公众号 ““计算广告生态””
一、重要知识点回顾1.1 时间语义1.2 分配时间戳的接口二、代码分析2.1程序说明&注意事项2.2 追踪 WaterMark 12.3 追踪 WaterMark 22.4 追踪 WaterMark 3三、迟到的数据3.1 丢弃3.2 allowedLateness 指定允许数据延迟的时间3.3 sideOutputLateData 收集迟到的数据四、多并行度下的应用
主要是针对数据乱序的问题,需要使用 eventtime 和 watermark 来解决
后面针对迟到的数据也会进行相应的处理说明
代码版本
Flink : 1.10.0
Scala : 2.12.6
抓住以及涉及到的时间点,展开分析
时间1: EventTime的时间点
时间2: 当前最大时间点(有可能产生延迟的数据,那么最大时间点就是前一个数据的时间点)
时间3: Watermark时间点
时间4: 窗口的时间范围【左闭右开】
一、重要知识点回顾
1.1 时间语义
Event Time:事件实际发生而产生的时间
Ingestion time:数据进入 Flink 处理框架的时间
Processing Time:事件被处理时当前系统的时间,是基于机器的时间属性
在一般的语境下,一般选取的是 Event Time,即实际事件发生的时间点,也是符合事件发生进而分析的逻辑的。
其他的语义可能在监控或者另外的一些场景下会使用到
本文就围绕 Event Time 进行讨论
1.2 分配时间戳的接口
Flink 暴露了 TimestampAssigner 接口供我们实现,使我们可以自定义如何从事件数据中抽取时间戳。
MyAssigner 有两种类型
Assigner With Periodic WatermarksAssigner With Punctuated Watermarks
以上两个接口都继承自 TimestampAssigner
一般会自定义一个周期性的时间戳接口,方便清晰
【例子】自定义一个周期性的时间戳抽取:
class PeriodicAssigner extends AssignerWithPeriodicWatermarks[(String, Long)] {
val bound: Long = 60 * 1000 // 延时为1分钟
var maxTs: Long = Long.MinValue // 观察到的最大时间戳
override def getCurrentWatermark: Watermark = {
new Watermark(maxTs – bound)
}
override def extractTimestamp(element: (String, Long), previousTS: Long) = {
element._2
}
}
代码中的 extractTimestamp 方法是从数据本身中提取 EventTime getCurrentWatermar 方 法 是 获 取 当 前 水 位 线 , 利 用 currentMaxTimestamp – maxOutOfOrderness 这里的 maxOutOfOrderness 表示是允许数据的最大乱序时间
所以在这里我们使用的话也实现接口 AssignerWithPeriodicWatermarks
二、代码分析
先把完整代码贴出来
package com.tech.timeandwatermark
import java.text.SimpleDateFormat
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.scala.{DataStream, OutputTag, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import scala.collection.mutable.ArrayBuffer
import scala.util.Sorting
object StreamingWindowWatermarkScala {
def main(args: Array[String]): Unit = {
// socket 的端口号
val port = 9000
// 运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
import org.apache.flink.api.scala._
// 使用EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 设置并行度为 1,默认并行度是当前机器的 cpu 数量
env.setParallelism(1)
val text = env.socketTextStream(“127.0.0.1”, port, \n)
//解析输入的数据
val inputMap = text.map(line => {
val arr = line.split(“,”)
(arr(0), arr(1).toLong)
})
// 抽取 timestamp 和生成 watermark
val waterMarkStream = inputMap.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String, Long)] {
var currentMaxTimestamp = 0L
var maxOutOfOrderness = 10000L // 最大允许的乱序时间是10s
val sdf = new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss.SSS”)
// 定义生成 watermark 的逻辑, 默认 100ms 被调用一次
// 当前最大的时间点 – 允许的最大时间
override def getCurrentWatermark = new Watermark(currentMaxTimestamp – maxOutOfOrderness)
// 提取 timestamp
