、作业管理器(JobManager)和任务管理器(TaskManager)。
我们的代码,实际上是由客户端获取并做转换,之后提交给JobManger 的。所以 JobManager 就是 Flink 集群里的“管事人”,对作业进行中央调度管理;而它获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的 TaskManager。这里的 TaskManager,就是真正“干活的人”,数据的处理操作都是它们来做的
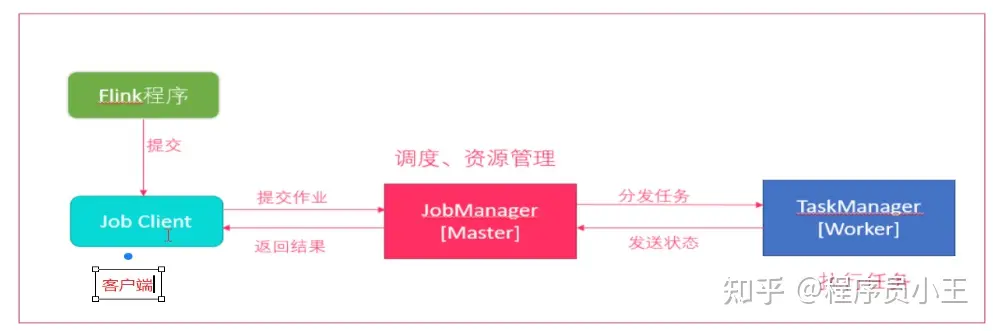
Flink程序由JobClient进行提交
JobClient将作业提交给JobManager
JobManager负责协调资源分配和作业执行。资源分配完成后,任务将提交给相应的TaskManager
TaskManager启动一个线程以开始执行。TaskManager会向JobManager报告状态更改,如开始执行,正在进行或已完成。
作业执行完成后,结果将发送回客户端(JobClient)
2、有界数据和无界数据
无界数据流:数据流是有一个开始但是没有结束;有界数据流:数据流是有一个明确的开始和结束,数据流是有边界的。flink流处理批处理的原理:link支持的runtime(core 分布式
流计算)支持的是无界数据流,
但是对flink来说可以支持批处理,
只是从数据流上来说把有界数据流只是无界数据流的一个特例,
无界数据流只要添加上边界就是有界数据流。
三、Flinl单节点部署和standalone集群搭建
1、Flink的安装模式
local:单机模式,尽量不使用standalone: flink自带集群,资源管理由flink集群管理,开发环境测试使用flink on yarn: 把资源管理交给yarn实现,计算机资源统一由Haoop YARN管理,生产环境测试。2、环境配置
Flink 是一个分布式的流处理框架,所以实际应用一般都需要搭建集群环境。我们在进行
Flink 安装部署的学习时,需要准备 3 台 Linux 机器。具体要求如下:
系统环境为 CentOS 7.5 版本。安装 Java 8。#1. 安装jdk
rpm -ivh jdk-8u171-linux-x64.rpm
#2.搜索默认安装位置
find / -name “java”
#3.配置环境变量
vi /etc/profile
#4.在文末加上配置
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64/
export PATH=$PATH:$JAVA_HOME/bin
#5.加载配置生效
source /etc/profile
#6.测试环境变量
java -version
flink 1.7.2版本配置集群节点服务器间时间同步以及免密登录,关闭防火墙。3、单节点部署
原理
(1)上传安装包然后解压到指定目录,注意修改所属用户和用户组
#1.解压
tar -zxvf flink-1.7.2-bin-hadoop27-scala_2.11.tgz
#2.改名
mv flink-1.7.2 flink
#3.赋予权限
chown -R root:root flink
flink目录结构
(2)去flink的bin目录下启动shell交互式窗口
bin/start-scala-shell.sh local
(3)提交一个任务
准备文件:words.txt测试benv.readTextFile(“/home/user/apps/test/words.txt”).flatMap(_.split(” “)).map((_,1)).groupBy(0).sum(1).print()
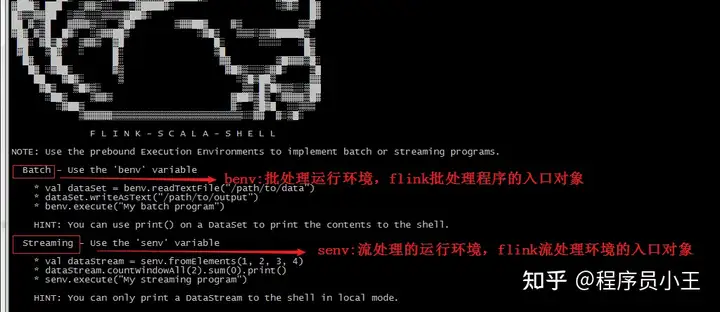
启动scala-shell的现象flink准备了benv,senv,分别是批处理和流处理程序入口对象单节点的flink集群
(4)直接启动
关闭防火墙systemctl stop firewalld
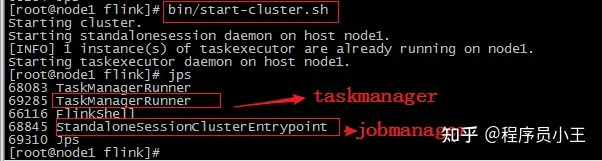
直接启动bin/start-cluster.sh
验证taskmanager,jobmanager进程是否存在[root@node1 flink]# jps
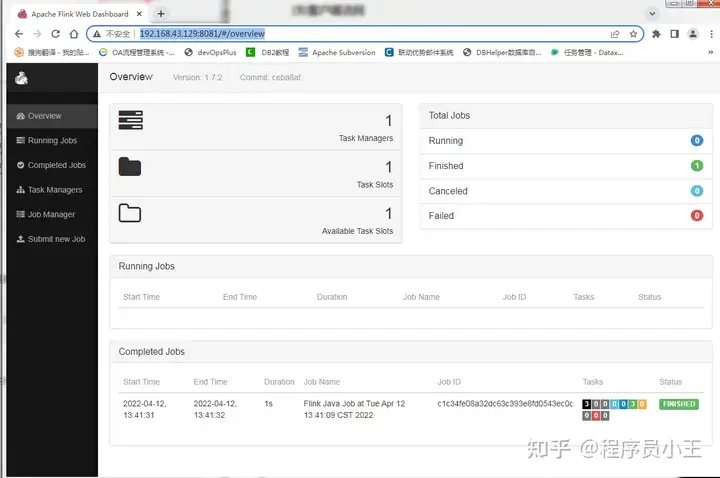
(5)客户端访问
http://192.168.43.129:8081
(6)提交任务到flink 单节点集群
统计/home/user/apps/test/words.txt中的单词数量,(准备数据文件)#四行代码要写在一排,其中要提前准备words.txt,WordCount.jar 自带的,out不用准备
