
一、Flink核心概念
1、Flink核心概念
(1)Flink是什么 ?
Apache Flink是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。 可部署在各种集群环境,对各种大小的数据规模进行快速计算。
官网:
https://flink.apache.orghttps://data-artisans.com(2)有限数据流和无限数据流?
有限数据流:有限不会改变的数据集合–批处理、离线运算(直梯)
误区:很多现实中认为是有界或者批量的数据集实际上无限数据流,hdfs目录、kafka
无限数据流:数据流源源不断的–流式计算、流计算(滚梯)举例:
(a) 点击流(终端手机用户或者web应用的点击流)
(b) 物理传感器采集的测量数据
(c) 金融市场产生的数据(股市、数字货币交易市场)
(d) 服务器上的日志数据(3)Flink为何受青睐—特性 ?
支持批处理和数据流程序处理 优雅流畅的支持java和scala api 同时支持高吞吐量和低延迟 支持事件处理和无序处理通过SataStream API,基于DataFlow数据流模型 在不同的时间语义(事件时间,摄取时间、处理时间)下支持灵活的窗口(时间,滑动、 翻滚,会话,自定义触发器) 仅处理一次的容错担保 自动反压机制 图处理(批) 机器学习(批) 复杂事件处理(流) 在dataSet(批处理)API中内置支持迭代程序(BSP) 高效的自定义内存管理,和健壮的切换能力在in-memory和out-of-core中 兼容hadoop的mapreduce和storm 集成YARN,HDFS,Hbase 和其它hadoop生态系统的组件(3)Flink生态之核心组件栈
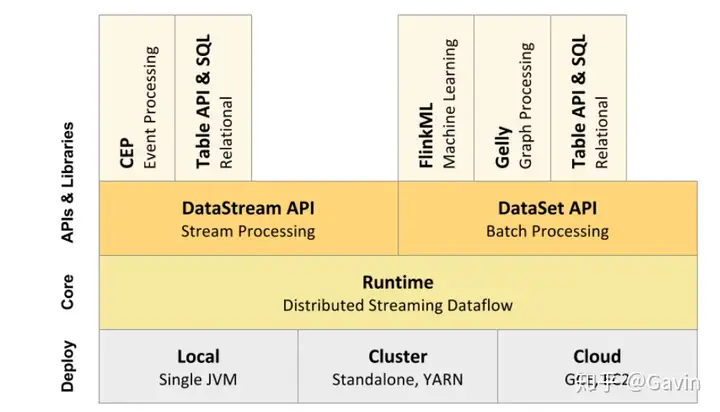
(4)Flink未来
批计算的突破、流处理和批处理无缝切换、界限越来越模糊、甚至混合 多语言支持 完善Machine Learning 算法库,同时 Flink 也会向更成熟的机器学习、深度学习去集成(比如Tensorflow On Flink)(5)Flink应用场景
主要应用场景有三类:
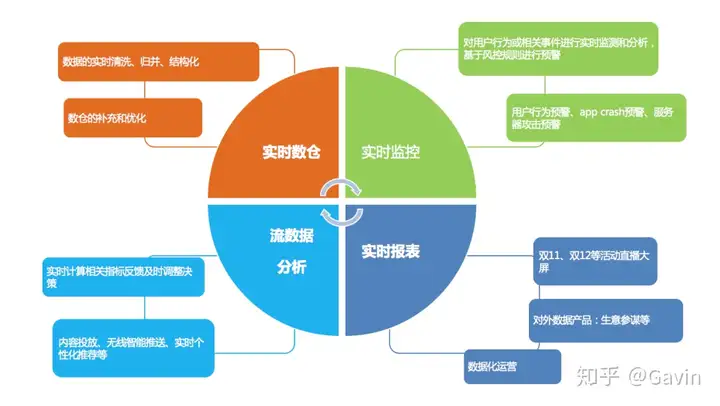
Event-driven Applications【事件驱动】 Data Analytics Applications【分析】 Data Pipeline Applications【管道式ETL】
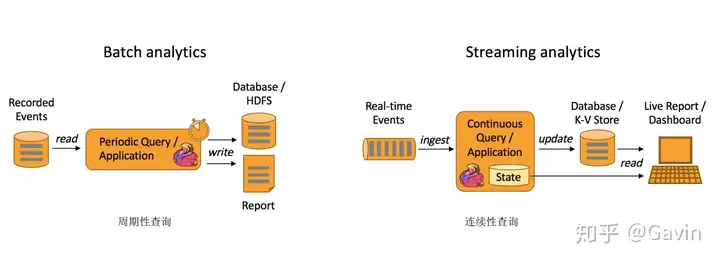
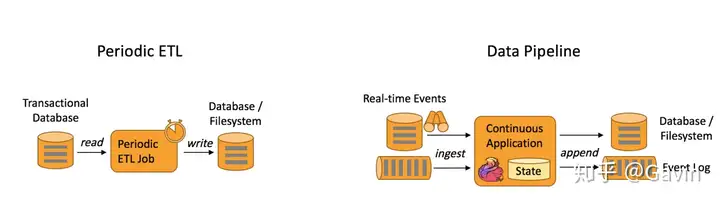


