
常用推荐算法分类
1、基于人口统计学的推荐与用户画像
2、基于内容的推荐与特征工程
3、基于协同过滤的推荐
一、基于人口统计学的推荐与用户画像
基于人口统计学的推荐机制是简单的根据系统用户的基本信息发现用户的相关程度,然后根据相似用户喜欢的其他物品推荐给当前用户,对于没有明确含义的用户信息(比如登录时间、地区等上下文信息可以通过聚类等手段,给用户打上分类标签),用户信息标签化的过程一般又称为用户画像。
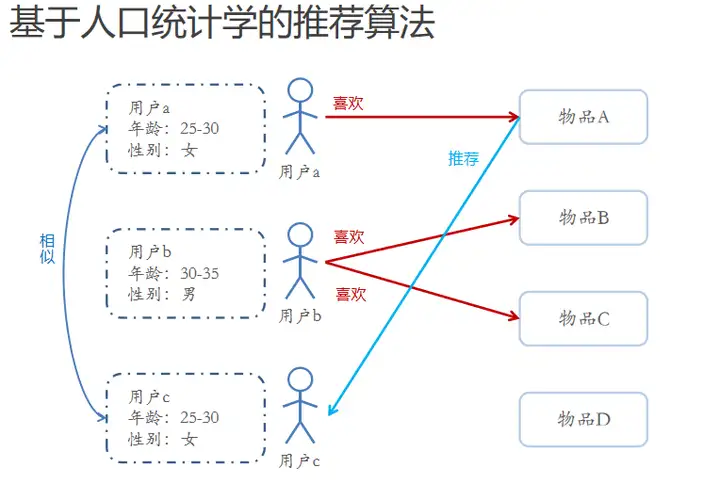
用户画像(User Profile)就是企业通过收集与分析消费者社会属性、生活习惯、消费行为等主要信息的数据之后,完美地抽象出一个用户的商业全貌,为企业提供了足够的信息基础,能够帮助企业快速找到精准用户群体以及用户需求等更为广泛的反馈信息
二、基于内容的推荐算法
根据推荐物品或内容的元数据,发现物品的相关性,再基于用户过去的喜好记录,为用户推荐相似的物品。
通过抽取物品内在或者外在的特征值,实现相似度计算。(比如一个电影,有导演、演员、用户标签UGC、用户评论、时长、风格等等,都可以算是特征)
将用户(user)个人信息的特征(基于喜好记录或是预设兴趣标签),和物品(item)的特征相匹配,就能得到用户对物品感兴趣的程度(在一些电影、音乐、图书的社交网站有很成功的应用,有些网站还请专业的人员对物品进行基因编码/打标签(PGC))
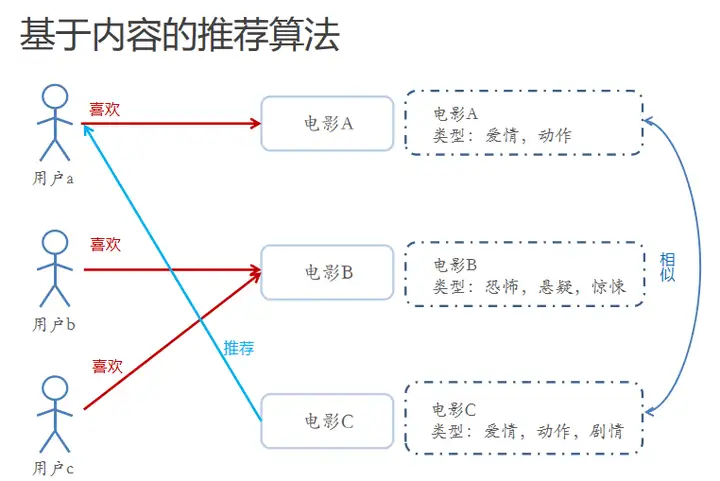
基于内容的推荐算法
对于物品的特征提取-打标签
专家标签(PGC)、用户自定义标签(UGC)、降维分析数据、提取隐语义标签(LFM)
对于文本信息的特征提取-关键词
分词、语义处理贺情感分析(NLP)、潜在语义分析(LSA)
特征工程
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用
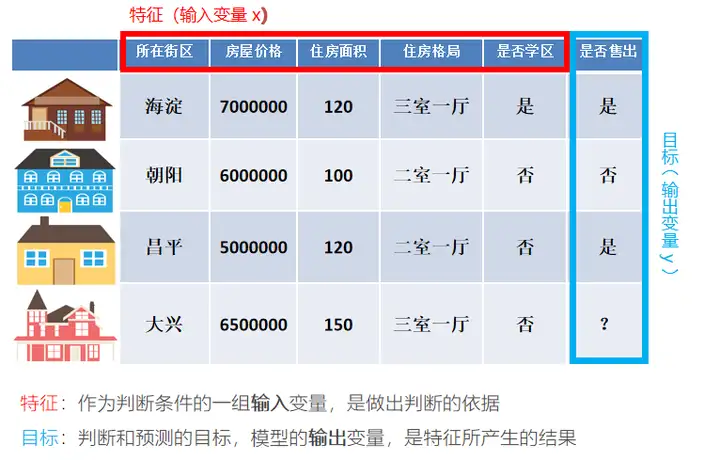
数值型
两个相等的特征,输入到相同的模型中后由于本身的幅值不同导致产生的效果不同是不合理的
a、归一化 new=old/(max-min)
b、离散化
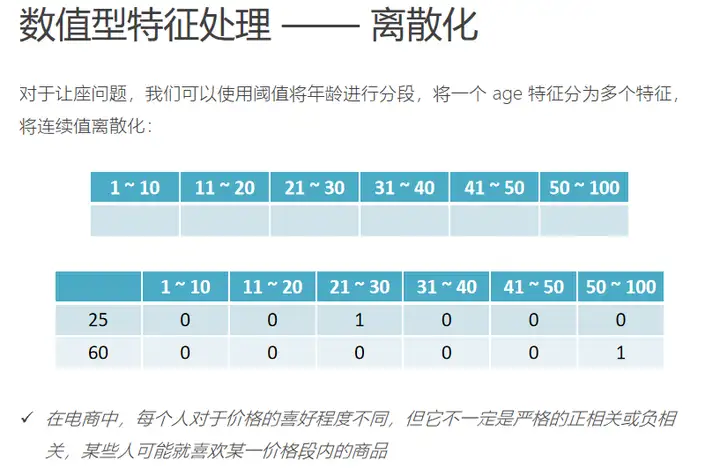

