
原标题:AI时代,你需要了解的AI 数据库架构设计和内存优化思路
作者 | 陈迪豪
编辑 | 邓艳琴
随着人工智能技术的发展和普及,越来越多的企业和组织需要处理和分析大量的数据,其中就包括了 AI 数据。AI 数据库为处理这些数据提供了更高效,更智能的方式,能够更好地支撑人工智能应用的发展。因此,目前 AI 数据库已经成为人工智能领域的热门技术之一。OpenMLDB 则是这里面的知名开源项目。
本文整理自 OpenMLDB PMC 陈迪豪在 QCon 全球软件开发大会(北京站)AI 基础架构分论坛上的发表的演讲实录。
希望大家通过本文能够了解三个方面的内容:前沿的 AI 数据库架构设计、数据库内存优化思路和实现细节以及 OpenMLDB 内存优化在 AI 场景的实践。
本文目录:
Al 数据库与内存性能优化 OpenMLDB 与 Spark 内存方案 OpenMLDB 统一编码优化实现内存优化在 AI 场景的应用实践
AI 数据库与内存性能优化
什么是 AI 数据库
随着 AlphaGo 到 chatGPT 等越来越多的 AI 应用的落地,为了应对越来越多的 AI 的需求,AI 的基础设施项目也越来越多,涵盖硬件芯片设计、机器学习框架,以及针对 AI 工程化落地的数据库,其中包括 OpenMLDB 和一些向量数据库。
AI 数据库是针对机器学习和 AI 开发的数据库,已逐渐成为 MLOps 的重要组件,支持包括离线和在线流程在内的 AI 应用的落地。
OpenMLDB 介绍
OpenMLDB 是专注于解决 AI 工程化落地的一种数据库,与传统数据库略有不同。它既不是像 Redis 或 MySQL 那样的在线数据库,也不是 OLAP 或 OLTP 数据库。相反,它是一种结合了离线和在线计算的数据库,可以满足机器学习工程化各种需求。OpenMLDB 的特点如下:
致力于解决 AI 工程化落地的数据治理难题 选用 SQL 和数据库开发体验降低开发门槛 天然保证线上线下计算一致性,实现毫秒级的计算延迟OpenMLDB 的使用
AI 数据库的使用流程与传统的数据库几乎没有区别。首先,OpenMLDB 有 CLI,提供建库建表等接口,可以插入或加载数据,这些功能与常见在线数据库非常相似。
但是 OpenMLDB 有一个独特的离线特征计算功能,可以对海量的特征和原始数据进行离线计算,例如存储在 HDFS 或 Hive 数仓中的数百 TB 的数据,对这些数据可以提交分布式离线计算任务。

用于离线特征计算的的 SQL 方案可以直接上线,一旦 SQL 上线,它就成为了一个在线的 IPC 服务,可以让客户端调用该服务传递原始数据输入,并返回经过特征计算后的结果。当结果返回后,任务可以将特征集成到 TensorFlow、PyTorch 等模型推理服务中,从而实现一个端到端的机器学习的落地的应用。
OpenMLDB 架构设计
OpenMLDB 的架构设计包括离线特征计算部分和在线实时引擎,这两部分通过一个统一的一致性执行计划生成器实现一致性。

这个一致性执行计划生成器涵盖了一致性的引擎 ASTTree parser,该引擎解析 SQL 语法和词法,生成离线和在线请求计划,完成逻辑计划生成、逻辑计划优化、物理计划生成、物理计划优化等操作。