(5)Flink VS Spark 之 社区
Spark 社区在规模和活跃程度上都是领先的,毕竟多了几年发展时间,同时背后的商业公司Databricks 由于本土优势使得Spark在美国的影响力明显优于Flink
而且作为一个德国公司,Data Artisans 想在美国扩大影响力要更难一些。不过 Flink 社区也有一批 稳定的支持者,达到了可持续发展的规模。
在中国情况可能会不一样一些。比起美国公司,中国公司做事情速度更快,更愿意尝试新技术。中国的 一些创新场景也对实时性有更高的需求。这些都对 Flink 更友好一些。
近期 Flink 的中国社区有一系列动作,是了解 Flink 的好机会。
Flink 的中文社区在 http://flink-china.org/另外,2018 年 12 月 20 日 -21 日在国家会议中心举办的首届 Flink Forward China 峰会(千人规模), 参与者将有机会了解阿里巴巴、腾讯、华为、滴滴、美团、字节跳动等公司为何将 Flink 作为首选的流 处理引擎。(6) 我的观点
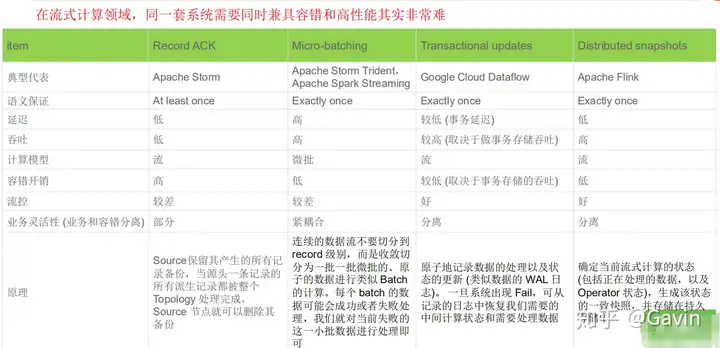
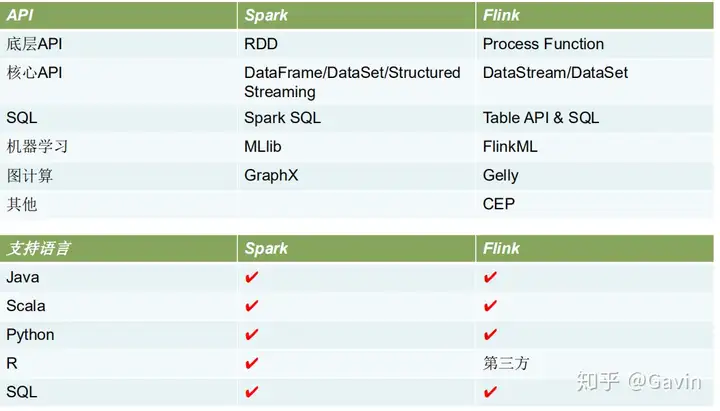
Spark 和 Flink 都是通用的开源大规模处理引擎,目标是在一个系统中支持所有的数据处理以 带来效能的提升。两者都有相对比较成熟的生态系统。是下一代大数据引擎最有力的竞争者。
Spark 的生态总体更完善一些,在机器学习的集成和易用性上暂时领先。
Flink 在流计算上有明显优势,核心架构和模型也更透彻和灵活一些。
在易用性方面两者也都还有一些地方有较大的改进空间。接下来谁能尽快补上短板发挥强项就 有更多的机会。二、DataSream API 概述
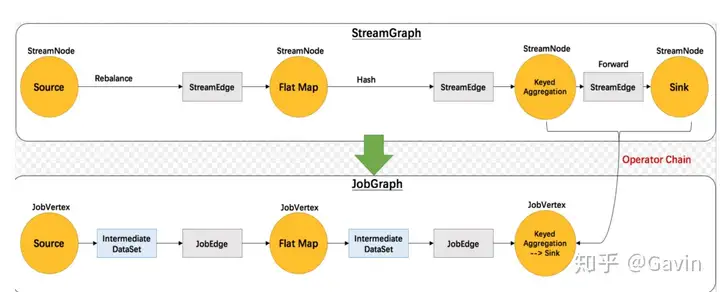
(1)Flink的四层执行计划

