
投稿:极链科技
作者:点心(AI实验室)
不知不觉,你是否发现身边的小伙伴们都在疯狂的玩抖音,刷微博,你的购物APP也变得越来越聪明,很了解你想要的东西,就连点个外卖,美团和饿了么都知道你想要吃什么呢?是什么黑科技让这些APP变得如此神通,能深深的吸引着你的目光和味蕾呢?其实,之所以你觉得它越来越聪明越来越懂你,当然少不了你跟它之间的亲密“沟通”,看似不经意的一次点击,一次停留,它都默默的记了下来,等待你的再次临幸。这位神秘的幕后主使就是我们今天要讲的——个性化推荐算法。目前它已经深入到互联网的各类产品中,也经历了数次更新迭代,变得越来越贴心了。接下来,我将通过一个近期我们参加比赛具体讲解一些其中的算法原理。
这次比赛是由今日头条主办的短视频内容理解与推荐竞赛,我们的成绩在大规模亿级的赛道中拿了第四名,千万级数据规模的赛道中第五名。这也是我们极链AI实验室首次尝试推荐算法。
首先,来讲讲什么是推荐算法。推荐算法大致可以分为三类:基于内容的推荐算法,协同过滤推荐算法和混合推荐算法。基于内容的推荐算法,原理是将用户喜欢和自己关注过的Item在内容上类似的Item推荐给用户,比如你看了复仇者联盟1,基于内容的推荐算法发现复仇者联盟2、3、4,这些与你以前观看的item在内容上有很大关联性。协同过滤算法,包括基于用户的协同过滤和基于item的协同过滤,其中基于用户的协同过滤是通过用户之间的相似性,挖掘与用户具有相似兴趣的用户喜欢过的item,比如你的朋友喜欢复仇者联盟,那么就会推荐给你。基于item的协同过滤是找到跟用户喜好最相似的商品,然后推给他。混合推荐算法,则会融合以上方法,以加权或者串联、并联等方式进行建模。常用的包括传统机器学习算法如因子分解机(FM,FFM),LR,GBDT,RF和近几年流行起来的DNN和FM结合的算法。
这三种类型的推荐算法各有千秋,内容推荐算法的优点在于可以避免Item的冷启动问题(冷启动:如果一个Item从没有被关注过,其他推荐算法则很少会去推荐,但是基于内容的推荐算法可以分析Item之间的关系,实现推荐),但弊端在于推荐的Item可能会重复,典型的就是新闻推荐,如果你看了一则关于某某明星出轨的新闻,很可能推荐的新闻和你浏览过的,内容一致;协同过滤算法可以随着用户对商品的交互记录增加更准确的捕捉用户行为习惯,进而使得模型能够不花费额外的人工的方式来提高精度(但在初期会面临冷启动问题的困扰)。
无论哪种推荐算法,都离不开特征工程、模型学习这两个重要的步骤。接下来,通过比赛这个实例,来讲解每个步骤具体是如何实现的。这次比赛的任务是通过一个视频及用户交互行为数据集对用户兴趣进行建模,然后预测该用户在另一视频数据集上的点击行为。该任务属于机器学习中两个基本任务之一分类,而且是二分类即给给定的数据打标签(0,1),0代表unlike,unfinish,1代表like或者finish.
一.特征工程
众所周知,短视频App中的视频一般都有一个醒目的标题,有一段内容丰富的连续画面,和一段有趣的声音组成,通过nlp,cv,audio等深度学习模型提取这些信息特征就组成了视频item的特征;对于用户来说,用户的身份(年龄,性别,地域)等组成用户特征,用户点击视频的过程,停留的时间,点赞等行为则构成了基本的交互信息。比赛提供的交互信息字段,我们将它划分为三个部分包括用户信息(user_id,user_city),视频信息(item_id,item_city,author, songs, duration time)和交互信息(did, channel)。除此之外,视频特征,音频特征,人脸特征等都属于视频信息。
接下来,信息有了,怎么去挖掘这些信息中隐藏的秘密呢?这就是特征工程的意义所在,尽可能多的挖掘用户和item之间的相关信息,然后将这些信息送入后面的模型进行学习。
比赛初期,主办方提供了一个简单的特征构建和模型训练的框架,上文提过的FM算法,公式如下:
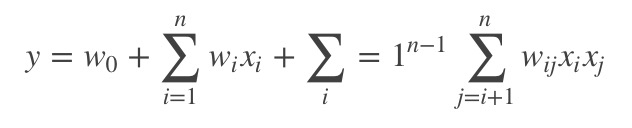
该算法利用交互信息,构建矩阵,通过因子分解,来挖掘信息的交互特征。其中x代表特征属性,y是预测结果,n就是特征的交互阶数,阶数越高,求解越难。因为特征x分为category特征(离散)和numeric特征(稠密)两种,category特征需要进行one-hot编码,一旦进行交互,特征的维度将会非常高,使得计算机的算力不够。实际应用中,一般只取二阶特。那么,还有其他方法去挖掘更多更深的交互信息吗?别急,下面我会介绍比赛中我们尝试的重要的特征工程方法。
推荐算法的数据记录的是用户的历史行为信息,而数据的先后顺序反映了时间信息,那么利用所有的历史数据去计算未来的行为的特征生成我们暂时称之为全局特征,只利用一部分历史数据来计算特征的生成方式我们称之为局部特征。
基于全局的特征
基于全局的特征我们主要从svd分解、统计特性、和时间相关特征,三个方面去考虑进行特征提取。
svd分解特征,提到svd,想到最多的自然是特征降维,主成分分析,那么利用svd将高维的交互特征进行降维,就可以输入模型进行训练了,比如用户和item,构造一个user-item矩阵,矩阵的每个元素代表了该用户和该item间是否有交互,有的话就是1,没有的话就是0,这个矩阵是一个极其稀疏的高维矩阵(比赛中赛道二7w*400w),通过svd分解,提取前n个主成分组成稠密特征,输入模型中训练,可以大大减少计算量。对于比赛提供的特征,我们进行了user-item,user-author,user-title的svd分解。 统计特征,之所以称统计特征,是因为所有的计算涉及的都是常用的统计方法,包括求均值,方差,以及用户特征和item特征之间的条件概率P(did|uid), P(channel|uid), P(did|item_id), P(channel|item_id), P(item_author| uid), P(item_city|uid), P(uid_city|item_id) 等。 时间相关特征,这些特征主要挖掘用户某个时间段内观看视频的频率,从而得到用户在时间维度上的爱好。具体的,就是定义一个时间长度,比如1000,5000,10000等等,然后统计该段时间内用户或者item出现的频率。 基于局部的特征局部特征的构造,是根据时间顺序,划分出一部分作为历史数据,另一部分作为训练数据(即现在和未来),通过历史数据构造特征组合(只针对category),并统计训练数据需要的信息,如图1所示,按照时间的远近,靠近测试数据的30%数据作为训练数据,前面70%数据作为历史数据,可以去除最后5%的数据之后多次划分,训练多模型来提升效果。根据马尔可夫理论,当前的状态一般只和前面一个状态相关,这也是为何如此划分数据集的依据。提取的特征描述如表格1所示。

