
如何学习Flink?
前言
Flink可谓是当红炸子鸡,一线大厂都在尝试使用Flink,不少小伙伴跃跃欲试,也想学习Flink,但是却不知道该怎么学,故为大家浅薄的谈一下Flink学习之路,不当之处欢迎拍砖
疑问
首先列出最高频的几个问题
看书还是看视频?我没有大数据基础可以直接学习Flink吗?Flink项目哪里找?
先回答第一个问题,针对看书还是看视频,完全取决于自身的大数据基础,如果有大数据基础的,建议直接看书快一点,而且和看视频相比,看书的思维是随着个人走的,有更深的理解能力,而对于没有大数据基础的强烈建议看视频,觉得看视频慢的话可以先看技术相关文档(文末会提供),了解概念和大概使用之后,记下自己的疑问,然后带着疑问倍速看视频,这样也是一个很好的办法没有大数据基础可以直接学习吗?
当然可以,但是!!请注意大概的入门知识还是要有的,大数据是整个链路的过程,单独学Flink是没有用的,自然从Hadoop Zookeeper Hive Flume HBase 一路慢慢学太慢了,可以快速入门以下,同样文末提供了一套快速入门视频,作为学习Flink的基础学习Flink项目哪里找?
文末获取!!首先是方法论,此条通用语所有技术
如何学习一门新技术?
首先是了解技术的应用场景,听起来似乎是很滑稽的一个事情,但往往能折射出你对一门技术的理解,对于相当一部分同学来说,当面试官问道为什么用这个技术,往往一时语塞,心里想的是我看大家都是这样用,为了用而用,网上视频告诉我这个技术高大上等,这都是错误的,对于初学者一定要了解以下技术的应用场景,而对于有大数据基础的人,则要更思考横向对比,和同类型其他技术的区别是什么?技术的基本概念,如何使用,比如说一门语言开始,我们通常都以一个hello world开始,对于Flink等大数据处理框架则通常都是从第一个wordcount开始,刚开始了解概念就可以快速搞一个Demo,一方面是对于初学者长时间的研究概念,往往会打击其积极性,有一种我学了好久却不知道到底能干啥,记住最终是要落地在代码上的技术的功能特点
这项技术内部是由哪几部分组成的呢?每部分都是干嘛的?如果是分布式的话,就要考虑如何通信了,是对等架构还是主从架构?技术源码
先说源码,以Flink而言,为什么要学习源码?就是为了面试吹水吗?诚然这是现在的一个风气,坊间谓之“面试造火箭,入职拧螺丝”,不可否认的确有一部分因素,但却不是主要的因素,最主要的因素是很多时候这项技术的某一部分并不适合你所在的业务,就需要对其进行改造,只有了解了源码,才能重写源码改造为适合自己的业务,最后,还有一点原因,优秀的源码重要的是思想,你会惊奇的发现很多技术所用思想是类似的,技术是学不完的,思想却是永恒的概念篇
这往往是很多人最头疼的地方,一开始抱着书啃立马被一大堆晦涩的概念所弄晕,一方面是由于某些书籍博客的误导作用,往往把概念说的很复杂,而且对于翻译过来的难以恭维,往往和原作者表达意思不一致,但概念是不可以跳过的,初学者需要了解个大概,这个名词是说什么的?在代码中如何应用?一定要与代码相联系,对于Flink要理解的几个概念很重要
流数据
什么是流数据?流数据的特性,这是相当重要的,只有理解了流数据,学习过Spark的同学才能知道Flink为什么有watermark state这类东西watermark