在这个统一执行引擎中,我们使用了 OpenMLDB 提供的 SQL Parser 和 Validator 进行校验。同时,我们还使用了 planner 来生成逻辑计划和物理计划,并对其进行优化。由于我们使用的编程接口是 SQL,因此有很多优化空间,比如表达式下推、拼表、转重排等任务都可以在这个阶段完成。完成编程后,用户需要使用 Codegen,它可以为不同的硬件平台(例如 Mac、X86 的机器或 ARM 架构极其)生成不同的代码。最后,我们使用一个执行器来管理行的编码器,统一 Schemas 管理、状态管理和迭代器等功能。
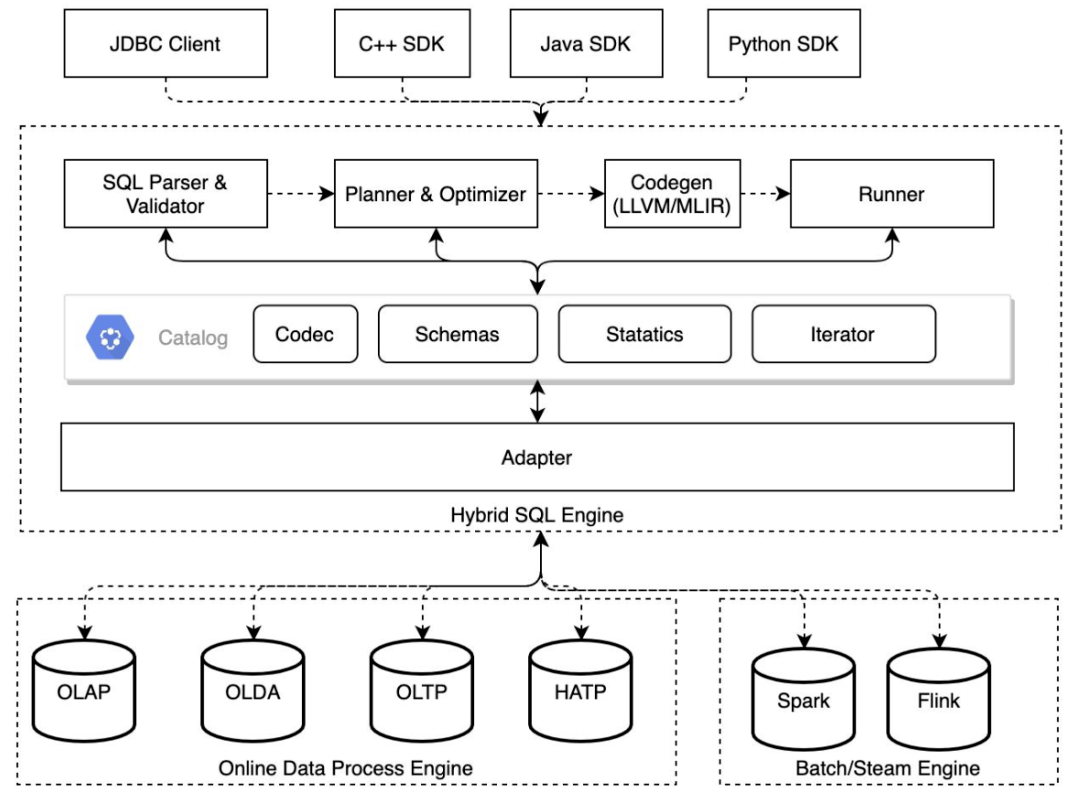
OpenMLDB 内存架构
OpenMLDB 的数据是以行编码的 。传统的数据库像是 MySQL 使用的数据编码也是行编码。行编码的好处是同一行随机查询的时候会非常快,在一行内的列都是使用的连续内存。这个设计对 OpenMLDB 的在线查询性能非常重要。Spark 虽然也是离线计算,但 Spark 内部支持读取 Parquet,而 Parquet 属于列存储,Spark 读到 Parquet 后,它在内部也会转成一个行编码的格式,方便后续做数据的迭代和查询。 OpenMLDB 离线和在线使用相同的 Parser、Optimizer 和 Codegen 。这是为了确保用户写的每一个表达式和生成计划都达到离线在线统一,从而生成一个 C 语言的函数代码,这个代码再根据不同的硬件平台编译成机器码。离线和在线统一使用同一套优化后的硬件码执行,这可从根本上保证它的特征一致性。 OpenMLDB 用的技术为 LLVM JIT,对表达式生成平台相关的优化执行代码 。JIT 代表 Just In Time compiler,无需预编译,它是把表达式放到云端,使用 LLVM 后,直接在代码里对表达式做编码,然后生成跟平台有关的优化执行代码。 离线集成 Spark, 基于 Java JNI 调用 C++ 代码接口 。由于离线的数据是海量的,要求大吞吐,必须支持分布式地执行。我们的离线集成了 Spark 和 Flink 的批处理。此外,OpenMLDB 是基于 Java 的 JNI 去调 C++ 的代码接口。总结一下,从性能角度考虑,OpenMLDB 数据是以行编码的方法来存储的。为了保证离线在线的一致性,OpenMLDB 相当于用 C++ 写了一套统一的 SQL 编译器,再使用 LLVM 做代码生成。对于离线的集成,我们集成了 Spark 和 Flink 的批处理,因为 Spark 是基于 JVM 的引擎,它只能通过 JNI 的方法调用 C++ 的接口。