override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = {
val timestamp = element._2
// 这里想象一个迟到的数据时间,所以这里得到的是当前数据进入的最大时间点
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp)
val id = Thread.currentThread().getId
println(“currentThreadId:” + id + “,key:” + element._1 + “,eventtime:[“ + element._2 + “|” + sdf.format(element._2) + “],currentMaxTimestamp:[“ + currentMaxTimestamp + “|” + sdf.format(currentMaxTimestamp) + “],watermark:[“ + getCurrentWatermark().getTimestamp + “|” + sdf.format(getCurrentWatermark().getTimestamp) + “]”)
timestamp
}
})
// 保存被丢弃的数据, 定义一个 outputTag 来标识
// val outputTag = new OutputTag[Tuple2[String, Long]](“late-data”) {}
// 分组, 聚合
val window = waterMarkStream.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(3))) //按照消息的EventTime分配窗口,和调用TimeWindow效果一样
// .allowedLateness(Time.seconds(2)) //在 WaterMark 基础上还可以延迟2s, 即:数据迟到 2s
// .sideOutputLateData(outputTag)
.apply(new WindowFunction[(String, Long), String, Tuple, TimeWindow] {
/**
* Evaluates the window and outputs none or several elements.
*
* @param key The key for which this window is evaluated.
* @param window The window that is being evaluated.
* @param input The elements in the window being evaluated.
* @param out A collector for emitting elements.
* @throws Exception The function may throw exceptions to fail the program and trigger recovery.
*
* 对 window 内的数据进行排序,保证数据的顺序
*/
override def apply(key: Tuple, window: TimeWindow, input: Iterable[(String, Long)], out: Collector[String]): Unit = {
println(“key值:”, key)
val keyStr = key.toString
val arrBuf = ArrayBuffer[Long]()
val ite = input.iterator
while (ite.hasNext) {
val tup2 = ite.next()
arrBuf.append(tup2._2)
}
val arr = arrBuf.toArray
Sorting.quickSort(arr)
val sdf = new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss.SSS”)
val result = keyStr + “,” + arr.length + “, data_range[“ +
sdf.format(arr.head) + “,” + sdf.format(arr.last) + “], window [“ + // 数据的开始时间 和 结束时间
sdf.format(window.getStart) + “,” + sdf.format(window.getEnd) + “)” // 该窗口的开始时间 和 结束时间[) -> 记得左闭右开
out.collect(result)
}
})
// 侧输出流
// val sideOutput: DataStream[Tuple2[String, Long]] = window.getSideOutput(outputTag)
// sideOutput.print(“side_lated_data”)
window.print()
// 因为 flink 默认懒加载, 所以必须调用 execute 方法, 上面的代码才会执行
env.execute(“StreamingWindowWatermarkScala”)
}
}
2.1程序说明&注意事项
使用socket接收数据,在终端使用 nc -l 9000 来启动socket数据的输入数据的输入格式是 【key,timestamp】, 例如:flink,1593421135000然后通过程序中时间戳和窗口的时间打印进而理解EventTime下的窗口的使用 以及 针对乱序数据的处理程序中的最大允许的乱序时间是 10s,窗口大小为 3s
在这里窗口的 3s 是系统给划分好的,而不是从程序启动开始 3s 的时间分割,例如 1min 的时间分割
注意以下时间分割左闭右开
[00:00:00,00:00:03)
[00:00:03,00:00:06)
[00:00:06,00:00:09)
[00:00:09,00:00:12)
[00:00:12,00:00:15)
[00:00:15,00:00:18)