/home/user/apps/flink/bin/flink run
/home/user/apps/flink/examples/batch/WordCount.jar
–input /home/user/apps/test/words.txt
–output /home/user/apps/test/out
查看out中获取的数据注意:如果来回切换模式时可能会遇到提交任务报错的情况:如失败需删除之前的运行信息rm -rf /tmp/.yarn-properties-root
前端页面成功
(7)停止集群
bin/stop-cluster.sh
4、standalone集群
搭建原理:standalone模式是最简单的一种集群模式,不需要yarn、mesos等资源调度平台standalone: flink自带集群,资源管理由flink集群管理,开发环境测试使用集群规划1. 192.168.43.129(master+Slave)
1. 192.168.43.130(Slave)
1. 192.168.43.131(Slave)
(1)修改配置文件 conf/flink-conf.yaml
[root@node1 conf]# vim flink-conf.yaml
修改之前修改之后jobmanager.rpc.address: 192.168.43.129
jobmanager.rpc.port: 6123
jobmanager.heap.size: 1024
taskmanager.heap.size: 1024
taskmanager.numberOfTaskSlots: 2
taskmanager.memory.preallocate: false
parallelism.default: 1
jobmanager.web.port: 8081
taskmanager.tmp.dirs: /home/user/apps/flink/tmp
#页面提交
web.submit.enable: true
(2)修改master文件conf/master
192.168.43.129:8081
(3)修改conf目录下slave文件
#如果自己的ip没有命名,可以这样,如下:
192.168.43.129
192.168.43.130
192.168.43.131
(4)分发flink目录到其它节点
scp -r /home/user/apps/flink 192.168.43.130:/home/user/apps/flink
scp -r /home/user/apps/flink 192.168.43.131:/home/user/apps/flink
scp -r /etc/profile 192.168.43.130:/etc/profile
scp -r /etc/profile 192.168.43.131:/etc/profile
(5)启动集群
bin/start-cluster.sh 停止 bin/stop-cluster.sh
单独启动jobmanager或者taskmanager(启动成功后,可以不启动)bin/jobmanager.sh start/stop
bin/taskmanager.sh start/stop
jps测
(6)部署hadoop及往hadoop上传文件
注意:使用的数据文件是hdfs上,不能是本地文件路径,因为会找不到文件。
hdfs集群部署的方法,参考我的博客:http://t.csdn.cn/ZLLD9 访问:http://192.168.43.129:50070/explorer.html
创建目录:word
首先我们应该上传文件到hdfs文件中#1. 查看hdfs文件系统目录文件
hdfs dfs -ls /wordcount
#2.上传:hdfs dfs -put 本地
文件目录 HDFS文件目录
hdfs dfs -put /usr/apps/word/words.txt /wordcount
#3.删除文件hdfs dfs -rm -r HDFS文件路径
hdfs dfs -rm -r /wordcount
(7)提交任务到standalone集群
/home/user/apps/flink/bin/flink run
/home/user/apps/flink/examples/batch/WordCount.jar
–input hdfs://node1:8020/wordcount/words.txt
–output hdfs://node1:8020/wordcount/output/result.txt –parallelism 2
注意:使用的数据文件是hdfs上,不能是本地文件路径,因为会找不到文件。提交之前,output目录为空提交之后的flink前端:http://192.168.43.129:8081/#/overview