图1.局部特征构造示意图
Tabel 1:local feature deion

上述所有特征中,mean和regression只针对目标finish和like进行计算,这些特征只记录了用户的历史行为,count_from_past, count, count_from_future, 这些特征从时间角度上统计了用户从历史-现在-未来的行为。matrix_factorization 特征是通过FM算法计算的只利用user和item信息的一个特征,这样即利用了fm的信息,计算量又小。
二.模型训练
特征构造完成后,后续的任务就可以交给强大的机器学习算法来进行训练。常用的算法有基于boost算法的决策树和dnn算法(比赛中我们仅使用了前面的算法,是因为dnn的算法在增加全局特征后有提升的,但是和其他模型的结果进行融合后并没有提升,而且也没有boost的效果好)。如图2所示,针对不同特征使用不同的训练器训练流程,feature0代表局部特征,feature1代表全局特征,最后将两个框架的结果进行融合。每个阶段的比赛成绩如表2所示,只列出来赛道二中的部分成绩,“——”代表没有进行该项实验,由于全局特征在like任务的表现一直不理想,所以基于该特征的xdeepfm并未进行实验。中间关于参数选择和特征选择的成绩未列出。Final是最终提交的public成绩。

图2 模型训练示意图
Tabel2:比赛数据(Track2)

















暂无评论内容