我本人学习这个的时候也是很懵逼的,完全不懂,实际上中文翻译过来应该为水位线,本质是时间戳,和event Time联合起来处于乱序数据,这就是对这个功能的大概描述,一目了然State
状态?官网的解释有些玄学听起来,首先要知道状态是流式数据的一个概念,打个不恰当的比方,状态指的是operator中间计算的结果大概了解了这几个概念之后,就可以开始代码实践了,在这里并没有说很深入的了解这些概念,为什么?对初学者来说只有结合实践回头再理解概念,才能更输入的了解概念所代表的深意,以及思考为什么要有这几个概念和机制
代码实践
也叫调API小能手,一句话来说,Flink API的操作就是三大部分,对于Spark同样适用,数据源获取,数据处理,以及处理数据完存在哪里,也就是
sourcetransformsink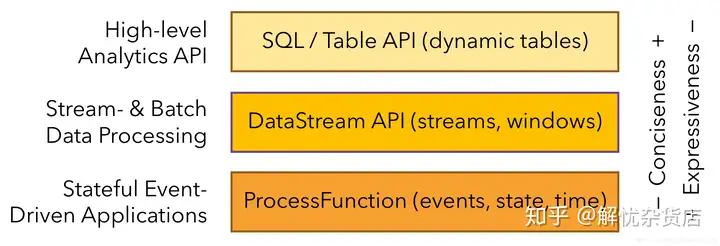
Source
你看了官网,练习了几个基本Demo,知道source可以从集合,文本,socket等中产生,这是简单的Demo,试想以下真正生产中对接的数据源基本不是这些,比如说MySQL Kafka Es等,这才是实践的重点,一部分source官网中给的有示例,但也有一部分需要你自定义实现了
Transform
Flink处理数据的过程,按着Demo发现似乎实现起来很简单,只要调API就好了呀,实际上是这样的吗?并不是,简单的原因无非是Data Stream API的封装,你在做黑盒操作罢了,对底层并不了解,所以一旦出现问题也很难定位,对于不能满足自身业务的也一筹莫展,要下沉到ProcessFunction,根据业务自定义的实现相关函数,这才是要真正学习的,当然了这其中有几个很重要的,我举一下例子
window划分
watermark生成
State的使用和种类以及存储
Sink
与Sink同理,也需要关注自定义的source,并不是所有现成的API能满足业务需求
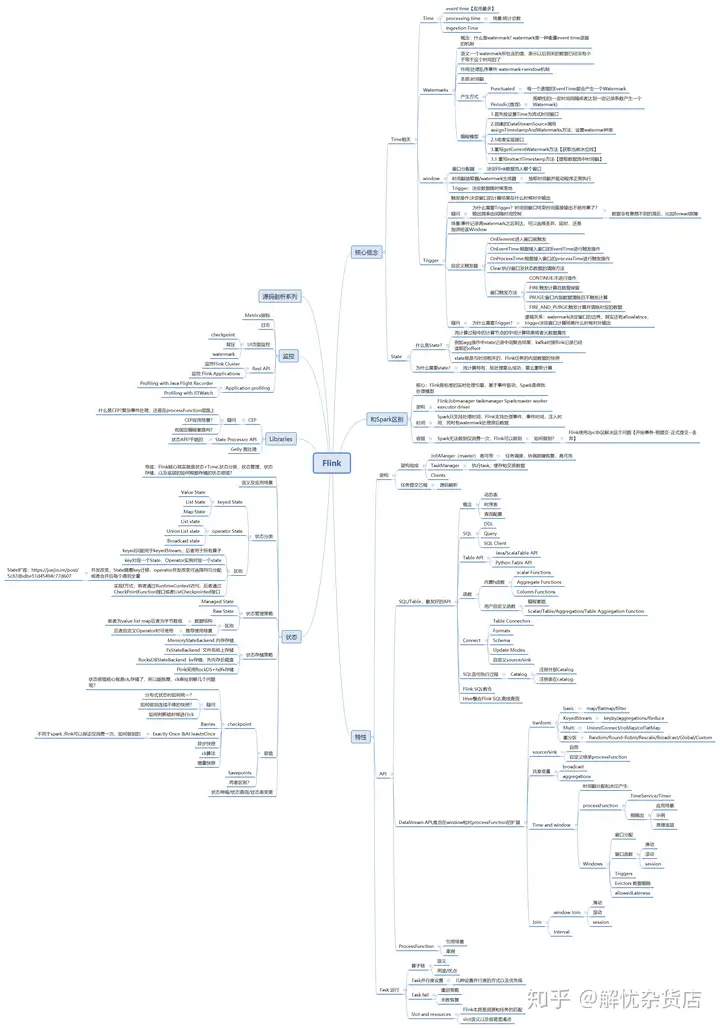
知识体系
学习一门知识一定要有宏观的概念,建议用知识图谱罗列出技术所在的知识点,这样好处有以下几点
方便自己学习知识,各个击破,不会昨天学今天就忘面试突击,笔者有一个很深的体会就是一旦面对面试看着几百页的面经想着后天的面试难免慌的一批,无从下手,知识图谱呢就可以帮助你面试有体系性,能够快速复习这里笔者整理了一份知识图谱,供读者参考(如果看不清楚的话,可以私我发高清图),同时我也对图谱中所设计的技术讲了一下大概,有兴趣的可以看一下我上一篇文章
实践项目
实践项目是非常重要的,毕竟学习的目的就是为了项目实践,对于转型大数据的同学还要在简历上写上项目,笔者提供了几个项目可以参考
如何获取?关注公众号发送Flink送您全套教程,包含入门 源码 项目实战一站式配齐
结语
重复,这是我能想出最合适的方法学习一门技术,对于一些概念,只有先了解再实践最后再深入回头看才能真正理解,不能深入了解的具体表现就是最怕面试官连环问,所以要多思考为什么?
多练 ,一定要自己敲代码,不要看一下示例就觉得自己会了,只有自己敲代码才是自己的真正输出,因为实际上可能并没有那么简单,一个很简单的问题就是包导错,使用Java倒成了Scala了,使用scaka莫宁奇妙报错最后才发现自己没有导入隐式转换


















暂无评论内容