[00:00:18,00:00:21)
[00:00:21,00:00:24)
[00:00:24,00:00:27)
[00:00:27,00:00:30)
[00:00:30,00:00:33)
[00:00:33,00:00:36)
[00:00:36,00:00:39)
[00:00:39,00:00:42)
[00:00:42,00:00:45)
[00:00:45,00:00:48)
[00:00:48,00:00:51)
[00:00:51,00:00:54)
[00:00:54,00:00:57)
[00:00:57,00:01:00)
在这里,EventTime + WaterMark + Window 都混到一起了
所以,再强调: EventTime + WaterMark 是为了处理乱序数据,而在Window加入之后,根据自身的 EventTime,将数据划分到不同的 Window 中,如果 window 中有数据,则当 Watermark 时间>=Event Time 时,就符合了 Window 触发的条件了,最终决定 Window 触发,还是由数据本身的 Event Time 所属的 window 中的 window_end_time 决定。
例如【maxOutOfOrderness=10s】:
a. EventTime:2018-10-01 10:11:22.000,WaterMark:2018-10-01 10:11:23.000
=> 不会触发,虽然 WaterMark>EventTime,但是由于整个 Window[00:00:21,00:00:24)中所有数据没有过了WaterMark,所以不会触发
b. EventTime:2018-10-01 10:11:22.000,WaterMark:2018-10-01 10:11:24.000
=> 会触发, WaterMark>EventTime所在窗口的endtime,Window[00:00:21,00:00:24)中所有数据过了WaterMark,所以就会触发
2.2 追踪 WaterMark 1
通过追踪 EventTIme + WaterMark + Window 来进行各个时间点的梳理
经过这几个步骤的时间点梳理,就对 Flink 所涉及的时间问题,有一个清晰的了解
首先启动 nc,输入数据 [key,timestamp]
$ nc -l 9000
flink,1593421135000
看输出:
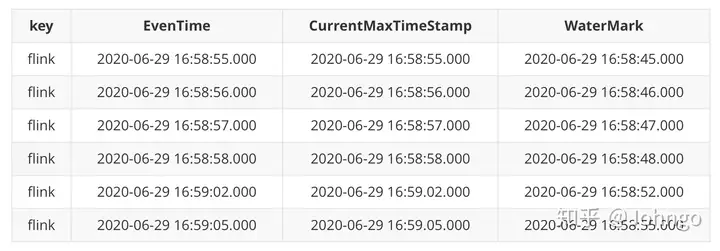
currentThreadId:65,key:flink,eventtime:[1593421135000|2020-06-29 16:58:55.000],currentMaxTimestamp:[1593421135000|2020-06-29 16:58:55.000],watermark:[1593421125000|2020-06-29 16:58:45.000]
规整一下:
2.3 追踪 WaterMark 2
再往下写几个时间点看看
$ nc -l 9000
flink,1593421135000
flink,1593421136000
flink,1593421137000
flink,1593421138000
flink,1593421142000
flink,1593421145000
看看输出:
currentThreadId:65,key:flink,eventtime:[1593421135000|2020-06-29 16:58:55.000],currentMaxTimestamp:[1593421135000|2020-06-29 16:58:55.000],watermark:[1593421125000|2020-06-29 16:58:45.000]
currentThreadId:65,key:flink,eventtime:[1593421136000|2020-06-29 16:58:56.000],currentMaxTimestamp:[1593421136000|2020-06-29 16:58:56.000],watermark:[1593421126000|2020-06-29 16:58:46.000]
currentThreadId:65,key:flink,eventtime:[1593421137000|2020-06-29 16:58:57.000],currentMaxTimestamp:[1593421137000|2020-06-29 16:58:57.000],watermark:[1593421127000|2020-06-29 16:58:47.000]
currentThreadId:65,key:flink,eventtime:[1593421138000|2020-06-29 16:58:58.000],currentMaxTimestamp:[1593421138000|2020-06-29 16:58:58.000],watermark:[1593421128000|2020-06-29 16:58:48.000]
currentThreadId:65,key:flink,eventtime:[1593421142000|2020-06-29 16:59:02.000],currentMaxTimestamp:[1593421142000|2020-06-29 16:59:02.000],watermark:[1593421132000|2020-06-29 16:58:52.000]
currentThreadId:65,key:flink,eventtime:[1593421145000|2020-06-29 16:59:05.000],currentMaxTimestamp:[1593421145000|2020-06-29 16:59:05.000],watermark:[1593421135000|2020-06-29 16:58:55.000]
规整一下:
现在看下,WaterMark 的时间点和 EvenTime 已经一样了,但是程序没有输出任何的东西
