
概述
相较于在模型构架或硬件优化上所花的精力,机器学习从业者反而对训练数据更加重视。因此,程序员基于不同的抽象技术,即高级设计的模板为他们的应用构建机器学习管道。在这篇文章中,我们介绍了三种强大的抽象技术,通过这些技术,从业者可以以编程的方式构建和管理他们的训练数据。
我们进行了一项实验来测试针对基础训练数据操作的有效性,分别对训练集的一部分数据使用了本文的框架、Snorkel(一种快速创建、建模和管理训练数据的系统,通过标记函数以编程的方式标记数据)和在 SuperGLUE (一个用于「通用语言理解技术」相关六项任务的新评价指标)上取得最佳结果的标准 NLP 模型(即 BERT)。与自然语言预训练模型(即 BERT)的最新进展相比,我们总体上取得了新的最高分数,并且在大多数组合型任务上,我们在各个方面都实现了现有的最好成绩。
除了 SuperGLUE 之外,我们还重点介绍了 Snorkel 在实际应用中的更新,其中包括更多应用——从 Google 的 Snorkel Drybell 的工业规模到 MRI 分类和自动全基因组关联研究(GWAS)策划的科研工作(这些应用均被收录于 Nature Comms:https://www.nature.com/ncomms/)!
与此同时,我们还在 Snorkel repo 中发布代码:
https://github.com/HazyResearch/snorkel
三种关键的抽象方式
一般来讲,在我们的 SuperGLUE 结果中,我们发现,将时间花在以编程方式构建和操纵训练数据而非模型训练上实为一种强大且有效的策略,通过此策略,我们可以得到机器学习的管道机制的高性能。在过去的一篇文章(阅读地址:https://dawn.cs.stanford.edu/2019/03/22/glue/)中,由于我们在 GLUE Benchmark(SuperGLUE 的前身)上取得了当前最先进的结果,我们讨论了加入更多来源的有监督信号的价值,例如:多任务学习和转移学习。在这篇文章中,我们将重点放在构建和修改训练数据集的三个关键抽象方法上:
1.使用标记函数(LF)标记数据
2.使用转换函数(TF)转换数据
3.使用切片函数(SF)切片数据(技术报告+博客文章即将推出!)
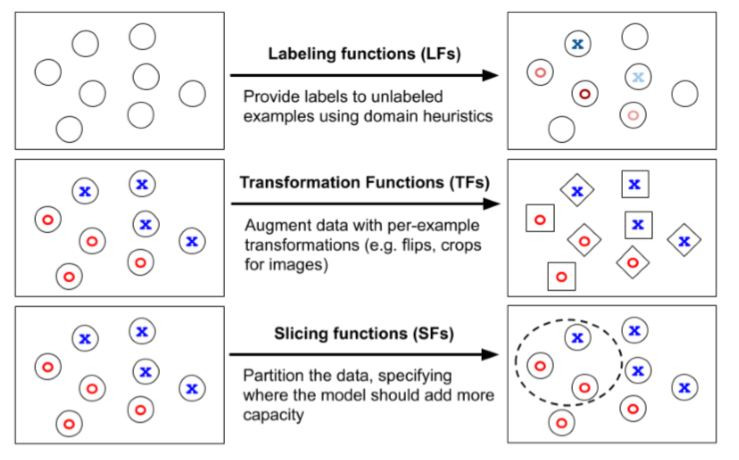
运行例子
对于本文的其余部分,我们用 SuperGLUE 的语境用词(WiC)任务作为示例:目标词在句中的用法是否一致?