hadoop前端页面下的wordcount/output已经有结果了!前端地址:http://192.168.43.129:50070/explorer.html
四、Flink(standalone HA)集群搭建
2、standalone HA Flink集群搭建
standalone HA:独立高可用集群解决standalone集群的单点故障问题,所以搭建HA集群。(1)原理:
引入zookeeper来完成双主节点,主从切换工作。zookeeper集群搭建步骤参考我的博客:https://blog.csdn.net/weixin_44385486/article/details/124172402
(2)配置hadoop_conf_dir到/etc/profile中
#hadoop_conf_dir
export hadoop_conf_dir=/usr/apps/hadoop/etc/hadoop
(3)停止原先standone集群
bin/stop-cluster.sh
(4)修改conf/flink-conf.yaml
#开启HA,使用文件系统作为快照存储
state.backend: filesystem
#启用检查点,可以将快照保存到HDFS
state.backend.fs.checkpointdir: hdfs://node1:8020/flink-checkpoints
#使用zookeeper搭建高可用
high-availability: zookeeper
# 存储JobManager的元数据到HDFS
high-availability.storageDir: hdfs://node1:8020/flink/ha/
# 配置ZK集群地址
high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181
# 默认是 open,如果 zookeeper security 启用了更改成 creator
high-availability.zookeeper.client.acl: open
# 设置savepoints 的默认目标目录(可选)
# state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints
# 用于启用/禁用增量 checkpoints 的标志
# state.backend.incremental: false
(5)配置master
[root@node1 conf]# vim masters
node1:8081
node2:8081
(6)分发masters,flink-conf.yaml
scp -r /home/user/apps/flink/conf/masters node2:/home/user/apps/flink/conf/
scp -r /home/user/apps/flink/conf/masters node3:/home/user/apps/flink/conf/
scp -r /home/user/apps/flink/conf/flink-conf.yaml node2:/home/user/apps/flink/conf/
scp -r /home/user/apps/flink/conf/flink-conf.yaml node3:/home/user/apps/flink/conf/
(7)在node2节点上,修改flink-conf.yaml
jobmanager.rpc.address: node2
(8)启动HA集群
#1.启动hadoop
/usr/apps/hadoop/sbin/start-dfs.sh
#2.启动Zookeeper
/usr/apps/zookeeper/bin/zkServer.sh start
#查看zookeeper是否启动:/usr/apps/zookeeper/bin/zkServer.sh status
#3.启动Flink
bin/start-cluster.sh
#查看flink是否启动 jps
Flink前端:http://192.168.43.129:8081
三个Flink节点
(9)测试
为了实现windows能够访问linux的名称节点,比如node1等,我们需要配置#1.在windows系统中打开 C:\Windows\System32\drivers\etc\hosts
# 文件并添加主机配置。我添加的是自己的
虚拟主机ip跟主机名。
192.168.43.129 node1
192.168.43.130 node2
192.168.43.131 node3
(9)杀死active(node1)的jobmanager,然后看standby(node2)是否会切换为active状态。