理由:WaterMark 对应的 2020-06-29 16:58:55.000,也就是 EventTime 该时间点所在的 Window是 [00:00:54,00:00:57),整个 Window 不是完全的超多 WaterMark。因此,只有 WaterMark 达到了 Window的 end 时间点 00:00:57,才能有该窗口的数据输出
继续输入数据看看
2.4 追踪 WaterMark 3
socket数据输入:
$ nc -l 9000
flink,1593421135000
flink,1593421136000
flink,1593421137000
flink,1593421138000
flink,1593421142000
flink,1593421145000
flink,1593421146000
flink,1593421147000
看输出
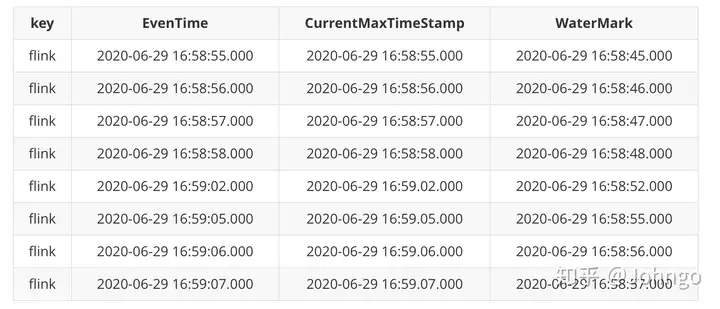
currentThreadId:65,key:flink,eventtime:[1593421135000|2020-06-29 16:58:55.000],currentMaxTimestamp:[1593421135000|2020-06-29 16:58:55.000],watermark:[1593421125000|2020-06-29 16:58:45.000]
currentThreadId:65,key:flink,eventtime:[1593421136000|2020-06-29 16:58:56.000],currentMaxTimestamp:[1593421136000|2020-06-29 16:58:56.000],watermark:[1593421126000|2020-06-29 16:58:46.000]
currentThreadId:65,key:flink,eventtime:[1593421137000|2020-06-29 16:58:57.000],currentMaxTimestamp:[1593421137000|2020-06-29 16:58:57.000],watermark:[1593421127000|2020-06-29 16:58:47.000]
currentThreadId:65,key:flink,eventtime:[1593421138000|2020-06-29 16:58:58.000],currentMaxTimestamp:[1593421138000|2020-06-29 16:58:58.000],watermark:[1593421128000|2020-06-29 16:58:48.000]
currentThreadId:65,key:flink,eventtime:[1593421142000|2020-06-29 16:59:02.000],currentMaxTimestamp:[1593421142000|2020-06-29 16:59:02.000],watermark:[1593421132000|2020-06-29 16:58:52.000]
currentThreadId:65,key:flink,eventtime:[1593421145000|2020-06-29 16:59:05.000],currentMaxTimestamp:[1593421145000|2020-06-29 16:59:05.000],watermark:[1593421135000|2020-06-29 16:58:55.000]
currentThreadId:65,key:flink,eventtime:[1593421146000|2020-06-29 16:59:06.000],currentMaxTimestamp:[1593421146000|2020-06-29 16:59:06.000],watermark:[1593421136000|2020-06-29 16:58:56.000]
currentThreadId:65,key:flink,eventtime:[1593421147000|2020-06-29 16:59:07.000],currentMaxTimestamp:[1593421147000|2020-06-29 16:59:07.000],watermark:[1593421137000|2020-06-29 16:58:57.000]
(key值:,(flink))
(flink),2, data_range[2020-06-29 16:58:55.000,2020-06-29 16:58:56.000], window [2020-06-29 16:58:54.000,2020-06-29 16:58:57.000)
发现已经有 key 值以及相关数据的输出了,说明触发了 Window 中的数据,WaterMark 生效
规整一下:
在最后一条数据输入的时候,触发 WaterMark 生效,打印出:
# key值,数据条数,数据的时间范围,Window的时间范围
(flink),2, data_range[2020–06–29 16:58:55.000,2020–06–29 16:58:56.000], window [2020–06–29 16:58:54.000,2020–06–29 16:58:57.000)
也就是把最开始的两条数据相关信息打印出来了,都处于 Window 的 [16:58:54,16:58:57),从 54s开始到57s,不包含 57s
此时,我们已经看到,window 的触发要符合以下2个条件: 1、watermark 时间 >= window_end_time 2、在[window_start_time,window_end_time)区间中有数据存在,注意是左闭右开的区间 同时满足了以上 2 个条件,window 才会触发
至此也就说明了EventTime 和 WaterMark 处理一定范围内的乱序数据,尤其是窗口之间的有序
那么,对于迟到太久的数据的处理方式呢?
