
Flink的安装和部署主要分为本地(单机)模式和集群模式,其中本地模式只需直接解压就可以使用,不用修改任何参数,一般在做一些简单测试的时候使用。本地模式在我们的课程里面不再赘述。集群模式包含:
Standalone。Flink on Yarn。Mesos。Docker。Kubernetes。AWS。Goole Compute Engine。目前在企业中使用最多的是Flink on Yarn模式。我们主讲Standalone和Flink on Yarn这两种模式。
1. 集群基本架构
Flink整个系统主要由两个组件组成,分别为JobManager和TaskManager,Flink架构也遵循Master-Slave架构设计原则,JobManager为Master节点,TaskManager为Worker(Slave)节点。所有组件之间的通信都是借助于Akka Framework,包括任务的状态以及Checkpoint触发等信息。
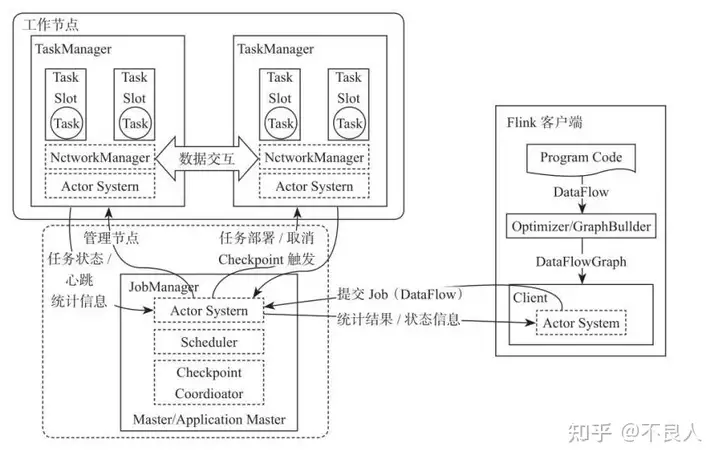
1) Client客户端
客户端负责将任务提交到集群,与JobManager构建Akka连接,然后将任务提交到JobManager,通过和JobManager之间进行交互获取任务执行状态。客户端提交任务可以采用CLI方式或者通过使用Flink WebUI提交,也可以在应用程序中指定JobManager的RPC网络端口构建ExecutionEnvironment提交Flink应用。
2) JobManager
JobManager负责整个Flink集群任务的调度以及资源的管理,从客户端中获取提交的应用,然后根据集群中TaskManager上TaskSlot的使用情况,为提交的应用分配相应的TaskSlots资源并命令TaskManger启动从客户端中获取的应用。JobManager相当于整个集群的Master节点,且整个集群中有且仅有一个活跃的JobManager,负责整个集群的任务管理和资源管理。JobManager和TaskManager之间通过Actor System进行通信,获取任务执行的情况并通过Actor System将应用的任务执行情况发送给客户端。同时在任务执行过程中,Flink JobManager会触发Checkpoints操作,每个TaskManager节点收到Checkpoint触发指令后,完成Checkpoint操作,所有的Checkpoint协调过程都是在Flink JobManager中完成。当任务完成后,Flink会将任务执行的信息反馈给客户端,并且释放掉TaskManager中的资源以供下一次提交任务使用。
3) TaskManager
TaskManager相当于整个集群的Slave节点,负责具体的任务执行和对应任务在每个节点上的资源申请与管理。客户端通过将编写好的Flink应用编译打包,提交到JobManager,然后JobManager会根据已经注册在JobManager中TaskManager的资源情况,将任务分配给有资源的TaskManager节点,然后启动并运行任务。TaskManager从JobManager接收需要部署的任务,然后使用Slot资源启动Task,建立数据接入的网络连接,接收数据并开始数据处理。同时TaskManager之间的数据交互都是通过数据流的方式进行的。
可以看出,Flink的任务运行其实是采用多线程的方式,这和MapReduce多JVM进程的方式有很大的区别Fink能够极大提高CPU使用效率,在多个任务和Task之间通过TaskSlot方式共享系统资源,每个TaskManager中通过管理多个TaskSlot资源池进行对资源进行有效管理。
2. Standalone集群安装和部署
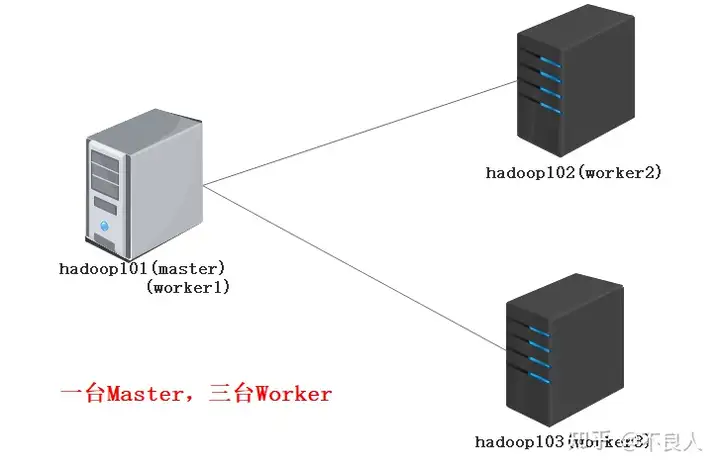
Standalone是Flink的独立部署模式,它不依赖其他平台。在使用这种模式搭建Flink集群之前,需要先规划集群机器信息。在这里为了搭建一个标准的Flink集群,需要准备3台Linux机器,如图下所示。
1) 解压Flink的压缩包