关闭node1d1的jobmanager[root@node1 flink]# jps
86913 QuorumPeerMain
91139 Jps
87177 NameNode
88442 StandaloneSessionClusterEntrypoint
87326 DataNode
88958 TaskManagerRunner
[root@node1 flink]# kill -9 88442
node1不能访问了node2正常访问
五、Yarn搭建Flink集群(企业生产环境使用)
独立(Standalone)模式由 Flink 自身提供资源,无需其他框架,这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但我们知道,Flink 是大数据计算框架,不是资源调度框架,这并不是它的强项;所以还是应该让专业的框架做专业的事,和其他资源调度框架集成更靠谱。而在目前大数据生态中,国内应用最为广泛的资源管理平台就是 YARN 了。在强大的 YARN 平台上 Flink 是如何集成部署的。整体来说,YARN 上部署的过程是:客户端把 Flink 应用提交给 Yarn 的 ResourceManager,Yarn 的 ResourceManager 会向 Yarn 的 NodeManager 申请容器。在这些容器上,Flink 会部署JobManager 和 TaskManager 的实例,从而启动集群。Flink 会根据运行在 JobManger 上的作业所需要的 Slot 数量动态分配 TaskManager 资源。
1、yarn简介
yarn(yet another resource negotiator)是一个通用分布式资源管理系统和调度平台,为上层应用提供统一的资源管理和调度。在集群利用率、资源统一管理和数据共享等方面带来巨大好处。
资源管理系统:集群的硬件资源,如内存、CPU等。调度平台:多个程序同时申请计算资源如何分配,调度的规则(算法)。通用:不仅仅支持mapreduce程序,理论上支持各种计算程序。yarn不关心你干什么,只关心你要资源,在有的情况下给你,用完之后还我。flink on yarn: 把资源管理交给yarn实现,计算机资源统一由Haoop YARN管理,生产环境测试。2、Yarn搭建Flink集群准备工作
flink on yarn 企业生产环境运行flink任务大多数的选择好处:集群资源由yarn集群统一调度和管理,提高利用率,flink中jobmanager的高可用操作就由yarn集群来管理实现。(1)在yarn-site.xml中配置关闭内存校验
yarn-site.xml是hadoop中/etc/hadoop下的配置文件,否则flink任务可能会因为内存超标而被yarn集群主动杀死(hadoop集群部署:http://t.csdn.cn/ZLLD9)
<!– 设置不检查
虚拟内存的值,不然内存不够会报错 –>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
(2)Yarn搭建Flink集群方式分类
在yarn上启动一个Flink主要有两种方式:
启动一个Yarn session(在yarn集群内部初始化一个Flink集群常驻,一直运行)直接在yarn上提交运行Flink作业(每次提交一个job到yarn集群,yarn集群开辟资源初始化一个Flink集合)3、Yarn搭建Flink集群之回话模式
启动一个Yarn session(在yarn集群内部初始化一个Flink集群常驻,一直运行)
(1)启动hadoop集群(HDFS,YARN)
#1.启动hadoop
/usr/apps/hadoop/sbin/start-all.sh
#2.启动Zookeeper(因为flink里面有zookeeper的配置,不打卡会报错:Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster)
/usr/apps/zookeeper/bin/zkServer.sh start
启动成功页面
(2)执行脚本命令向 YARN 集群申请资源,开启一个 YARN 会话,启动 Flink 集群。
使用yarn-session.sh命令申请资源初始化一个flink集群(yarn-session.sh命令在flink的bin下)bin/yarn-session.sh -n 2 -tm 800 -s 1 -d
命令参数解释# -n 表示申请2个容器,这里指的就是多少个taskmanager(虽然写的是2但是真实申请的是3个)