类别型
类别型数据本身没有大小关系,需要将他们编码为数字,但他们不能有预先设定的大小关系,因此既要做到公平,又要区分它们,需要将类别型数据平行展开,特征空间会膨胀
时间型
时间型特征比如网页浏览时长,上次购买和现在购买时间间隔可以做连续值,一天中的哪个时间段、一周的星期几可以做离散值
统计型
加减平均:商品价格高于平均价格多少,用户在某个品类下消费超过多少
分位线:商品属于商品价格的分位线处
次序性:商品处于热门商品第几位
比例类:电商中商品的好/中/差评比例
最后呈现这样的效果
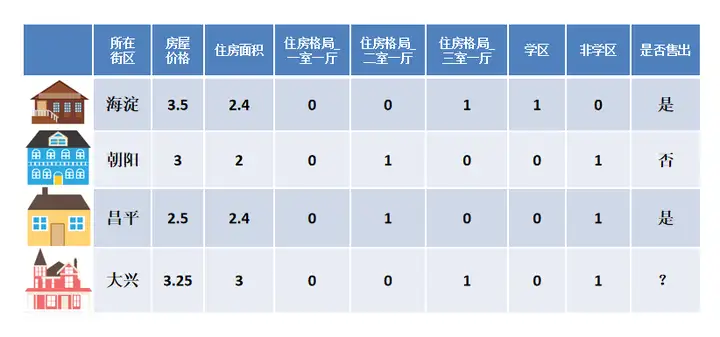
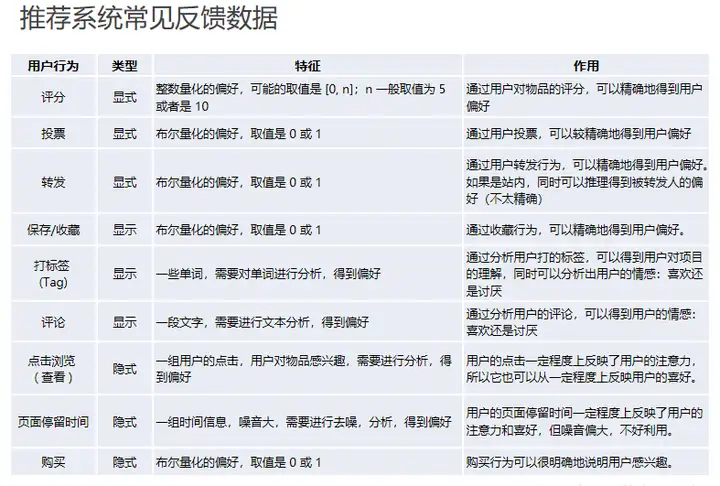