2) 修改配置文件
a. 进入到conf目录下,编辑flink-conf.yaml配置文件:
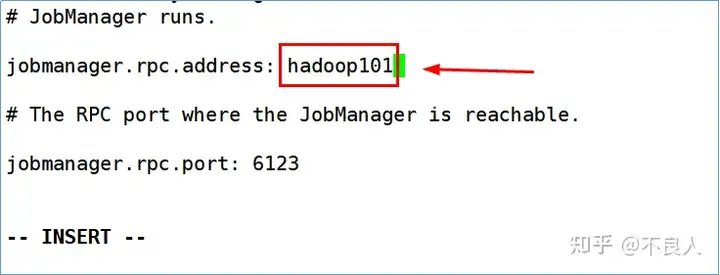
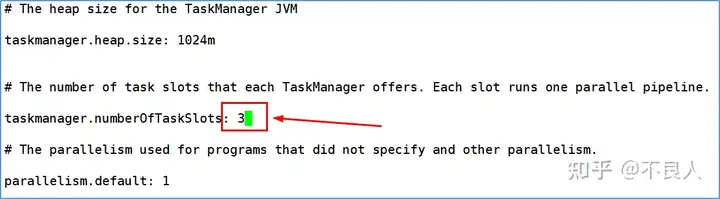
其中:taskmanager.numberOfTaskSlot参数默认值为1,修改成3。表示数每一个TaskManager上有3个Slot。
b. 编辑conf/slaves配置文件
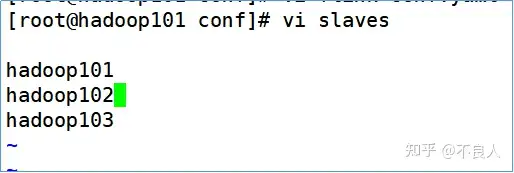
c. 分发给另外两台服务器
d. 启动Flink集群服务

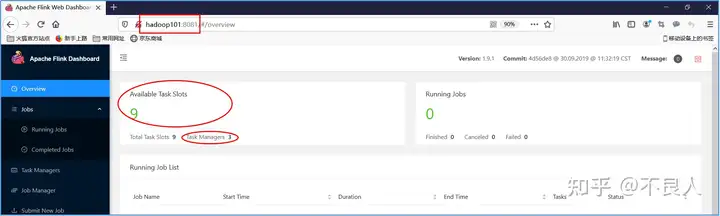
e. 访问WebUI
f. 通过命令提交job到集群
把上一章节中第一个Flink流处理案例代码打包,并上传
其中-d选项表示提交job之后,客户端结束并退出。之后输入测试数据
查看job执行结果
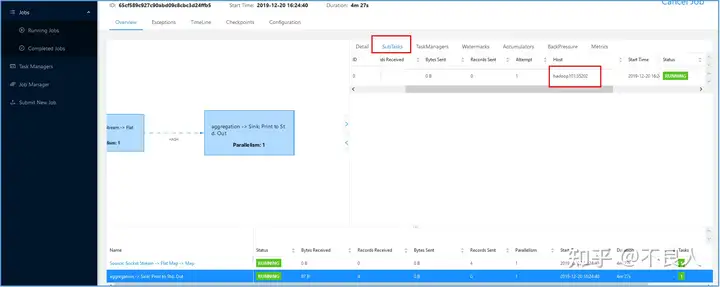
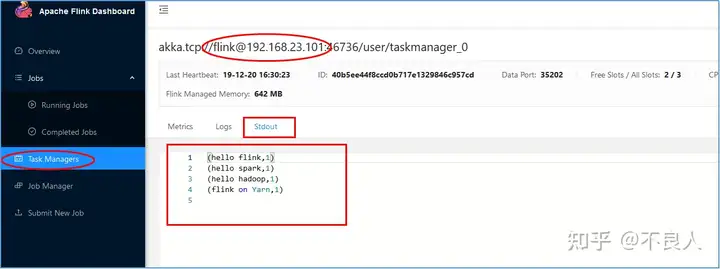
然后去hadoop101的TaskManager上查看最后的结果:
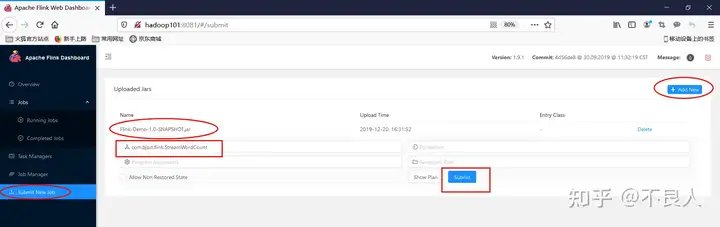
g. 通过WebUI 提交job到集群
h.配置文件参数说明
下面针对flink-conf.yaml文件中的几个重要参数进行分析:
jobmanager.heap.size:JobManager节点可用的内存大小。taskmanager.heap.size:TaskManager节点可用的内存大小。taskmanager.numberOfTaskSlots:每台机器可用的Slot数量。parallelism.default:默认情况下Flink任务的并行度。上面参数中所说的Slot和parallelism的区别:
Slot是静态的概念,是指TaskManager具有的并发执行能力。parallelism是动态的概念,是指程序运行时实际使用的并发能力。设置合适的parallelism能提高运算效率。

















暂无评论内容