# -s 表示每个TaskManager的slots数量
# -tm 表示每个TaskManager的内存大小
# -d 表示以
后台程序方式运行,分离模式,如果你不想让 Flink YARN 客户端一直前台运行,可以使用这个参数,
# 即使关掉当前对话窗口,YARN session 也可以后台运行。
#-qu(–queue):指定 YARN 队列名。
从图中可以看到我们创建的 Yarn-Session 实际上是一个 Yarn 的Application,并且有唯一的 Application ID。
也可以通过 Flink 的 Web UI 页面查看提交任务的运行情况
(3)使用bin/yarn-session.sh –help 查看可用参数:
Usage:
Required
-n,–container <arg> Number of YARN container to allocate (=Number of Task Managers)
Optional
-D <property=value> use value for given property
-d,–detached If present, runs the job in detached mode
-h,–help Help for the Yarn session CLI.
-id,–applicationId <arg> Attach to running YARN session
-j,–jar <arg> Path to Flink jar file
-jm,–jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB)
-m,–jobmanager <arg> Address of the JobManager (master) to which to connect. Use this flag to connect to a different JobManager than the one specified in the configuration.
-n,–container <arg> Number of YARN container to allocate (=Number of Task Managers)
-nl,–nodeLabel <arg> Specify YARN node label for the YARN application
-nm,–name <arg> Set a custom name for the application on YARN
-q,–query Display available YARN resources (memory, cores)
-qu,–queue <arg> Specify YARN queue.
-s,–slots <arg> Number of slots per TaskManager
-sae,–shutdownOnAttachedExit If the job is submitted in attached mode, perform a best-effort cluster shutdown when the CLI is terminated abruptly, e.g., in response to a user interrupt, such
as typing Ctrl + C.
-st,–streaming Start Flink in streaming mode
-t,–ship <arg> Ship files in the specified directory (t for transfer)
-tm,–taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)
-yd,–yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead)
-z,–zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for high availability mode

(4)使用命令行提交任务
yarn集群中运行的任务:flink run在 YARN 环境中,由于有了外部平台做资源调度,所以我们也可以直接向 YARN 提交一个单独的作业,从而启动一个 Flink 集群。
/home/user/apps/flink/bin/flink run /home/user/apps/flink/examples/batch/WordCount.jar
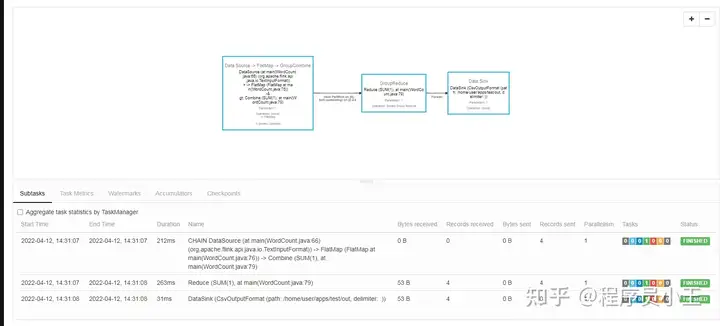
在 YARN 的 ResourceManager 界面查看执行情况点击可以打开 Flink Web UI 页面进行监控也可以直接在命令行查看结果哟!