1、 使用标注函数的弱标注
在许多应用场景中都有大量的未标记数据,这些数据可能来自于自动驾驶车队或大型非结构化数据库。但出于时间和成本的考虑,标注这些原始数据是很难的,因此,现代架构在很大程度上无法利用这些潜在的丰富数据集。通过使用 Snorkel,我们多年来一直致力于研究使用标注函数(LF)来启发性地标注训练样例。Snorkel 中的标注函数(LF)为领域专家或机器学习从业者提供了用于对来自现有数据集、模型和人工标注的有监督源进行去噪和结合的直观界面。

对于 WiC 任务(判断目标词在两个句子中「意思」是否一致),我们可以认为根据它们是否共享包括目标词的三元组来弱标记例子。
2、 用转换函数做数据增强
通常,人们会根据简单的变换,如随机旋转或拉伸图像来做数据增强,但它们可以涉及到更多样化的操作范围。我们将转换函数(TF)视为一种强大的抽象方式,启发式地从现有的例子生成新的更改过的例子。例如,对于医学成像任务,我们可能会编写 TF 来执行特定于我们的成像模态的变换。例如,重新取样分割肿瘤块或重新取样背景组织。我们在 TANDA 这项工作(Learning to compose domain-specific transformations for data augmentation,http://papers.nips.cc/paper/6916-learning-to-compose-domain-specific-transformations-for-data-augmentation)中探索了这种抽象方式,TANDA 旨在学习跨域特定任务的转换组合。Google 的 AutoAugment 便以此工作为基础,自动学习数据增强策略。

3、 用切片函数做数据切片(新方法!)
在许多数据集中,特别是在实际应用中有一些使我们的模型表现不够好的数据子集,还有一些相比于其他数据子集,其表现更让我们关注的数据子集。例如,较低频的医保人口统计数据(如某些患癌的年轻患者),我们的模型在这个数据上就可能表现不好,或者在自动驾驶设定下,我们可能更关注一些安全攸关但罕见的场景,如检测自行车骑行情况。我们将这些数据称为子集切片。从业者经常面临的技术挑战是提高这些切片的性能,同时保持整体性能。
切片函数(SF)为用户提供了一个接口,用于粗略地识别那些模型应为其提供额外表示能力的数据子集。为了解决特定切片的表示,从业者可能会训练多个模型,其中每个模型都针对特定的子集,然后将这些模型与专家混合(MoE)方法相结合。
然而,随着机器学习模型的规模不断增大,MoE 通常是不切实际的。另一种策略是通过硬参数共享以多任务学习(MTL)的方式训练单个模型。虽然此方法计算效率更高,但它需要在许多特定切片任务中用表示偏差来提高性能,而这种方式往往并不可靠。作为快速概述(技术报告+博客文章即将推出!),我们以多任务学习的方式对切片进行建模,其中使用基于切片的「专家头部」来学习特定切片的表示。然后,通过为专家头部引入注意力机制,以确定何时以及如何在每个示例的基础上组合由这些切片头部学习到的表示。
在本方法中,我们考虑以下属性:
我们的方法与模型无关——专家头部在任何骨干架构(例如 BERT,ResNET)之上学习。因此,使用切片功能提高整体性能的从业者们可以专注于数据而不是模型架构。
通过多任务方式学习,我们可以有效地进行表示学习,而无需制作模型的许多副本(如 MoE 则需要太多内存)!
通过结合注意力机制,我们避免了专家头部的手动调整——这大大节省了开发者的成本。