三、迟到的数据
三种方案:
1.丢弃(默认,不处理的情况下)
2.allowedLateness 指定允许数据延迟的时间
3.sideOutputLateData 收集迟到的数据
3.1 丢弃
在上述数据输入的基础上,输入一个时间较久的数据
上面的 Window 的 [00:00:54,00:00:57),咱们输入一个 00:00:53 的数据
$ nc -l 9000
flink,1593421135000
flink,1593421136000
flink,1593421137000
flink,1593421138000
flink,1593421142000
flink,1593421145000
flink,1593421146000
flink,1593421147000
flink,1593421148000
flink,1593421134000 # 16:58:53 的数据
flink,1593421135000 # 16:58:54 的数据
再看看结果输出:
currentThreadId:66,key:flink,eventtime:[1593421135000|2020-06-29 16:58:55.000],currentMaxTimestamp:[1593421135000|2020-06-29 16:58:55.000],watermark:[1593421125000|2020-06-29 16:58:45.000]
currentThreadId:66,key:flink,eventtime:[1593421136000|2020-06-29 16:58:56.000],currentMaxTimestamp:[1593421136000|2020-06-29 16:58:56.000],watermark:[1593421126000|2020-06-29 16:58:46.000]
currentThreadId:66,key:flink,eventtime:[1593421137000|2020-06-29 16:58:57.000],currentMaxTimestamp:[1593421137000|2020-06-29 16:58:57.000],watermark:[1593421127000|2020-06-29 16:58:47.000]
currentThreadId:66,key:flink,eventtime:[1593421138000|2020-06-29 16:58:58.000],currentMaxTimestamp:[1593421138000|2020-06-29 16:58:58.000],watermark:[1593421128000|2020-06-29 16:58:48.000]
currentThreadId:66,key:flink,eventtime:[1593421142000|2020-06-29 16:59:02.000],currentMaxTimestamp:[1593421142000|2020-06-29 16:59:02.000],watermark:[1593421132000|2020-06-29 16:58:52.000]
currentThreadId:66,key:flink,eventtime:[1593421145000|2020-06-29 16:59:05.000],currentMaxTimestamp:[1593421145000|2020-06-29 16:59:05.000],watermark:[1593421135000|2020-06-29 16:58:55.000]
currentThreadId:66,key:flink,eventtime:[1593421146000|2020-06-29 16:59:06.000],currentMaxTimestamp:[1593421146000|2020-06-29 16:59:06.000],watermark:[1593421136000|2020-06-29 16:58:56.000]
currentThreadId:66,key:flink,eventtime:[1593421147000|2020-06-29 16:59:07.000],currentMaxTimestamp:[1593421147000|2020-06-29 16:59:07.000],watermark:[1593421137000|2020-06-29 16:58:57.000]
(key值:,(flink))
(flink),2, data_range[2020-06-29 16:58:55.000,2020-06-29 16:58:56.000], window [2020-06-29 16:58:54.000,2020-06-29 16:58:57.000)
currentThreadId:66,key:flink,eventtime:[1593421148000|2020-06-29 16:59:08.000],currentMaxTimestamp:[1593421148000|2020-06-29 16:59:08.000],watermark:[1593421138000|2020-06-29 16:58:58.000]
currentThreadId:66,key:flink,eventtime:[1593421134000|2020-06-29 16:58:54.000],currentMaxTimestamp:[1593421148000|2020-06-29 16:59:08.000],watermark:[1593421138000|2020-06-29 16:58:58.000]