StreamGraph
根据用户代码生成最初的图 表示程序的拓扑结构 在client端生成JobGraph
优化streamgraph 将多个符合条件的Node chain在一起 在client端生成ExecutionGraph
JobManger根据JobGraph生成,并行化物理执行图
实际执行图,不可见

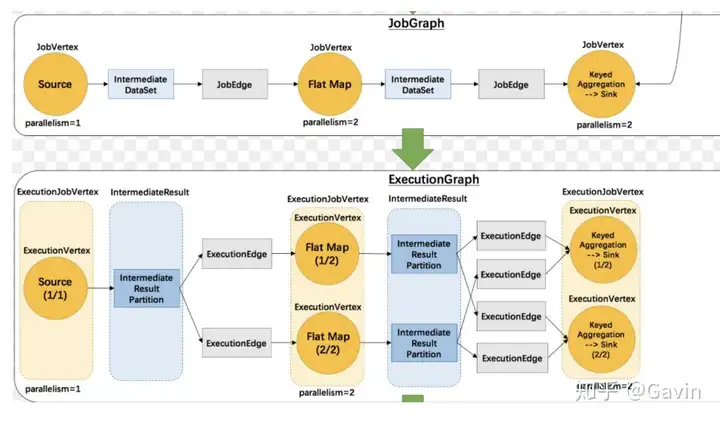
ExecutionGraph
ExecutionJobVertex <- JobVertex ExecutionVertex并发任务 ExecutionEdge <- JobEdge JobGraph 2维结构 根据2维结构分发对应Vertex到指定slotDataStreamContext
getExecutionEnvironment Jar
cmd• createLocalEnvironment
内置数据源
基于文件 基于Socket 基于Collection自定义数据源
实现SourceFunction(非并行的) 实现ParallelSourceFunction 继承RichParallelSourceFunction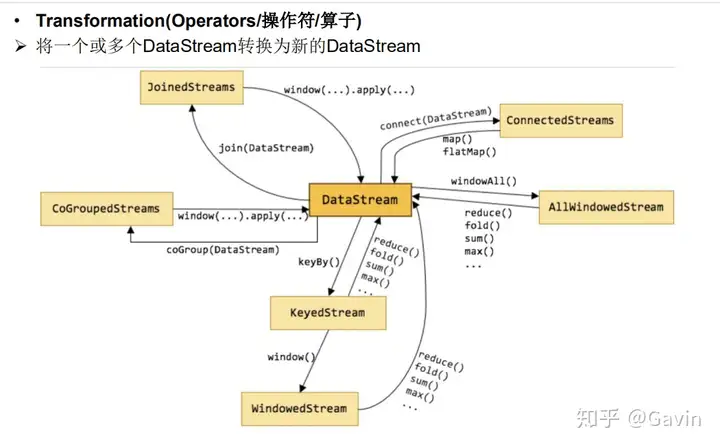
DataSink (自定义Sink)
实现SinkFunction 接口
继承RichSinkFunction(2)流式迭代运算
没有最大迭代次数• 需要通过split/filter转换操作指定流的哪些部分数据反馈给迭代算子,哪些部分数据被转发到 下游DataStream
• 基本套路
基于输入流构建IterativeStream(迭代头)
定义迭代逻辑(map fun等)
定义反馈流逻辑(从迭代过的流中过滤出符合条件的元素组成的部分流反馈给迭代头进行重
复计算的逻辑)
调用IterativeStream的closeWith方法可以关闭一个迭代(也可表述为定义了迭代尾)
定义“终止迭代”的逻辑(符合条件的元素将被分发给下游而不用于进行下一次迭代)问题域 输入一组数据,我们对他们分别进行减1运算,直到等于0为止看代码(3)Controlling Latency(控制延迟)
默认情况下,流中的元素并不会一个一个的在网络中传输(这会导致不必要的网络流量消耗)
,而是缓存起来,缓存的大小可以在Flink的配置文件、 ExecutionEnvironment、设置某
个算子上进行配置(默认100ms) 好处:提高吞吐 坏处:增加了延迟如何把握平衡?
为了最大吞吐量,可以设置setBufferTimeout(-1),这会移除timeout机制,缓存中的数据一 满就会被发送 为了最小的延迟,可以将超时设置为接近0的数(例如5或者10ms) 缓存的超时不要设置为0,因为设置为0会带来一些性能的损耗( 4 ) Flink提供的调试手段
1、Streaming程序发布之前最好先进行调试,看看是不是能按预期执行
2、为了降低分布式流处理程序调试的难度,Flink提供了一些列方法: 本地执行环境 Collection Data Sources Iterator Data Sink二、Flink核心概念与编程模型
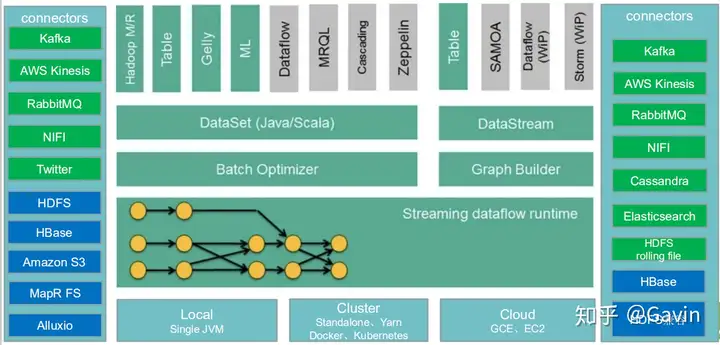
1、Flink生态之核心组件栈