从 WiC 错误分析中,我们可能会发现我们的模型在目标词是名词而非动词的例子中表现得更差。使用切片函数 SF,我们告诉模型注意这些切片之间的差异,并在对它认为是名词的目标词进行预测时使用略微不同的表示。
标注函数 LFs、转换函数 TFs 和切片函数 SFs 的重要属性
直观的界面:这些抽象方式为现有的从业者工作流程提供了直观的界面。它们允许直接对调试/报错分析中的意见进行编码,以改进模型。
将抽象方法视作弱监督进行编程:在实践中,许多这样的技术可被视为一种弱监督形式,因为用户指定这些技术就是有噪音的、启发式的且不精确的一些方式。处理此问题是我们使用 Snorkel 解决的核心技术挑战之一。
将监督视作代码:这些输入的种类是根据监督模型的方法(即它们指定训练集)。具体地说,它们也是代码,因此其具有代码复用性和可修改性等诸多优点。
SuperGLUE 结果
使用这些编程抽象方法,我们在 SuperGLUE Benchmark 及其 4 个组合任务上获得了新的最好成绩。SuperGLUE 类似于 GLUE,但包含「更困难的任务…… 选择最大化难度和多样性,以及…… 选择显示基于 BERT 的强基线与人类表现之间的巨大余量差距。」在重现 BERT ++基线后,我们这些模型(基线模型,默认学习率等)进行微调后发现,在使用上述编程抽象方法的少数应用中,我们看到结果在 SuperGLUE 基准上提升了 4 个点(即与人类表现的差距缩小了 21%)。
Snorkel 的实际应用
这些 Snorkel 编程抽象方法也被用于推动具有高影响力的实际应用的进步。
今年 3 月,我们和 Google 发布了一篇论文(https://arxiv.org/pdf/1812.00417.pdf)和博客文章(https://ai.googleblog.com/2019/03/harnessing-organizational-knowledge-for.html),介绍了在工业界部署 Snorkel 的经验。凭借整个组织的不同知识来源——启发式,标注器,知识图谱,遗产系统(一种数据源系统)等,他们看到效果的显着提高,在 F1 值上提高了 17.5 个点之多。

Snorkel 管道机制,被部署在具有多达 4000 个未标记的 MRI 序列数据集的 BAV 分类任务中。图片来自 Fries et. al . 2018。
在最近被 Nature Communications 收录的工作(相关阅读:https://www.biorxiv.org/content/10.1101/339630v4.full)中,Snorkel 被部署在与斯坦福大学儿科心脏病学持续合作的项目中,其中训练数据的标注是开发自动化方法的重大实际障碍。我们关注的是二尖瓣主动脉瓣(BAV),这是最常见的先天性心脏畸形(一般人群的发病率为 0.5-2%),具有影响下游健康的风险。在研究中,我们选择不依靠来自心脏病专家的昂贵的 MRI 标注,而是直接与领域专家合作开发标注函数 LF,以此为下游深度学习模型生成大规模的训练集。在使用我们端到端的方法确诊的患者中,一项独立评估确定发生重大心脏不良事件的风险增加了 1.8 倍。
在另一篇即将发表的 Nature Communications 论文(https://ai.stanford.edu/~kuleshov/papers/gwaskb-manuscript.pdf)中,我们展示了 Snorkel 是如何应用于自动化全基因关联研究(GWAS)的。在之前发表的数百项报告了重要的基因型与表现型数据对的研究集合中,我们仅使用标记函数自动标记了大型训练集。由此产生的分类器应用于 598 项研究的集合,恢复了 3,000 多个先前记录的开放存取关系(预计召回率为 60-80%)以及现有人类策划存储库中不存在的 2,000 多个协会(预计精确度为 82-89%)。生成的数据库可通过 http://gwaskb.stanford.edu/上的用户界面进行搜索。
后记
Snorkel 项目正在积极进行中!我们有许多令人兴奋的持续合作——从斯坦福大学医学院的后续工作到国际调查记者协会(ICIJ)的部署,以帮助记者组织、索引和理解数百万个非结构化文件。
本次发布的代码包括了重要的基础结构改进以及如何将 LF,TF 和 SF 应用于 SuperGLUE 和其他任务的教程。我们很高兴如果您已经在自己的应用程序中应用了 Snorkel。有关 Snorkel 开发和应用程序的更新,您可以随时访问 Snorkel 登录页面或开源库:
登录页面:http://snorkel.stanford.edu/
开源库:https://github.com/HazyResearch/snorkel
via:http://ai.stanford.edu/blog/training-data-abstractions/ 雷锋网雷锋网雷锋网





















暂无评论内容