currentThreadId:66,key:flink,eventtime:[1593421135000|2020-06-29 16:58:55.000],currentMaxTimestamp:[1593421148000|2020-06-29 16:59:08.000],watermark:[1593421138000|2020-06-29 16:58:58.000]
规整一下
打印出来的信息是, 并没有包含2020-06-29 16:58:54.000 和 2020-06-29 16:58:55.000相关的数据,即被丢弃了
(flink),
2,
data_range[2020-06-29 16:58:57.000,2020-06-29 16:58:58.000],
window [2020-06-29 16:58:57.000,2020-06-29 16:59:00.000)
3.2 allowedLateness 指定允许数据延迟的时间
通过 Watermark 机制来处理 out-of-order 的问题,属于第一层防护,属于全局性的防护,通常说的乱序问题的解决办法,就是指这类;通过窗口上的 allowedLateness 机制来处理 out-of-order 的问题,属于第二层防护,属于特定Window operator 的防护,late element 的问题就是指这类。
allowedLateness只针对Event Time有效
在某些情况下,我们希望对迟到的数据再提供一个宽容的时间。 Flink 提供了 allowedLateness 方法可以实现对迟到的数据设置一个延迟时间,在指定延迟时间内到达的数据还是可以触发 window 执行的
在代码中加上 allowedLateness 就好
下面验证一下,还选取上面验证的数据进行:
$ nc -l 9000
flink,1593421135000
flink,1593421136000
flink,1593421137000
flink,1593421138000
flink,1593421142000
flink,1593421145000
flink,1593421146000
flink,1593421147000
flink,1593421148000
flink,1593421134000
flink,1593421135000
输出结果:
currentThreadId:66,key:flink,eventtime:[1593421135000|2020-06-29 16:58:55.000],currentMaxTimestamp:[1593421135000|2020-06-29 16:58:55.000],watermark:[1593421125000|2020-06-29 16:58:45.000]
currentThreadId:66,key:flink,eventtime:[1593421136000|2020-06-29 16:58:56.000],currentMaxTimestamp:[1593421136000|2020-06-29 16:58:56.000],watermark:[1593421126000|2020-06-29 16:58:46.000]
currentThreadId:66,key:flink,eventtime:[1593421137000|2020-06-29 16:58:57.000],currentMaxTimestamp:[1593421137000|2020-06-29 16:58:57.000],watermark:[1593421127000|2020-06-29 16:58:47.000]
currentThreadId:66,key:flink,eventtime:[1593421138000|2020-06-29 16:58:58.000],currentMaxTimestamp:[1593421138000|2020-06-29 16:58:58.000],watermark:[1593421128000|2020-06-29 16:58:48.000]
currentThreadId:66,key:flink,eventtime:[1593421142000|2020-06-29 16:59:02.000],currentMaxTimestamp:[1593421142000|2020-06-29 16:59:02.000],watermark:[1593421132000|2020-06-29 16:58:52.000]
currentThreadId:66,key:flink,eventtime:[1593421145000|2020-06-29 16:59:05.000],currentMaxTimestamp:[1593421145000|2020-06-29 16:59:05.000],watermark:[1593421135000|2020-06-29 16:58:55.000]
currentThreadId:66,key:flink,eventtime:[1593421146000|2020-06-29 16:59:06.000],currentMaxTimestamp:[1593421146000|2020-06-29 16:59:06.000],watermark:[1593421136000|2020-06-29 16:58:56.000]
currentThreadId:66,key:flink,eventtime:[1593421147000|2020-06-29 16:59:07.000],currentMaxTimestamp:[1593421147000|2020-06-29 16:59:07.000],watermark:[1593421137000|2020-06-29 16:58:57.000]
