
作者 | Kevin Vu
译者 | 唐欢、刘晓倩

NLP现在是热门领域,但想要掌握它却很难。在刚开始学习NLP时的主要问题是缺乏适当的指导和领域的过度宽广,很容易迷失在各种论文和代码中,试图接受所有信息。
需要意识到的是,NLP作为一个广阔的领域,学习者不可能学到所有东西,但可以尝试着循序渐进。如果能够坚持到最后,就会发现自己比其他人了解得更多。也就是说,学习NLP需要采取渐进式步骤。
首先第一步是在数据集上训练NLP模型,在刚起步时无需创建自己的数据集,因为这需要做大量的工作。
每天都会有大量的开源数据集被发布,集中在单词、文本、语音、句子、俚语以及其他能想到的任何内容。请记住,开源数据集并非没有问题,在获取任何旧数据集进行测试时,学习者必须先处理好偏差、数据不完整等一系列其他问题。
但是,网上有些地方在整理数据集方面做得很好,可以更容易找到想要查找的内容:
Papers With Code——近5000个机器学习数据集已分类且易于查找。Hugging Face——一个很棒的网站,可以找到专注于音频、文本、语音和其他专门针对NLP的数据集。除此之外,我们还推荐以下列表作为开始学习NLP的一些最佳开源数据集,或者也可以尝试各种模型并按照这些步骤进行操作。
1.Quora Question Incincerity数据集
这个数据集相当有趣。Quora 是国外的问答网站,Kaggle曾经举办过相关比赛,主办方会提供一个不真诚问题(这里对不真诚问题的定义是在发表声明而不是寻找有用答案的问题,包括但不仅限于非中性语气、贬低或煽动、不立足于现实、通过性来获得震撼等内容)的分类数据集,即Quora Question Incincerity数据集,要求参赛者根据问题的内容去预测这个问题是否真诚,简而言之就是解决文本分类问题。其目的是通过比赛开发出更具扩展性的方法来检测有毒和误导性内容。
除此之外,学习者还可以参考该数据集上NLP 文本分类系列的文章以更深入地学习NLP。
《Text Preprocessing Methods for Deep Learning》一文讨论了适用于深度学习模型和提高【Word2Vec】嵌入覆盖率的文本预处理方法。在第二篇文章《Conventional Methods for Text Classification》中,我们将带你了解一些应用于文本分类的常规模型,如TFIDF、CountVectorizer、Hashing等,并尝试访问它们的性能以创建基线。第三篇文章深入研究了Attention、CNN以及不用于文本分类的深度学习模型,重点介绍了解决文本分类问题的不同架构。最后一篇讲的是如何使用BERT和ULMFit进行迁移学习。2.斯坦福问答数据集(SQuAD)
斯坦福问答数据集(SQuAD)源自维基百科文章中的问答对集合,包含10万组带注释的三元组(passage,question,answer),通过给定一篇来自英文维基百科文章(passage)及准备相应的问题(question),需要算法给出截取自文章片段的答案(answer)。
简单来说,这就是一个阅读理解数据集,它会给我们一个问题和该问题答案所在的一个文本,然后接下来的任务是找出答案所在的文本范围。此任务通常被称为问答任务。
倘若你想对其进行更深入的研究,请参阅《Understanging BERT with Hugging Face》,该文章分享了如何使用此数据集和Hugging Face库的BERT模型来预测问题的答案,实现一个问答神经网络。
3.UCI ML药物审查数据集
UCI ML药物审查数据集提供了患者对特定药物的评论以及相关情况和一个反映患者总体满意度的10星患者评级系统,以方便用户根据药物审查预测病情。
该数据集大致有7列,其中数据字段的说明如下:
(1)uniqueID:患者唯一ID
(2)drugName:药品名
(3)condition:患者情况
(4)review:患者用药反馈
(5)rating:患者满意度评分(1-10分)
(6)date:反馈日期
(7)usefulCount:“赞同”数量(若其他人认为该条信息有帮助,会点击“useful”按钮,则该条信息获得1个“赞同”)
学习者可以根据以下思路来处理数据:
(1)分类:你能根据评论预测病人的病情吗?
(2)回归:你能根据评论预测药物的评级吗?
(3)情感分析:评论的哪些元素使其对其他人更有帮助?哪些患者往往有更多的负面评价?你能确定评论是正面的、中性的还是负面的?
(4)数据可视化:有哪些药物?这些患者有哪些情况?
