
1、概述
1.1、基础介绍
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
1.2、数据处理结构演变
1)传统数据处理架构
事务处理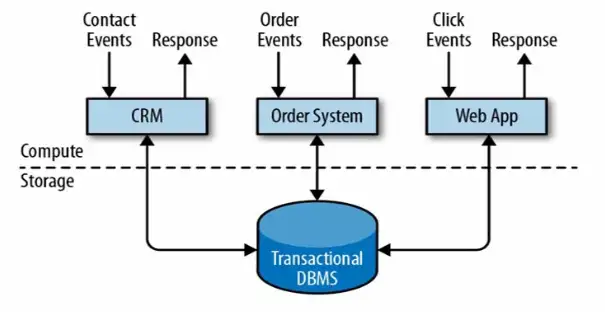
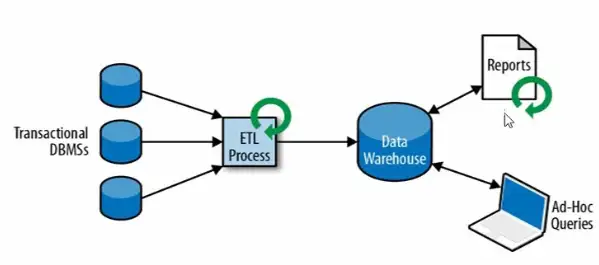
2)有状态的流式处理
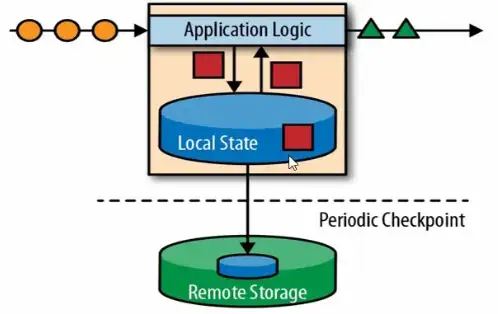
3)流处理的演变
lambda架构用两套系统,同时保证低延迟和结果准确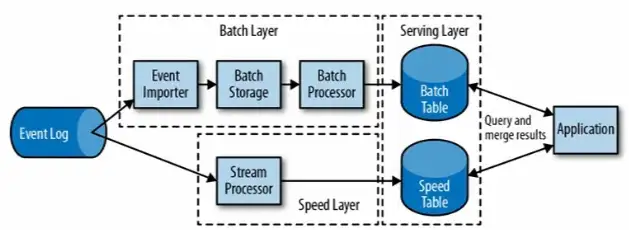
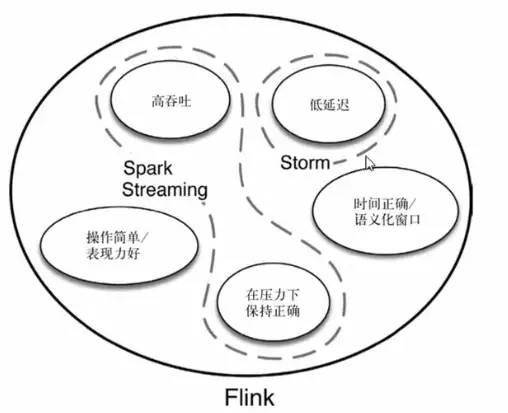
1.3、主要特点
事件驱动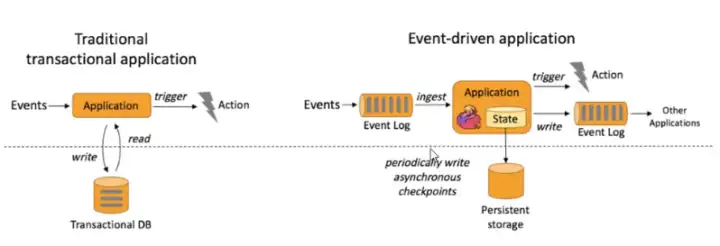
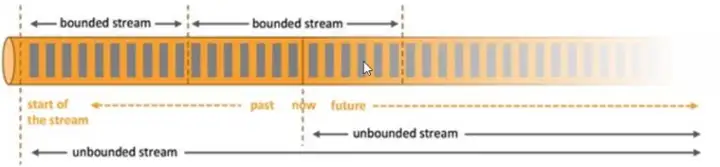
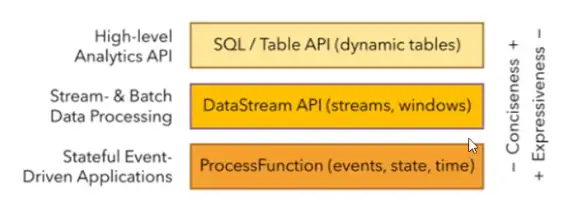
1.4、Flink vs Spark Streaming
流(stream)和微批(micro-batching)的处理数据模型的不同spark采用RDD模型flink基本模型是数据流,以及事件序列运行时架构spark将DAG划分为不同的tage,一个完成后才可以计算下一个flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理2、快速上手
2.1、批处理WordCount
配置:
flink-demo/pom.xml
flink-demo/pom.xml · GuangMujun/flink-learning – Gitee.com
注意:
flink的实现包中,有使用scala实现的,所以依赖要加上scala的版本号代码:
flink-demo/src/main/java/com/atguigu/wc/WordCount.java · GuangMujun/flink-learning – Gitee.com
效果:
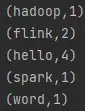
2.2、流处理WordCount
代码:
flink-demo/src/main/java/com/atguigu/wc/StreamWordCount.java · GuangMujun/flink-learning – Gitee.com
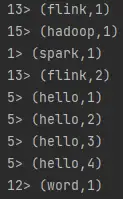
效果:
有状态的流式计算,状态是不断叠加上来的,> 左边的数字表示本地线程的编号,模拟分布式 ,可通过env.setParallelism(8);进行并行度的设置。
2.3、流式数据源测试
工具:本机的nc工具
注意:从程序启动参数中提取配置项
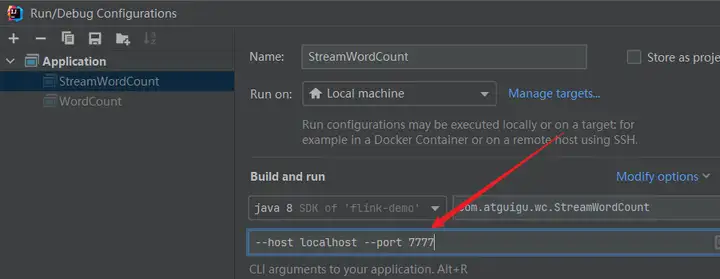
代码:
flink-demo/src/main/java/com/atguigu/wc/StreamWordCount.java · GuangMujun/flink-learning – Gitee.com
效果:

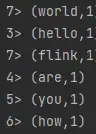
3、Flink部署
3.1、基础安装配置
3.1.1、原理
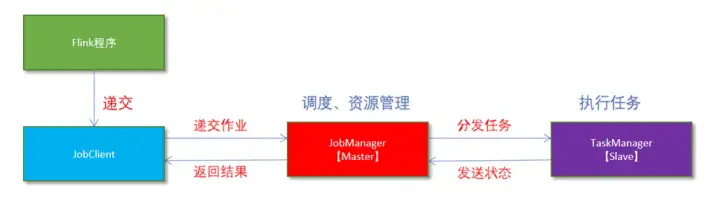
3.1.2、操作
1.下载安装包,文件大约300M
https://archive.apache.org/dist/flink/
2.上传flink-1.12.0-bin-scala_2.11.tgz到node1的指定目录
