
继续坚持!!!
Flink安装部署
前言一、运行架构二、本地模式三、Local Cluster 本地集群1.原理2.操作3.测试四、Standalone 独立集群五、Standalone HA 高可用集群六、Flink On Yarn前言
Flink支持多种安装模式
– Local:本地单机模式,学习测试时使用
– Standalone:独立集群模式,Flink 自带集群,开发测试环境使用
– Standalone HA:独立集群高可用模式,Flink自带集群,开发测试及生产环境使用
– On Yarn:计算资源统一由Hadoop YARN管理,生产环境使用一、运行架构
Flink 应用程序运行时,应用提交、资源申请与任务分配、任务执行,由三部分组成:
FlinkClient: Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming的任务),也可以不结束并等待结果返回(MapReduce Client:yarn jar hadoop-mapreduce.jar WordCount input ouput)
JobManager:主要负责调度 Job 并协调 Task 做 checkpoint,从 Client 处接收到 Job 和JAR 包等资源后,会生成优化后的执行计划,并以 Task 为单元调度到各个 TaskManager 去执行。(ResourceManager和ApplicationMaster或JobTracker)
TaskManager:在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立连接,接收数据(NodeManager或TaskTracker)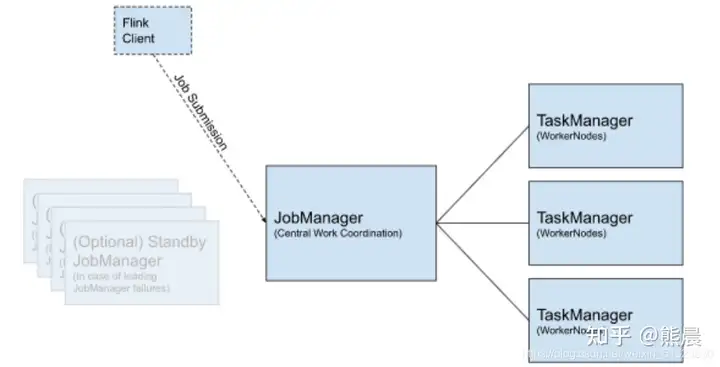
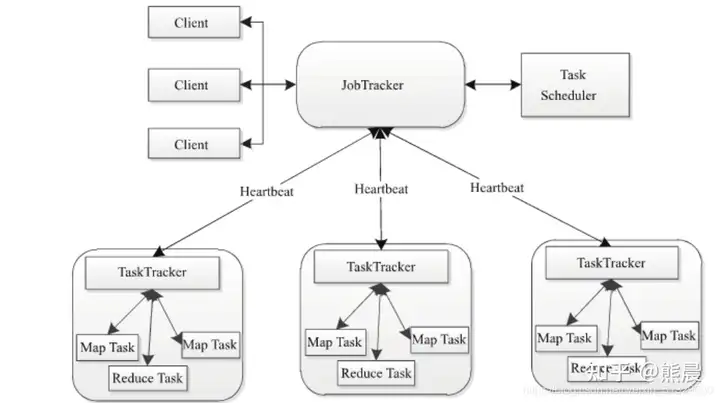
附录:MapReduce 1.0 架构组成
二、本地模式
本地模式LocalMode表示JobManager和TaskManager运行在一个JVM进程中。
1.启动shell交互式窗口
/export/server/flink/bin/start-scala-shell.sh local
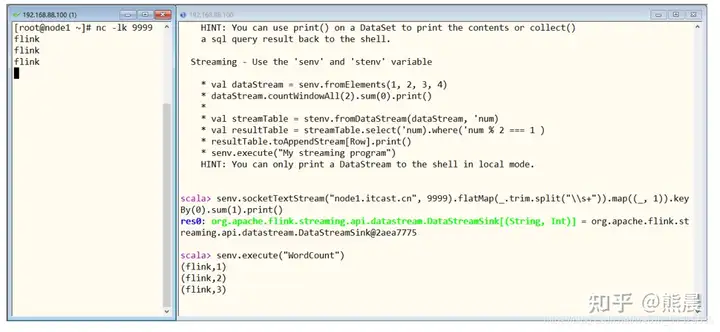
2流计算,执行如下命令
senv.socketTextStream(“http://node1.itcast.cn“, 9999).flatMap(_.split(“\\s+”)).map((_, 1)).keyBy(0).sum(1).print()
3.准备文件/root/words.txt
vim /root/words.txt //写入以下文本,注意空格符保持一致 flink flink spark spark flink hadoop flink spark spark flink hadoop flink flink spark flink
4.批处理,执行如下命令
benv.readTextFile(“/root/words.txt”).flatMap(_.split(“\\s+”)).map((_,1)).groupBy(0).sum(1).print()
5.退出shell
:quit
三、Local Cluster 本地集群
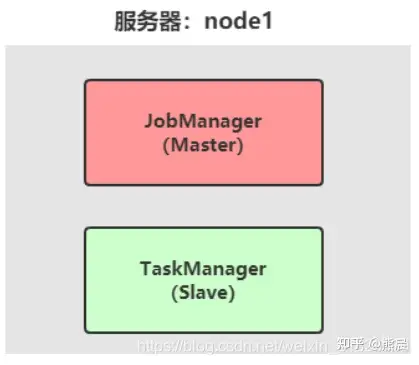
Flink 应用运行Local Cluster本地集群环境,与Hadoop 框架伪分布式环境类似,所有进程Process运行在一台机器上,针对Flink框架来说,进程分别为JobManager(主节点,管理者)和TaskManager(从节点,干活着)。
1.原理