(5)关闭yarn会话模式的集群
停止 flink on yarn 会话模式中的flink集群yarn application -kill appid
appid指hadoop前端页面中的id也是项目启动的那个前端页面被杀死
(6)会话模式这种方式的优缺点:
缺点:1 会一直有一个程序运行在yarn集群中,不管有没有任务提交执行,浪费资源,优点:flink 集群环境是提前准备好的不需要为每个作业单独创建flink环境适用场景:大量的小作业的时候可以考虑使用这种方式4、job分离模式
job分离模式一般用于长时间工作的任务,实际生产环境中job分离的方式使用较多!
(1)flink run -m yarn-cluster –help;可用参数:
Options for yarn-cluster mode:
-d,–detached If present, runs the job in detached
mode
-m,–jobmanager <arg> Address of the JobManager (master) to
which to connect. Use this flag to
connect to a different JobManager than
the one specified in the
configuration.
-sae,–shutdownOnAttachedExit If the job is submitted in attached
mode, perform a best-effort cluster
shutdown when the CLI is terminated
abruptly, e.g., in response to a user
interrupt, such as typing Ctrl + C.
-yD <property=value> use value for given property
-yd,–yarndetached If present, runs the job in detached
mode (deprecated; use non-YARN
specific option instead)
-yh,–yarnhelp Help for the Yarn session CLI.
-yid,–yarnapplicationId <arg> Attach to running YARN session
-yj,–yarnjar <arg> Path to Flink jar file
-yjm,–yarnjobManagerMemory <arg> Memory for JobManager Container with
optional unit (default: MB)
-yn,–yarncontainer <arg> Number of YARN container to allocate
(=Number of Task Managers)
-ynl,–yarnnodeLabel <arg> Specify YARN node label for the YARN
application
-ynm,–yarnname <arg> Set a custom name for the application
on YARN
-yq,–yarnquery Display available YARN resources
(memory, cores)
-yqu,–yarnqueue <arg> Specify YARN queue.
-ys,–yarnslots <arg> Number of slots per TaskManager
-yst,–yarnstreaming Start Flink in streaming mode
-yt,–yarnship <arg> Ship files in the specified directory
(t for transfer)
-ytm,–yarntaskManagerMemory <arg> Memory per TaskManager Container with
optional unit (default: MB)
-yz,–yarnzookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
-z,–zookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
(2)直接提交任务到yarn即可:
bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 /home/user/apps/flink/examples/batch/WordCount.jar
命令参数解释:# -m yarn-cluster 表示使用Job分离模式
# -yjm 指定jobmanager内存
# -ytm 指定taskmanager内存
# -yn 指定taskmanager数量
# -ys 指定每个taskmanager的slot数量
提交任务之后会在yarn集群按照我们的配置初始化一个flink集群,运行我们提交的作业,作业执行完成之后就释放资源关闭掉flink集群,把资源还给yarn集群。
如果运行时报错:Could not allocate enough slots within timeout of 300000 ms to run the job. Please make sure that the cluster has enough resources.就在flink里面flink-conf.yaml里面的新增参数增加可支持的slot数量taskmanager.network.memory.fraction: 0.1
taskmanager.network.memory.min: 268435456
taskmanager.network.memory.max: 4294967296
注意:一般自己的项目比较小,linux资源比较少的不要设置,268435456 >= 209715200(3)job分离模式的优缺点
优点:随到随用,只有任务需要运行时才会开启flink集群;运行完就关闭释放资源,资源利用更合理;缺点:对于小作业不太友好,用场景:适合大作业,长时间运行的大作业。六、K8S 模式搭建Flink集群
容器化部署是如今业界流行的一项技术,基于 Docker 镜像运行能够让用户更加方便地对
应用进行管理和运维。容器管理工具中最为流行的就是 Kubernetes(k8s),而 Flink 也在最近
的版本中支持了 k8s 部署模式。基本原理与 YARN 是类似的,具体配置可以参见官网说明















































































暂无评论内容