思考一下

这个问题后续会进行解答。
OpenMLDB 与 Spark 内存方案
Spark 是大数据处理的事实标准,是所有大数据处理工具中不可或缺的一部分。作为一个分布式计算框架,从编程接口到计算性能方面,Spark 一直处于领先地位。然而,自 Spark 1.6 版本开始,其实现也遇到了计算瓶颈。这些瓶颈不仅来自硬件,也来自于代码逻辑本身。

为了解决这些瓶颈,Spark 引入了 Tungsten 内存优化方案,从最初使用简单的 Java 实现 row 格式,到实现分布式 RDD,再到最终使用 JVM 的 Unsafe 接口进行连续内存管理。这项优化方案还包括向底层指定级别的向量优化,从而进一步提升了 Spark 的性能。
Spark Tungsten 内存优化
Tungsten 内存优化方案包含以下三点:
内存管理 。Tungsten 内存优化方案重新设计了 Spark 的 row 内存管理,采用类似指针的方案来管理连续的内存,以优化列访问和后面的 Codegen 计算。 内存优化 。官方博客中提到,Java 的字符串实现会导致内存浪费。比如,一个四个字母的字符串 abcd,理论上只需要申请四个字节,但实际占用内存却可能达到 24 个字节。这是因为 Java 字符串实现中包含 12 个字节的 header,8 个字节的 hash 和 4 个字节的实际内容。Tungsten 的优化可以有效解决这个问题。 Tungsten 的优化 。 在优化前,Spark 的 row 实现是基于多个 column 对象的,每个 column 都是一个 Java 对象。 这导致 JVM 管理的小对象特别多,GC 压力特别大。 而 Tungsten 优化后,Spark 的 row 和 column 对象的生命周期其实是一样的,可以手动回收。 这个信息过去是无法告诉 GC 进行优化的,只能将对象引用设为 0 等待 JVM 回收 GC 压力也比较大。Spark UnsafeRow 优化
Spark Tungsten 包含了 UnsafeRow 优化。

它基于 JVM 提供的一种 Unsafe 的 API。客户可以向 JVM 申请一段连续的内存,并自行管理该内存。但是,由于该内存不会自动释放,所以存在内存泄漏的风险。
Spark UnsafeRow 优化是将所有行转换为 UnsafeRow 对象。该行对象还包含外部的 schema 属性,还有一个指针,指向一个包含单行所有列的连续内存。Spark 通过指针和偏移来访问用户需要的数据,例如读取的字节数、字节类型等。
此优化使用了行编码的 UnsafeRow,与 OpenMLDB 相似,它可以保证所需的数据在连续内存中,对于列的读性能很高。优化后,Spark Tungsten 可以减少对小对象的管理和 GC 压力。例如,如果用户以前的一行有 100 列共 1 万行,它将具有 100 万个小对象,而现在不需要这么多小对象,内存统一由 Spark 来管理。

上图总结的是 Spark 的行格式,拥有四列,每一列都是不同类型的数据,例如第一列是 int 类型,第二列是 string 类型,第三列是 double 类型,第四列也是 string 类型。在行的开头,有一个 nullbitset,是一个 64 位的长整型,可以表示从 -(2 的 32 次方)到 +(2 的 32 次方)。
然而,在 int 或 long 中无法表示 null。用户可以使用数字零表示有值,但是无法使用 int 表示 null。因此,在许多架构设计中,包括 OpenMLDB 和 Flink 中的行都要支持 null 值。换句话说,无论用户存储的是什么,如果用户想表示 null,都必须使用一个单独的位来表示。零表示有值,而 1 表示 null,这就是 nullbitset。因此,一般需要使用多少位来表示 null 取决于行中有多少列。
有一个稍微奇怪的地方是,行中的 int 在大多数操作系统实现中都是 32 位的,但在 Spark 中,它使用 64 位来表示。同样,由于字符串的长度可能是变长的,因此 Spark 中的字符串表示记录了大小和偏移量,用户可以在普通列类型的基础上,使用后面的变长区域来专门存储字符串内容。最后,用户可以根据偏移量和大小指针读取字符串内容。
然而,这里包含一些问题,例如,为什么 nullbitset 是 64 位?因为图表显示一共只有四列。理论上,四位就足够了。如果按最基本的单位,一个字节就可以了。但是,在 Spark 内部,为了读取访存方便,所有数据都按照 64 位来对齐。这意味着,无论是 int、double 还是 float,它们都使用 64 位,这会导致一些浪费。另外,例如,UnsafeRow 没有版本信息,换句话说,如果内存结构发生变化,相应的代码也必须进行更改。还有一个问题,用户通过 row 指针无法知道行的大小是多少。用户只能像 Spark 一样,在外部有一个 Java 对象,专门维护这个 row 的长度。
总结如下:

在编写 Spark 代码时,通常使用其 DataFrame 对象进行操作,将其转换为 RDD 后,可以通过查询执行器对象(queryExecution)获取 RDD 的底层数据结构 internalRow,而其默认实现就是 UnsafeRow。通过将 internalRow 转换为 UnsafeRow 对象,可以方便地按照偏移量读取想要的值。这一点与我们在 OpenMLDB 中进行的内存优化和内存对齐等操作密切相关。
然而,Spark UnsafeRow 也存在一些问题。首先,它的数据结构不够紧凑,虽然能够提高缓存性能,但也会造成一些内存浪费。其次,UnsafeRow 没有版本信息,这可能会在代码升级后出现兼容性问题。最后,查询执行器获取 RDD 列信息的过程会触发底层计算,这是一个已知的 bug,暂时就不展开细说了。
Spark 对比 OpenMLDB Spark
Spark 是在版本 1.6 的时候就开始做的优化。2.0 的时候已经非常稳定。下图是 OpenMLDB 和 Spark 3.0 的性能对比。纵坐标是运行时间,OpenMLDB 在这种单窗口下计算性能可以提升一倍,并且在多窗口下性能可以提升五倍,它的运行时间减少到原来的 1/6。
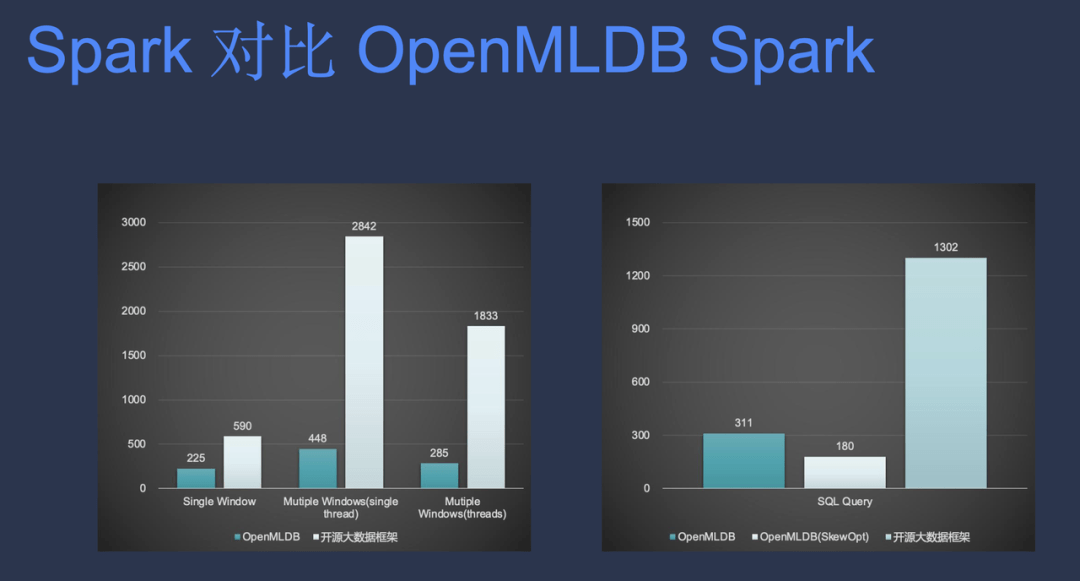
此外,OpenMLDB 做了一些额外的倾斜优化,多线程以后,它的性能提升可能更大。这个额外的倾斜优化也是 Spark 本身没有的部分。
可以看到,即使 Spark 做了这么多内存优化,减少了 Java 的小对象,也通过了 UnsafeRow 的接口,但是它跟 OpenMLDB 纯 C 语言实现的代码在性能上还是有较大差异。
OpenMLDB 统一编码优化实现
本章节介绍 OpenMLDB 如何对接 Spark 性能优化。
OpenMLDB 行内存编码优化
和 Spark 一样,基于行存储,最大化在线行读取性能 相比于 Spark,基于 C++ 指针实现,没有 GC overhead 相比于 Spark,增加 Version header,支持多版本格式 相比于 Spark, Nullbitset 以 byte (8 bits) 为单位按需分配 相比于 Spark,不同类型按需分配空间,内存布局更加紧凑这里展示 OpenMLDB 行的内存方案:

前面显示的是 6 个 byte 的 Header。其中因为它不会有超过 64 个版本,所以每个版本只需要一个 byte 来表示。这里用 32 位来表示一个 Size。BitMap set 是以 byte 为单位,最小是一个 byte。每个 field 里面的长短是可以变的。比如,一个 field 是 int,它只占 32 个 bit,Long 占 64 个 bit。后面同样也有个变长的一个存储字符串的区域。这个存储字符串的区域,OpenMLDB 也做了一个优化。它的每一个字符串,只要存下 offset 就可以了。所以它的 Size 其实是后面一个 offset 减去前面一个 offset,等于它实际的长度。而这就代表它把字符串的 Size 给优化掉了。此外,它不一定需要用 32 位去表示 size 的长度。而是可以根据实际 row 的大小去算这个 offset 的值,不一定是一个 32 位的 int。
Spark 与 OpenMLDB 行内存对比
下图是 OpenMLDB 与 Spark 的行内存的对比。几个特点包括:
内存更紧凑,支持多版本和包含整个行 size,所需存储的空间也更小。 OpenMLDB Row,它跟 Spark 相比,多了一个 row size 和 header。但是它在外部不用单独存 size,而且 nullbitset 更小。所有的类型都是可以根据它实际的占用空间来表示。string offset 指针的位置用一个 byte 来表示,长度是 1。最终算出来的整个 row size 是 255 byte。这导致内存优化大幅度的减少了接近 45%。尤其是数据量越大,每一行所占的空间越少。这跟所列的类型有关。列数越多,可以节省的内存空间也越多。思考解答
回到前面的问题,方案是用 Spark 把数据读出来。Spark 的第一个 op 是从 Parquet 转成 UnsafeRow 的计算。它把 Spark 的数据转成一个 Spark CodeGen 代码支持的格式。但 C++ 代码怎么去读取转化后的格式呢?
答案是在离线引擎的架构上去支持 Spark 的数据格式 。在离线引擎实际执行的时候去调用 Spark API,但是这里面的问题是两个系统的内存格式本身并不兼容。而 OpenMLDB 提供了 C 的 API 是基于内部 row 的格式, Spark 提供的这个 RDD[Row] 和 RDD[internalRow],返回的都是 Scala 对象,基于 UnsafeRow 的格式。
OpenMLDB 离线引擎与 Spark 整合
兼容的方案有三个:
GitHub 上代码里面默认的方案叫 encoder 和 decoder。 修改 Spark 的源码。但是这会导致后期不好维护,因为改动 Spark 底层的代码太多。 修改 OpenMLDB 的代码,去兼容 Spark UnsafeRow 的格式。(采取方案)OpenMLDB UnsafeRowOpt 优化
最后整理支持性能优化的方案:
通过 execution engine,拿到 RDD[internalRow],转成 UnsafeRow。然后把这个 UnsafeRow 的指针传给 C 接口。如有需要,可以直接从 UnsafeRow 里面拿到列的值,把它转成 ByteArray 指针传递给 C 函数,就可以用 C 的方法去访问。最后从测试结果来看性能提升也是非常可观的。 OpenMLDB 测试了十个场景,有些场景的列数特别的多,有些列数比较少。在这可以看出加上 UnsafeRow 优化以后,这个运行的时间从 500 多分钟降到 100 多分钟,大部分性能提升都非常明显。 后面 OpenMLDB 也做了一些火焰图性能分析。如果 OpenMLDB 不做优化,它的行计算占比是百分之三点多,占总额计算时间是 3.4。加上性能优化后,行计算占比降到 1.43,整体任务的计算时间减少了。而且没有编码,开销也小很多。所以加上 UnsafeRow 优化以后,OpenMLDB 的整体性能会比 Spark 开源版本快很多。内存优化在 AI 场景的应用实践
以推荐系统为例,用户可以基于机器学习做建模,并且保证离线在线一致性。
作者简介
陈迪豪,目前担任 OpenMLDB PMC 以及第四范式平台架构师,曾担任小米云深度学习平台架构师以及优思德云计算公司存储和容器团队负责人。活跃于分布式系统、机器学习相关的开源社区,也是 HBase、OpenStack、TensorFlow、TVM 等开源项目贡献者。QCon 北京 2022 明星讲师。
活动推荐:
5 月 26 日 -5 月 27 日,QCon 全球软件开发大会即将落地广州,从下一代软件架构、研发效能提升、DevOps vs 平台工程、AIGC、数据驱动业务、工业互联网、出海的思考、金融分布式核心系统、大前端架构等角度与你探讨,欢迎你来现场打卡交流~返回搜狐,查看更多
责任编辑:



















暂无评论内容