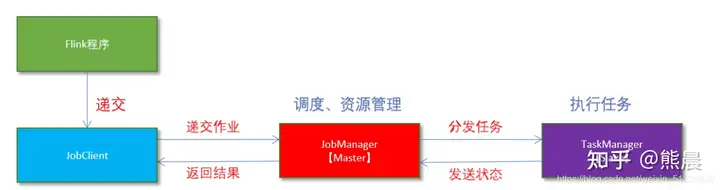
1. Flink程序由JobClient进行提交。
2. JobClient将作业提交给JobManager。
3. JobManager负责协调资源分配和作业执行。资源分配完成后,任务将提交给相应的TaskManager。
4. TaskManager启动一个线程以开始执行。TaskManager会向JobManager报告状态更改,如开始执行,正在进行或已完成
5. 作业执行完成后,结果将发送回客户端(JobClient)。
2.操作
1.下载安装包:https://archive.apache.org/dist/flink/flink-1.10.0/
2.上传flink-1.10.0-bin-scala_2.11.tgz到node1的指定目录
3.解压
tar -zxvf flink-1.10.0-bin-scala_2.11.tgz chown -R root:root /export/server/flink-1.10.0/
4.创建软连接
ln -s flink-1.10.0 flink
3.测试
1).本地集群启动与停止
1.启动Flink本地集
/export/server/flink/bin/start-cluster.sh
2.使用jps可以查看到下面两个进程
– TaskManagerRunner – StandaloneSessionClusterEntrypoint
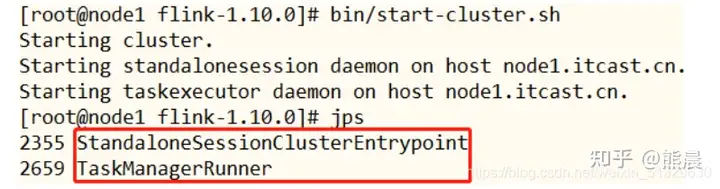
3.访问Flink的Web UI:http://node1.itcast.cn:8081/#/overview
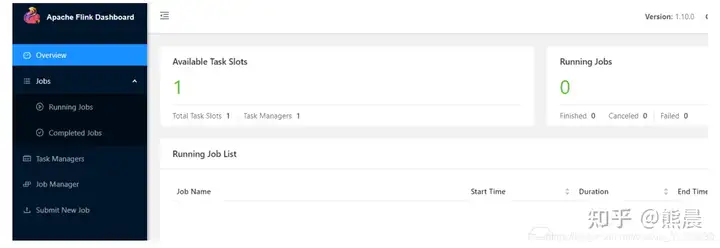
slot在Flink里面可以认为是资源组,Flink是通过将任务(Task)分成子任务(SubTask)并且将这些子任务分配到slot来并行执行程序。
4.停止Flink
/export/server/flink/bin/stop-cluster.sh
2)、流计算:WordCount
运行流式计算程序,从TCP Socket 读取数据,进行词频统计(类似StructuredStreaming)。
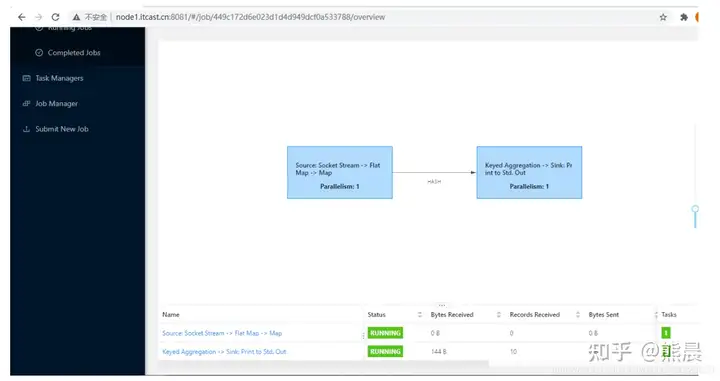
# 开启终端 nc -lk 9999 # 上传jar包至/export/server/flink目录 cd /export/server/flink rz # 开启终端,运行流式应用 bin/flink run –class cn.itcast.flink.StreamWordCount \ /export/server/flink/StreamWordCount.jar \ –host http://node1.itcast.cn –port 9999
监控页面查看日志信息数据
3)、批处理:WordCount
执行官方示例,读取文本文件数据,进行词频统计WordCount,将结果打印控制台或文件。
打印控制台:
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar –input /root/words.txt
输出文件:
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar –input /root/words.txt –output /root/out.txt
四、Standalone 独立集群
Standalone集群类似Hadoop YARN集群,管理集群资源和分配资源给Flink应用运行任务Task。
1原理
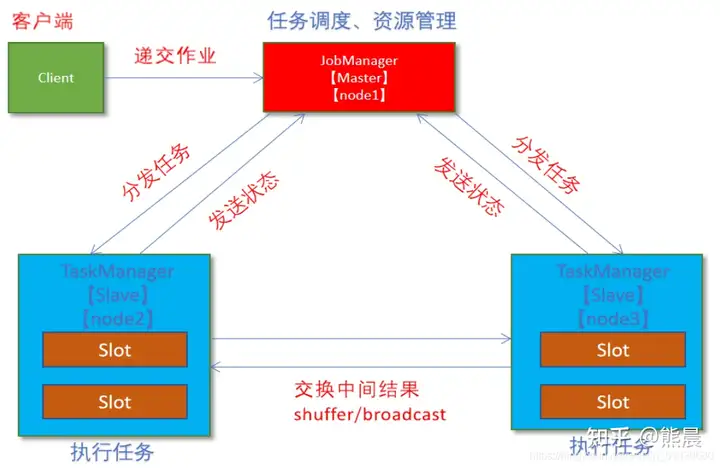