2、Flink分层架构

3、Stateful Stream Processing
位于最底层, 是core API 的底层实现 processFunction 利用低阶,构建一些新的组件或者算子 灵活性高,但开发比较复杂4、Core API
DataSet – 批处理 API DataStream –流处理 API5、Table API & SQL
SQL 构建在Table 之上,都需要构建Table 环境 不同的类型的Table 构建不同的Table 环境 Table 可以与DataStream或者DataSet进行相互转换 Streaming SQL不同于存储的SQL,最终会转化为流式执行计划6、Flink DataFlow基本套路







三、Flink Runtime
1、Flink运行时架构

2、TaskManger Slot

3、OperatorChain && Task
为了更高效地分布式执行,Flink会尽可能地将operator的subtask链接(chain)在一起形成task。 以wordcount为例进行分析
上图中将KeyAggregation和Sink两个operator进行了合并,因为这两个合并后并不会改变整体的拓扑结构
4、OperatorChain的优点和组成条件

5、编程改变OperatorChain行为

6、Slot分配与共享


7、SlotSharingGroup(soft)

8、CoLocationGroup(强制)
保证所有的并行度相同的sub-tasks运行在同一个slot 主要用于迭代流(训练机器学习模型)9、Slots && parallelism

10、如何计算一个应用需要多少slot

11、运行时概念总结
Jobmanger• TaskManger
• TaskManager Slots
• Job
• Task&subtask(线程)
• Operator
• Parallelism
• Chain
• SlotSharingGroup
• CoLocationGroup
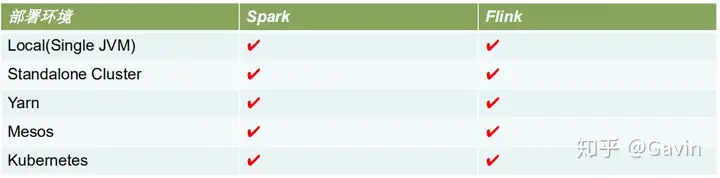
12、Flink部署方式
Local• Standalone Cluster
• YARN
• Mesos
• Docker
• Kubernetes
• AWS
• Google Compute Engine
Single JVM• 用于测试调试代码
13、Flink On YARN简述
ResourceManager• NodeManager
• AppMaster( jobmanger 运行在其上)
• Container(taskamanager 运行在其上)
• YarnSession
• 选择on-Yarn 的理由
提高机器的利用率
Hadoop 开源活跃,且成熟

四、Flink API 通用基本概念
1、DataSet and DataStream
表示Flink app中的分布式数据集• 包含重复的、不可变数据集
• DataSet有界、DataStream可以是无界
• 可以从数据源、也可以通过各种转换操作创建
2、共通的编程套路
获取执行环境(execution environment)• 加载/创建初始数据集
• 对数据集进行各种转换操作(生成新的数据集)
• 指定将计算的结果放到何处去
• 触发APP执行
3、惰性计算
Flink APP都是延迟执行的• 只有当execute()被显示调用时才会真正执行
• 本地执行还是在集群上执行取决于执行环境的类型
• 好处:用户可以根据业务构建复杂的应用,Flink可以整体进优化并生成执行计划
4、指定键(Specifying Keys)
(1)谁需要指定键
哪些操作需要指定key(join, coGroup, keyBy, groupBy,Reduce, GroupReduce,Aggregate, Windows)
Flink编程模型的key是虚拟的,不需要你创建键值对(2)为Tuple定义键
按照指定属性分组注意:这里使用KeyBy(0)指定键,系统将会使用整个Tuple2作为键(整型和浮点型的)。
如果想使用Tuple2内部字段作为键,你可以使用字段来表示键(3)使用字段表达式定义键
基于字符串的字段表达式可以用来引用嵌套字段(例如Tuple,POJO)语法