3.解压
tar -zxvf flink-1.12.0-bin-scala_2.11.tgz
4.如果出现权限问题,需要修改权限
chown -R root:root /export/server/flink-1.11.0
5.改名或创建软链接
mv flink-1.11.0 flink
ln -s /export/server/flink-1.12.0 /export/server/flink
3.1.3、测试
1.准备文件/root/words.txt
vim /root/words.txt
2.启动Flink本地“集群”
/export/server/flink/bin/start-cluster.sh
3.使用jps可以查看到下面两个进程
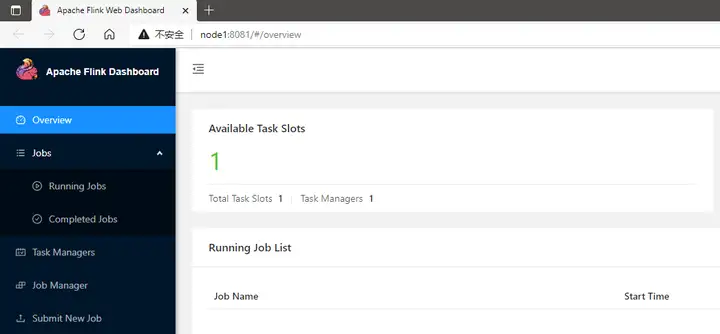
TaskManagerRunnerStandaloneSessionClusterEntrypoint4.访问Flink的Web UI
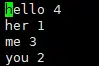
5.执行官方示例
6.停止Flink
基础配置
flink-conf.yaml
3.2、Job提交和运行
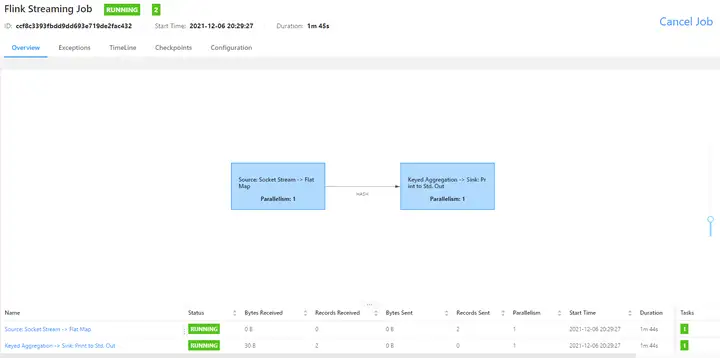
3.2.1、WEB界面提交
每一步都可以设置并行度,并行度设置以JAR包里程序写死的并行度为准
socketTextStream算子始终是1
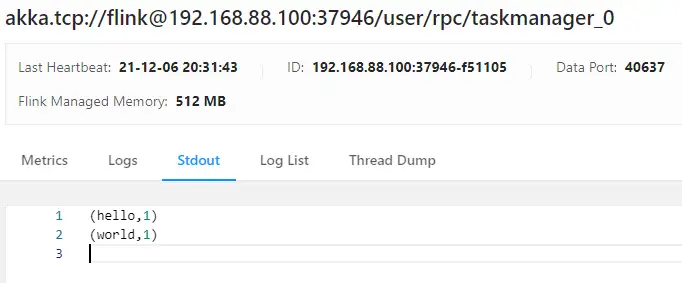
提交job前,记得nc -lk 7777,先运行起来 注意slots和并行度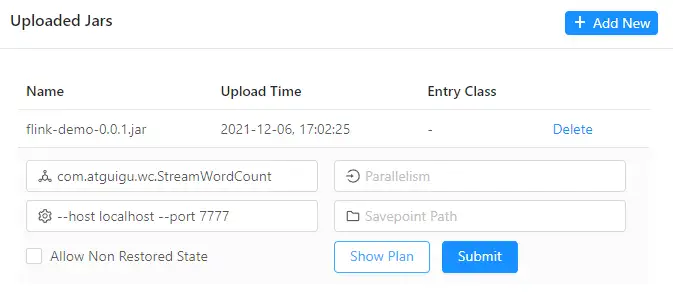

3.2.2、命令行Job操作
提交挺有意思的……


















暂无评论内容