(key值:,(flink))
(flink),2, data_range[2020-06-29 16:58:55.000,2020-06-29 16:58:56.000], window [2020-06-29 16:58:54.000,2020-06-29 16:58:57.000)
currentThreadId:66,key:flink,eventtime:[1593421148000|2020-06-29 16:59:08.000],currentMaxTimestamp:[1593421148000|2020-06-29 16:59:08.000],watermark:[1593421138000|2020-06-29 16:58:58.000]
currentThreadId:66,key:flink,eventtime:[1593421134000|2020-06-29 16:58:54.000],currentMaxTimestamp:[1593421148000|2020-06-29 16:59:08.000],watermark:[1593421138000|2020-06-29 16:58:58.000]
(key值:,(flink))
(flink),3, data_range[2020-06-29 16:58:54.000,2020-06-29 16:58:56.000], window [2020-06-29 16:58:54.000,2020-06-29 16:58:57.000)
currentThreadId:66,key:flink,eventtime:[1593421135000|2020-06-29 16:58:55.000],currentMaxTimestamp:[1593421148000|2020-06-29 16:59:08.000],watermark:[1593421138000|2020-06-29 16:58:58.000]
(key值:,(flink))
(flink),4, data_range[2020-06-29 16:58:54.000,2020-06-29 16:58:56.000], window [2020-06-29 16:58:54.000,2020-06-29 16:58:57.000)
规整一下:
发现上面的三行数据都已经打印出来了,即包含在过去窗口中迟到的数据也被拿了回来
(key值:,(flink))
(flink),2, data_range[2020-06-29 16:58:55.000,2020-06-29 16:58:56.000], window [2020-06-29 16:58:54.000,2020-06-29 16:58:57.000)
(key值:,(flink))
(flink),3, data_range[2020-06-29 16:58:54.000,2020-06-29 16:58:56.000], window [2020-06-29 16:58:54.000,2020-06-29 16:58:57.000)
(key值:,(flink))
(flink),4, data_range[2020-06-29 16:58:54.000,2020-06-29 16:58:56.000], window [2020-06-29 16:58:54.000,2020-06-29 16:58:57.000)
3.3 sideOutputLateData 收集迟到的数据
通过 sideOutputLateData 可以把迟到的数据统一收集,统一存储,以方便后期排查相关问题
通过修改代码
看上图中的 ① ② ③ ④点:
① 表示一个侧输出流的标识
② 在流程序中将迟到的数据存储到 ① 中标识
③ 从流中把迟到的数据择出来
④ 打印 or 存储,一般是存储,看具体的业务场景
验证
依然使用上面的数据进行
$ nc -l 9000
flink,1593421135000
flink,1593421136000
flink,1593421137000
flink,1593421138000
flink,1593421142000
flink,1593421145000
flink,1593421146000
flink,1593421147000
flink,1593421148000
flink,1593421134000
flink,1593421135000
输出结果(只给出最后一部分数据):
currentThreadId:66,key:flink,eventtime:[1593421134000|2020-06-29 16:58:54.000],currentMaxTimestamp:[1593421148000|2020-06-29 16:59:08.000],watermark:[1593421138000|2020-06-29 16:58:58.000]
(key值:,(flink))
(flink),3, data_range[2020-06-29 16:58:54.000,2020-06-29 16:58:56.000], window [2020-06-29 16:58:54.000,2020-06-29 16:58:57.000)
currentThreadId:66,key:flink,eventtime:[1593421135000|2020-06-29 16:58:55.000],currentMaxTimestamp:[1593421148000|2020-06-29 16:59:08.000],watermark:[1593421138000|2020-06-29 16:58:58.000]
side_lated_data> (flink,1593421135000)