问题:热门标签、热门商品会有比较大的权重,这样热门物品同事对应的热门标签,那他就会霸榜,整个推荐系统的个性化和新颖度就会降低。使用TF-IDF(词频-逆文档频率)来解决



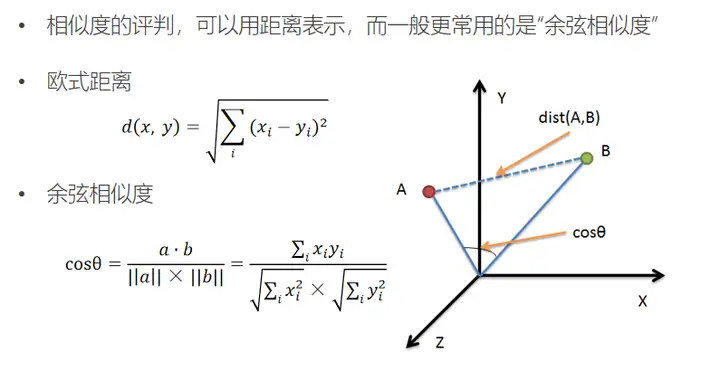
三、基于协同过滤的推荐算法
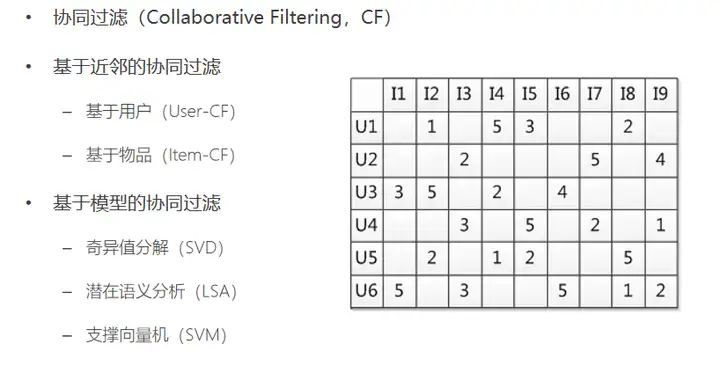
基于近邻的推荐是在预测时直接使用已有的用户偏好数据,通过近邻数据来预测对新物品的偏好(类似分类)
基于模型的方法,是要使用这些偏好的数据来训练模型,使用模型来做预测(类似回归)

User-CF

Item-CF



基于模型的协同过滤思想
基于模型的协同过滤,是基于样本的用户偏好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测新物品的得分计算推荐,其中使用隐语义模型来发现物品潜在特征
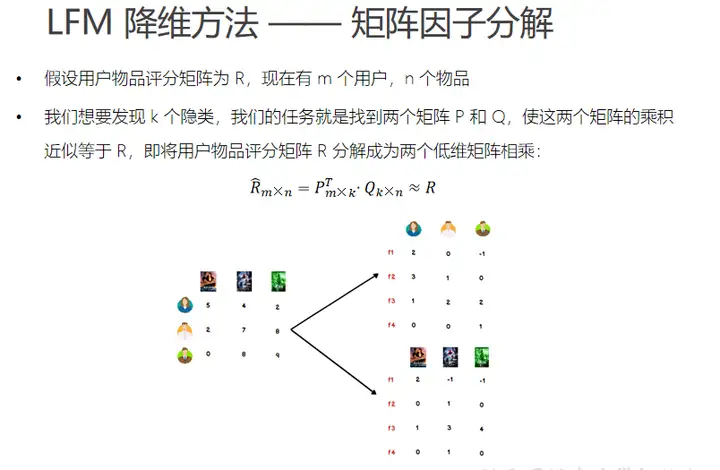
隐语义模型(LFM)
LFM是在用户和物品的共现矩阵上,引入隐向量,用隐向量表示用户和物品,进而增强了模型表征稀疏数据的能力!
LFM算法本质上还是属于矩阵分解算法:
其将 m × n 的共现矩阵(m个用户;n个物品) 分解为:
m × k 的用户向量矩阵
k × n 的物品向量矩阵
上述中:k 表示隐向量的长度;
k 的大小决定了隐向量的表征能力:
k 越小,隐向量越短,其包含的信息越少,模型的泛化能力越强;
k 越大, 隐向量越长,其包含的信息越多,模型的泛化能力越弱;
k 的取值,还是要考量计算复杂度(长度约长,复杂度越大)以及实际场景中模型的效果

LFM公式推导


求算是函数最小值,一般采用随机梯度下降算法或者交替最小二乘法(ALS)实现

经过很多轮次的训练,用户和物品的vector会不断的更新,当效果不错时便可以停止!

















暂无评论内容