1. client客户端提交任务给JobManager;
2. JobManager负责申请任务运行所需要的资源并管理任务和资源;
3. JobManager分发任务给TaskManager执行;
4. TaskManager定期向JobManager汇报状态;2 操作
1.集群规划:
– 服务器: node1(Master + Slave): JobManager + TaskManager
– 服务器: node2(Slave): TaskManager
– 服务器: node3(Slave): TaskManager
2.修改flink-conf.yaml
vim /export/server/flink/conf/flink-conf.yaml
jobmanager.rpc.address: 虚拟机IP地址
3.修改masters
vim /export/server/flink/conf/masters
虚拟机IP地址:8081
4.修改slaves
vim /export/server/flink/conf/slaves
第一台虚拟机IP 第二台虚拟机IP 第三台虚拟机IP
5.添加HADOOP_CONF_DIR环境变量(集群所有机器)
vim /etc/profile
export HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
source /etc/profile
6.将Flink依赖Hadoop 框架JAR包上传至FLINK_HOME/lib目录
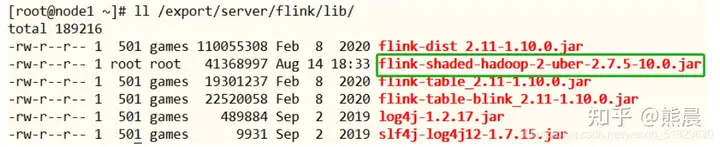
7.分发
scp -r /export/server/flink root@第二台虚拟机IP:/export/server scp -r /export/server/flink root@第三台虚拟机IP:/export/server
3 测试
1.启动HDFS集群,在第一台虚拟机上上执行如下命令
hadoop-daemon.sh start namenode hadoop-daemons.sh start datanode
2.启动集群,在第一台虚拟机上执行如下命令
/export/server/flink/bin/start-cluster.sh
或者单独启动
/export/server/flink/bin/jobmanager.sh ((start|start-foreground) cluster)|stop|stop-all /export/server/flink/bin/taskmanager.sh start|start-foreground|stop|stop-all
3.访问Flink UI界面或使用jps查看
http://第一台虚拟机IP:8081/#/overviewTaskManager界面:可以查看到当前Flink集群中有多少个TaskManager,每个TaskManager的slots、内存、CPU Core是多少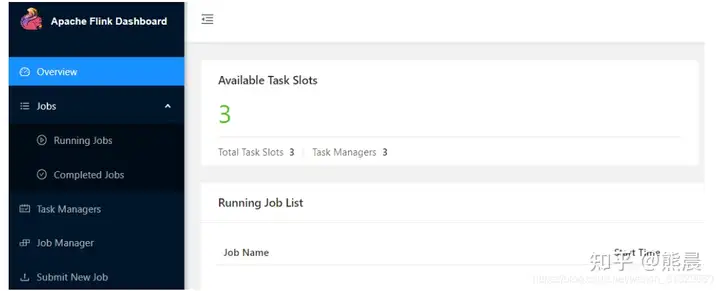
4.执行官方测试案例
hdfs dfs -mkdir -p /wordcount/input/ hdfs dfs -put /root/words.txt /wordcount/input/ /export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar \ –input hdfs://http://node1.itcast.cn:8020/wordcount/input/words.txt /export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar \ –input hdfs://http://node1.itcast.cn:8020/wordcount/input/words.txt \ –output hdfs://http://node1.itcast.cn:8020/wordcount/output/result.txt
