
对于NLP 爱好者来说HuggingFace肯定不会陌生,因为现在几乎一提到NLP就会有HuggingFace的名字出现,HuggingFace为NLP任务提供了维护了一系列开源库的应用和实现,虽然效率不是最高的,但是它为我们入门和学习提供了非常好的帮助,今天我们来看一下用于NLP任务的数据集总结。
安装
这一步非常简单,我们将使用两个开源库。
pip install transformers datasets
数据集提供的方法
通过文档我们看到了一些主要方法。 第一个是数据集的列表,可以看到HuggingFace提供了 3500 个可用数据集
from datasets import list_datasets, load_dataset, list_metrics, load_metric
# Print all the available datasets
print(list_datasets())要实际使用数据集时可以使用 load_dataset 方法进行加载
dataset = load_dataset(acronym_identification)
加载数据集后会返回一个数据集对象。
使用数据集对象
这里的数据集并不是使用传统的 csv 或 excel 格式,而是使用对象形式,该对象以某种结构存储数据集的元数据。 当打印数据集时,可以看到:
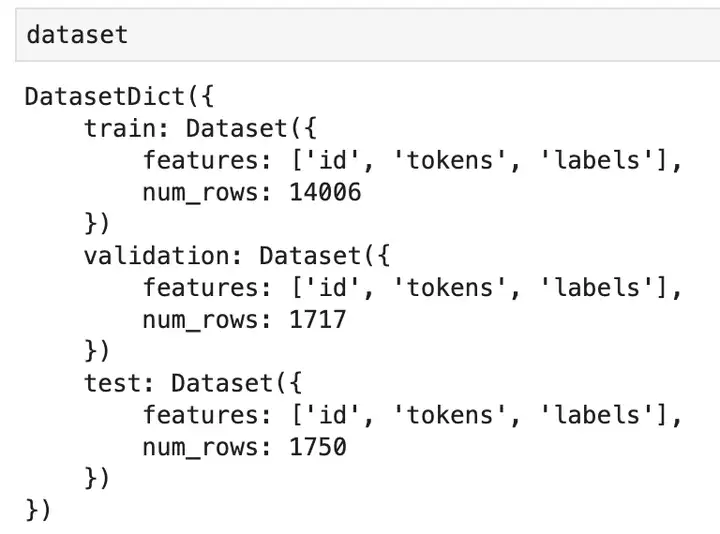
内置的数据集已经被拆分好了相应的数据阶段。 在 features 和 num_rows 键中说明了列及样本数量。
数据集对象的查询的在语法上与使用 Pandas DataFrame 的操作非常相似。 以下是一些可用于获取有关对象的更多信息的方法。
dataset[train][0]

特征提取
dataset[train].features

数据集描述
如果需要有关数据集来源或创建方式的更多信息,还可以获得背景信息和引文等等。
dataset[train].description

dataset[train].citation

自定义数据集加载
我们在最终使用的时候肯定会用到自己的数据,这时仍然可以将本地 CSV 文件和其他文件类型加载到Dataset 对象中。 例如,假设有一个 CSV 文件,可以简单地将其传递给 load_dataset 方法。
dataset = load_dataset(csv, data_files=train.csv)
也可以处理多个 CSV 文件
dataset = load_dataset(csv, data_files=[train.csv, test.csv])
当使用 HuggingFace 提供的预训练模型对自己的数据集进行微调时,使用自定义数据集会非常方便。
总结
Hugging Face 为我们提供了提供的大量资源,使端到端处理大型 NLP 和 ML 工作负载变得容易。虽然在灵活性等某些方面还是不足,但是Hugging Face是每个NLP爱好者都应该关注的库。
作者:Ram Vegiraju





















暂无评论内容