(4)字段表达式实例-Java

(5)字段表达式实例-Scala

(5)使用键选择器函数定义键(Key Selector Functions)
还有一种定义键的方式叫做“键选择器”函数。键选择器函数需要一个元素作为入参,返
回这个元素的键。这个键可以是任何类型的,也可从指定计算中生成。5、自定义转换函数
(1)方式1:实现接口
大多数的转换操作需要用户自己定义函数。

(2)方式2:匿名类

(3)方式3:Lambda表达式

(4)方式4:Rich Functions

6、Rich Function丰富的功能
非常有用的四个方法:open,close,getRuntimeContext和setRuntimecontext
这些功能在参数化函数、创建和确定本地状态、获取广播变量、获取运行时信息(例如
累加器和计数器)和迭代信息时非常有帮助。
7、支持的数据类型

8、Java Tuple

9、Scala Case类
Scala的Case类(以及Scala的Tuple,实际是Case class的特殊类型)是包含了一定数量多种类型字段 的组合类型。Tuple字段通过他们的1-offset名称定位,例如 _1代表第一个字段。Case class 通过字 段名称获得:10、POJOs

11、基本类型
Flink支持Java和Scala所有的基本数据类型,比如 Integer,String,和Double
12、一般通用类
Flink支持大多数的Java,Scala类(API和自定义)。包含不能序列化字段的类在增加一些限制后也可 支持。遵循Java Bean规范的类一般都可以使用。所有不能视为POJO的类Flink都会当做一般类处理。这些数据类型被视作黑箱,其内容是不可见的。 通用类使用Kryo进行序列/反序列化。13、值类型Values
通过实现org.apache.flinktypes.Value接口的read和write方法提供自定义代码来进行序列化/反序列化 ,而不是使用通用的序列化框架Flink预定义的值类型与原生数据类型是一一对应的(例如:ByteValue, ShortValue, IntValue, LongValue, FloatValue, DoubleValue, StringValue, CharValue, BooleanValue)。这些值类型作为原生 数据类型的可变变体,他们的值是可以改变的,允许程序重用对象从而缓解GC的压力。14、Hadoop的Writable类
实现org.apache.hadoop.Writable接口的类型,该类型的序列化逻辑在write()和readFields()方法中实现15、特殊类型
• Scala的 Either、Option和Try
Java ApI有自己的Either实现16、类型擦除和类型推理

Flink 的Java API会试图去重建这些被丢弃的类型信息,并将它们明确地存储在数据集以及操作中。
你可以通过DataStream.getType()方法来获取类型,这个方法将返回一个TypeInformation的实例,这 个实例是Flink内部表示类型的方式。17、累加器和计数器(Accumulators & Counters)

如何使用累加器 ?

自定义累加器
实现Accumulator或者SimpleAccumulator
五、DataStream编程基本套路
1、运行模型


2、执行计划Graph

3、Graph

4、StreamGraph

5、StreamGraph转JobGraph

6、JobGraph

7、JobGraph -> ExecutionGraph

8、ExecutionGraph

9、DataStreamContext

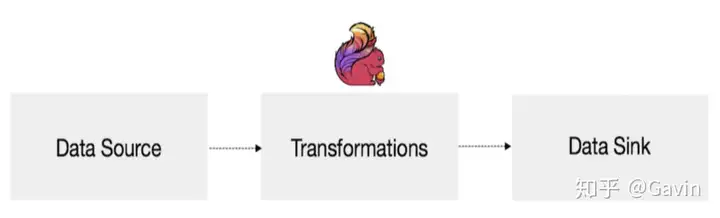
10、数据源(DataSource)

自定义DataSource
转换(Transformations)

DataSink

11、流式迭代运算(Iterations)
简单理解迭代运算
当前一次运算的输出作为下一次运算的输入(当前运算叫做迭代运算)• 不断反复进行某种运算,直到达到某个条件才跳出迭代(是不是想起了递归)
流式迭代运算

流式迭代运算实例

12、Execution参数
Controlling Latency(控制延迟)

13、调试
Flink提供的调试手段

本地执行环境-基于线程模拟执行环境

集合数据源(Collection Data Sources)-模拟数据输入

Iterator Data Sink-模拟数据输出


















暂无评论内容