\ –parallelism 2
WEB UI截图如下:
五,Standalone HA 高可用集群
从上述架构图中,可发现JobManager存在单点故障(SPOF),一旦JobManager出现意外,整个集群无法工作。为了确保集群的高可用,需要搭建Flink的HA。(如果是部署在YARN上,部署YARN的HA),演示如何搭建Standalone HA模式。
1 原理
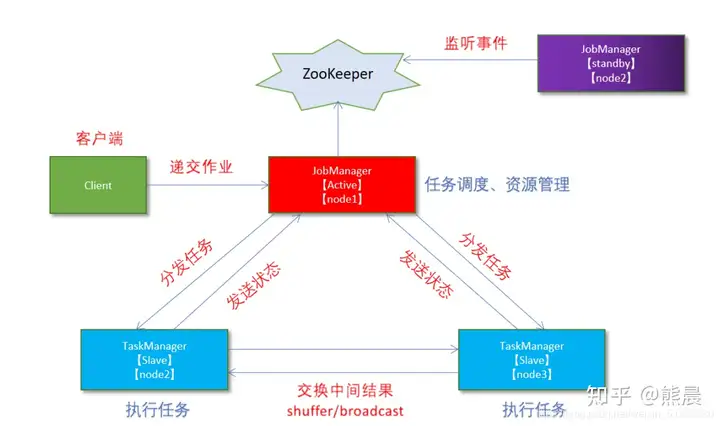
在 Zookeeper 的协助下,一个 Standalone的Flink集群会同时有多个活着的 JobManager,其中只有一个处于Active工作状态,其他处于 Standby 状态。当工作中的 JobManager 失去连接后(如宕机或 Crash),Zookeeper 会从 Standby 中选一个新的 JobManager 来接管 Flink 集群。
2 操作
1.集群规划
– 服务器: node1(Master + Slave): JobManager + TaskManager
– 服务器: node2(Master + Slave): JobManager + TaskManager
– 服务器: node3(Slave): TaskManager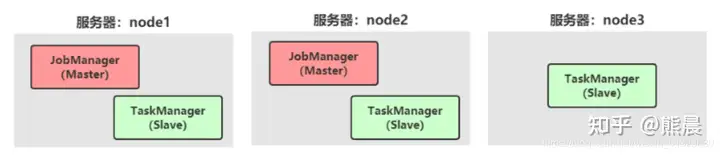
2.启动ZooKeeper
zookeeper-daemons.sh start
3.启动HDFS
hadoop-daemon.sh start namenode hadoop-daemons.sh start datanode
4.停止集群
/export/server/flink/bin/stop-cluster.sh
5.修改flink-conf.yaml
vim /export/server/flink/conf/flink-conf.yaml
增加如下内容:
state.backend: filesystem state.backend.fs.checkpointdir: hdfs://http://node1.itcast.cn:8020/flink-checkpoints state.savepoints.dir: hdfs://http://node1.itcast.cn:8020/flink-savepoints high-availability: zookeeper high-availability.storageDir: hdfs://http://node1.itcast.cn:8020/flink-ha/ high-availability.zookeeper.quorum: node1.itcast.cn:2181.itcast.cn,node2:2181,http://node3.itcast.cn:2181
配置解释如下:
#开启HA,使用文件系统作为快照存储 state.backend: filesystem #启用检查点,可以将快照保存到HDFS state.backend.fs.checkpointdir: hdfs://http://node1.itcast.cn:8020/flink-checkpoints #使用zookeeper搭建高可用 high-availability: zookeeper # 存储JobManager的元数据到HDFS high-availability.storageDir: hdfs://http://node1.itcast.cn:8020/flink-ha/ # 配置ZK集群地址 high-availability.zookeeper.quorum: node1.itcast.cn:2181,node2.itcast.cn:2181,http://node3.itcast.cn:2181