看到没有,活生生的 side_lated_data> (flink,1593421135000) 被打印了出来
当然在生产环境的特定场景下,这部分数据一定是要被存储到介质中的
四、多并行度下的应用
在前面代码中设置了并行度为 1
env.setParallelism(1)
那么,如果没有设置并行度的情况下,它会按照本机的 CPU 的数量进行并行度的设定
所以,在每个 CPU 处理的数据中,并不会集中去记录所有数据的 WaterMark,而是各自处理各自的
把程序中 env.setParallelism(1) 注释后,执行程序
依旧是上面涉及到的数据
依然使用上面的数据进行
$ nc -l 9000
flink,1593421135000
flink,1593421136000
flink,1593421137000
flink,1593421138000
flink,1593421142000
flink,1593421145000
flink,1593421146000
flink,1593421147000
flink,1593421148000
flink,1593421134000
flink,1593421135000
看结果,并没有触发像上面的 WaterMark
currentThreadId:69,key:flink,eventtime:[1593421136000|2020-06-29 16:58:56.000],currentMaxTimestamp:[1593421136000|2020-06-29 16:58:56.000],watermark:[1593421126000|2020-06-29 16:58:46.000]
currentThreadId:72,key:flink,eventtime:[1593421142000|2020-06-29 16:59:02.000],currentMaxTimestamp:[1593421142000|2020-06-29 16:59:02.000],watermark:[1593421132000|2020-06-29 16:58:52.000]
currentThreadId:67,key:flink,eventtime:[1593421147000|2020-06-29 16:59:07.000],currentMaxTimestamp:[1593421147000|2020-06-29 16:59:07.000],watermark:[1593421137000|2020-06-29 16:58:57.000]
currentThreadId:74,key:flink,eventtime:[1593421146000|2020-06-29 16:59:06.000],currentMaxTimestamp:[1593421146000|2020-06-29 16:59:06.000],watermark:[1593421136000|2020-06-29 16:58:56.000]
currentThreadId:73,key:flink,eventtime:[1593421145000|2020-06-29 16:59:05.000],currentMaxTimestamp:[1593421145000|2020-06-29 16:59:05.000],watermark:[1593421135000|2020-06-29 16:58:55.000]
currentThreadId:71,key:flink,eventtime:[1593421138000|2020-06-29 16:58:58.000],currentMaxTimestamp:[1593421138000|2020-06-29 16:58:58.000],watermark:[1593421128000|2020-06-29 16:58:48.000]
currentThreadId:70,key:flink,eventtime:[1593421137000|2020-06-29 16:58:57.000],currentMaxTimestamp:[1593421137000|2020-06-29 16:58:57.000],watermark:[1593421127000|2020-06-29 16:58:47.000]
currentThreadId:68,key:flink,eventtime:[1593421135000|2020-06-29 16:58:55.000],currentMaxTimestamp:[1593421135000|2020-06-29 16:58:55.000],watermark:[1593421125000|2020-06-29 16:58:45.000]
currentThreadId:68,key:flink,eventtime:[1593421148000|2020-06-29 16:59:08.000],currentMaxTimestamp:[1593421148000|2020-06-29 16:59:08.000],watermark:[1593421138000|2020-06-29 16:58:58.000]
整理一下:
可以发现
在各自的 currentThreadId 中,都没有触发到相应的 WaterMark,因此,上面的结果中是不会触发相应的机制的
多并行度的情况下,watermark对齐会取所有channel最小的watermark
作者:Johngo
配图:Pexels
欢迎大家留言,点个在看,也可以分享到朋友圈
互联网广告收入占到互联网收入的80%以上计算广告,一起研究流量变现,欢迎大家的加入




























暂无评论内容