有意思的是UCI ML药物审查数据集还可用于多类分类,如《Using Deep Learning for End Multiclass Text Classification》中所发表的,也可以尝试通过各种文本和数字特征来使用该数据集以解决多类文本分类问题。
如果有人想要亲身体验NLP,那么这个小型数据集就是一个不错的选择。
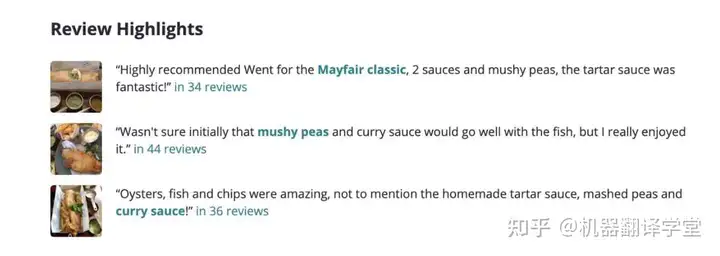
4.Yelp评论数据集
Yelp本是美国著名商户点评网站,囊括各地餐馆、购物中心、酒店、旅游等领域的商户,用户可以在Yelp网站中给商户打分,提交评论,交流购物体验等,类似于国内的大众点评。而Yelp 评论数据集是用户评论数据的子集,以 JSON 文件的形式提供。
在此数据集中可获得 Yelp 餐厅评论及营业时间和关闭时间等其他信息。学习者可以通过创建一个系统来对菜肴进行分类,或者利用命名实体识别 (NER) 的方法来找出评论中的菜肴,总之最好能够找出或创建一个系统来了解 Yelp 并获取餐厅的评论亮点。
并且通过Yelp评论数据集还能够很好地了解到 Yelp 业务和搜索功能,用户想怎么使用这个数据集都是没有限制的。
5.IMDB电影数据集
IMDB(Internet Movie Databas)是互联网电影资料库,里面包括了几乎所有的电影以及1982 年以后的电视剧集。它还有一个由影迷自己来打分的评分系统,平均每月有高达2000万电影爱好者进行访问,因此被认为是权威的影片评分平台。
而该数据集的创建者在IMDB上爬取了电影数据,包含来自IMDB的5万部电影的简介、平均评分、票数、类型和演员等信息。
除了方便训练NLP模型,这个数据集还可以通过多种方式使用。使用此数据集的最常见方法是构建推荐引擎、类型分类和查找相似电影。
6.20个新闻组
20个新闻组数据集是用于文本分类的国际标准数据集之一,其中包含有20个不同主题的新闻组集合(共收集了1.8万左右的新闻组文档),主要分为两个子集:一个用于训练(或开发),另一个用于测试(或性能评估)。主题多种多样,涵盖体育,无神论,政治等各个领域。
在获取该数据集的网站上,还详细地介绍了使用方法、如何将文本转换为矢量以及如何过滤文本以获得更真实的训练,你将使用朴素贝叶斯算法进行文本分类。
这是一个多类文本分类数据集,你也可以使用它来学习主题建模(从大量文本中提取隐藏主题的技术,含有关于文本信息的概率模型),如在Python中使用Gensim-LDA进行主题建模。
7.IWSLT(国际口语翻译研讨会)数据集
该机器翻译数据集符合翻译任务的事实标准,涉及了 TED 和 TEDx 演讲的德语、英语、意大利语、荷兰语和罗马尼亚语等不同主题的翻译。值得高兴的是,学习者可以在任何一对语言之间训练这些翻译,同时也能够通过 PyTorch 使用 torchtext.datasets 访问。
如果有人想深入了解如何使用此数据集来创建自己的transformer,请阅读这篇介绍了BERT Transformers及其工作原理的《BERT Transformers – How Do They Work?》文章,又或者参考《Understanding Transformers, the Programming Way》一文,有助于学习者理解怎样基于BERT从头创建翻译器。
最后,你可以通过以上数据集去寻找解决问题的方法,以及获得更多关于NLP的信息以解决各种任务。
原文链接:
https://www.kdnuggets.com/2021/11/top-open-source-datasets-nlp.html
阅读更多内容请查看“机器翻译学堂”
关于机器翻译学堂
机器翻译学堂是一个以机器翻译为核心的学习平台。面向所有的自然语言处理、机器学习等领域的学习者,分享论文解读、学习资料、优质博客、会议信息、行业动态、开源数据集等资源。
欢迎大家多多关注机器翻译学堂,一起学习,共同进步!
网站:https://school.niutrans.com
微信公众号:jiqifanyixuetang





















暂无评论内容