6.修改masters
vim /export/server/flink/conf/masters
第一台虚拟机IP:8081 第二台虚拟机IP:8081
7.同步配置文件
scp -r /export/server/flink/conf/flink-conf.yaml node2.itcast.cn:/export/server/flink/conf/ scp -r /export/server/flink/conf/flink-conf.yaml node3.itcast.cn:/export/server/flink/conf/ scp -r /export/server/flink/conf/masters node2.itcast.cn:/export/server/flink/conf/ scp -r /export/server/flink/conf/masters node3.itcast.cn:/export/server/flink/conf/
8.修改node2上的flink-conf.yaml
vim /export/server/flink/conf/flink-conf.yaml
jobmanager.rpc.address: 第二台虚拟机IP
9.重新启动Flink集群,node1上执行
/export/server/flink/bin/start-cluster.sh

10.使用jps命令查看
发现没有Flink相关进程被启动

11. 下载jar包并在Flink的lib目录下放入该jar包并分发使Flink能够支持对Hadoop的操作
因为在Flink1.8版本后,Flink官方提供的安装包里没有整合HDFS的jar
https://flink.apache.org/downloads.htmlhttps://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2- uber/2.7.5-10.0/flink-shaded-hadoop-2-uber-2.7.5-10.0.jar3 测试
1. 访问WebUI:
http://第一台虚拟机IP:8081/#/overview http://第二台虚拟机IP:8081/#/overview

2.执行wc
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar \ –input hdfs://http://node1.itcast.cn:8020/wordcount/input/words.txt
3.kill掉其中一个master
4.重新执行wc,还是可以正常执行
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar \ –input hdfs://http://node1.itcast.cn:8020/wordcount/input/words.txt
六、Flink On Yarn
在一个企业中,为了最大化的利用集群资源,一般都会在一个集群中同时运行多种类型的Workload,因此 Flink 也支持在 Yarn 集群运行。Flink on YARN前提:HDFS、YARN均启动。
1.原理
1)、为什么使用Flink On Yarn?
在实际开发中,使用Flink时,更多的使用方式是Flink On Yarn模式,原因如下:
-1.Yarn的资源可以按需使用,提高集群的资源利用率
-2.Yarn的任务有优先级,根据优先级运行作业
-3.基于Yarn调度系统,能够自动化地处理各个角色的 Failover(容错)当Flink on YARN 运行时,有如下特点:
○ JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控;
○ 如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager
到其他机器;
○ 如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn
ResourceManager 申请资源,重新启动 TaskManager;2)、Flink如何与Yarn进行交互?

1.Client上传jar包和配置文件到HDFS集群上
2.Client向Yarn ResourceManager提交任务并申请资源
3.ResourceManager分配Container资源并启动ApplicationMaster,然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager
JobManager和ApplicationMaster运行在同一个container上;
一旦他们被成功启动,AppMaster就知道JobManager的地址(AM它自己所在的机器);它就会为TaskManager生成一个新的Flink配置文件(他们就可以连接到JobManager);这个配置文件也被上传到HDFS上;此外,AppMaster容器也提供了Flink的web服务接口;
YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink
4.ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
5.TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务2 两种方式
1)、Session 会话模式

特点:需要事先申请资源,启动JobManager和TaskManager
优点:不需要每次提交作业申请资源,而是使用已经申请好的资源,从而提高执行效率
缺点:作业执行完成以后,资源不会被释放,因此一直会占用系统资源
应用场景:适合作业提交比较频繁的场景,小作业比较多的场景2)、Job 分离模式

特点:每次提交作业都需要申请一次资源
优点:作业运行完成,资源会立刻被释放,不会一直占用系统资源
缺点:每次提交作业都需要申请资源,会影响执行效率,因为申请资源需要消耗时间
应用场景:适合作业比较少的场景、大作业的场景
3.操作
1.关闭yarn的内存检查
vim /export/server/hadoop/etc/h
添加:
<!– 关闭yarn内存检查 –> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
此处需要关闭,因为对于flink使用yarn模式下,很容易内存超标,这个时候yarn会自动杀掉job。
2.同步
cd /export/server/hadoop/etc/hadoop scp -r yarn-site.xml root@第二台虚拟机IP:$PWD scp -r yarn-site.xml root@第三台虚拟机IP:$PWD
3.重启YARN
/export/server/hadoop/sbin/stop-yarn.sh /export/server/hadoop/sbin/start-yarn.sh
4 测试
1)、Session 会话模式
yarn-session.sh(开辟资源) + flink run(提交任务)
1.在yarn上启动一个Flink会话,node1上执行以下命令
/export/server/flink/bin/yarn-session.sh -d -jm 1024 -tm 1024 -s 2
说明:
# -tm 表示每个TaskManager的内存大小
# -s 表示每个TaskManager的slots数量
# -d 表示以后台程序方式运行
附录:yarn-session 命令使用帮助[root@node1 ~]# /export/server/flink/bin/yarn-session.sh –help Usage: Optional -at,–applicationType
2.查看UI界面

3.使用flink run提交任务:
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.jar \ –input hdfs://http://node1.itcast.cn:8020/wordcount/input
运行完之后可以继续运行其他的小任务
/export/server/flink/bin/flink run /export/server/flink/examples/batch/WordCount.ja
4.通过上方的ApplicationMaster可以进入Flink的管理界面

5.关闭yarn-session:
yarn application -kill application_1599402747874_0001

删除运行临时文件
rm -rf /tmp/.yarn-properties-root
2)、Job 分离模式
1.直接提交job
/export/server/flink/bin/flink run \ -m yarn-cluster -yjm 1024 -ytm 1024 /export/server/flink/examples/batch/WordCount.jar
# -m jobmanager的地址
# -yjm 1024 指定jobmanager的内存信息
# -ytm 1024 指定taskmanager的内存信息
2.查看UI界面
http://第一台虚拟机IP:8088/cluster
3.注意:
在之前版本中如果使用的是flink on yarn方式,想切换回standalone模式的话,如果报错需要
删除:【/tmp/.yarn-properties-root】rm -rf /tmp/.yarn-properties-root
因为默认查找当前yarn集群中已有的yarn-session信息中的jobmanager
5 参数总结
//参数将就着看,执行命令flink –help 就可以查看,不需要记,不会就查



















暂无评论内容