
Content-based simple anime recommender from Myanimelist Dataset on Kaggle(基于内容的动漫推荐)
目前基础推荐系统主要分为两种,基于内容的推荐和协同过滤。基于内容的推荐系统更加专注于内容的属性,不计算项目-用户之间的交互,向用户推荐项目。在这种情况下,我们假设如果用户喜欢电影,新闻或产品等某项商品,那么他/她在未来也会喜欢某项商品,将重点放在项目之间的相似性。在基于娱乐/媒体的产品(如动漫或电影)中,这一假设一定程度上可以成立。 如果我喜欢看《指环王》,《加勒比海盗》,《霍比特人》等电影,那么我可能会喜欢其他幻想/冒险片的电影,例如《金罗盘》或《星尘》。
作为一个95后,火影,龙珠和死神几乎成为了我们童年的共同记忆,即使现在是b站的忠诚用户,给同学种草安利新剧成为了生活中很重要的乐趣,但是不可否认的是目前由于动漫质量的参差不齐,很难找到好的动漫建议,因为很少有网站可以提供动漫建议和评级。Myanimelist 凭借其庞大的动漫数据库和充满活力的社区而位居榜首,该社区以准确的评分为动漫进行评分和审查。最近Myanimelist在Kaggle上启动了一个数据集,最后我用这些数据制作了一个简单的推荐系统。在这篇文章中,我将介绍根据动漫类型,等级,评论动漫的成员数量以及分享一些结果等属性创建推荐器的过程。
Datasets
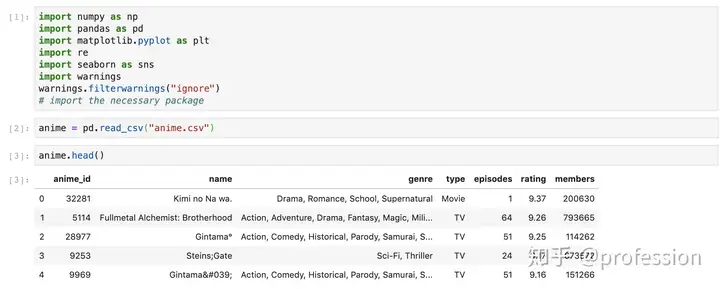
该数据集包含有关来自12,294动漫的73,516个用户的用户偏好数据的信息。每个用户都可以将动漫添加到他们的完整列表中并给它一个评分,并且该数据集是这些评分的汇总。有两个数据集,anime.csv和动漫相关数据,以及rating.csv包含用户首选项相关数据。我仅使用了基于内容的功能,因此仅使用了Anime.csv数据集。
特征变量:
anime_id:http://myanimelist.net动漫的唯一IDname:动漫的全名
genre:此动漫的类型
type:电影,电视,OVA等
episodes:此节目中有多少集(如果是电影则为1)
rating:该动画的平均评分(满分10分)
members:此动漫的“组”中社区成员的数量
K Nearest Neighbor
在这种情况下,我们可以简单地找到邻居,并使用它们来推荐相似的项目。粗略地说,为了建议相似的动画,我首先找到k相似的动画并将其推荐给用户。在这种情况下,我已经检索了与给定查询相关的前5个最相似的动漫。例如,如果我向“推荐人”系统查询“火影忍者”,它将返回与火影忍者相似的前5名动漫。我已将类型,类型,剧集,评分和成员用作特征,但没有选择使用名称特征。我本可以使用tf-idf或其他策略(如单词袋)来处理文本功能,但实际上使用名称会使建议“太容易了”。如果我们显示《火影忍者》第二季和所有《火影忍者》电影,很容易显示出类似《火影忍者》的动漫,我想看看不使用文字功能的简单方法还能走多远。
数据集加载
数据预处理过程
如前所述,动漫名称功能已被删除。类型和剧集功能缺少许多值。我现在将逐个功能介绍它们的处理方式。
集数(Episodes)
即使评分相似,许多动漫的情节数也未知。除了诸如《火影忍者》,《疾风传》等许多超人气动漫外,收集数据时正在进行《进击的巨人》第二季,因此其集数被视为“未知”。对于我最喜欢的一些动漫,我手动填写了剧集编号。对于其他动漫,我不得不做出一些有根据的猜测。我所做的更改:
归入“Unknown”类别的动漫通常具有1集。因此,我用1填充了未知值。分组的动漫是“ OVA”代表“原始视频动画”。这些通常是一集/两集长的动漫(尽管受欢迎的动漫通常有2/3集),但是我决定再次用1来填充未知数集。根据数据集概述,归类于“电影”下的动漫被视为“ 1”集。对于所有其他动画,其情节数未知,我用中位数2填充了na值。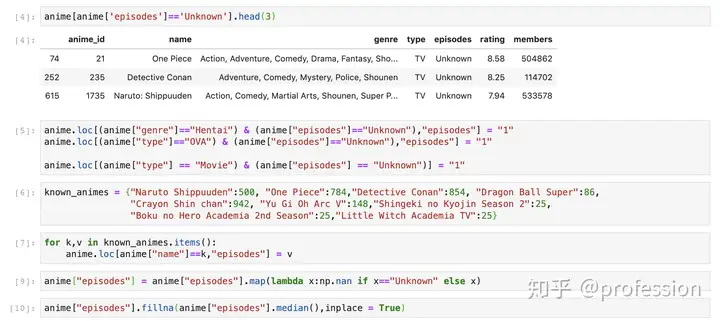
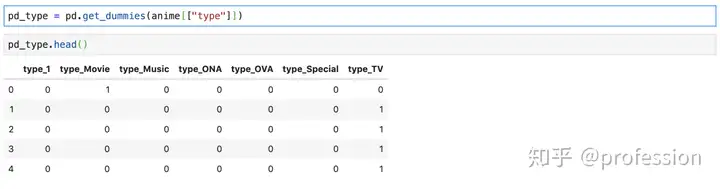
类型(Type)
类型因为并没有大小的区别,选择用get_dummies的方式变成0,1变量
评分,会员和类型(Rating, Members and Genre)
对于成员功能,我只是将字符串转换为float。
情节编号,成员和等级与分类变量不同,并且值也有很大差异。
在数据集中,评分范围为0–10,而对于诸如One Piece或Naruto等长期流行的动漫,情节编号甚至可以长达800多个情节。 这可能会使KNN中的距离度量产生偏差,因为包含较大数字的要素将被加权,而其他要素将被打折。并最终使用了scikit-learn的MinMaxScaler。
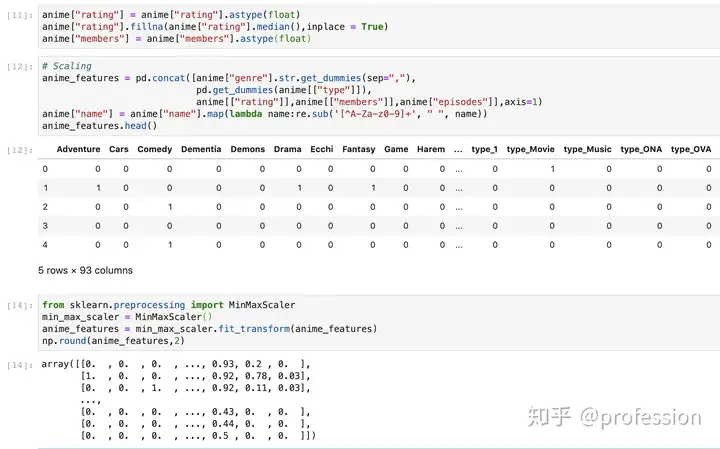
拟合KNN模型(Fit KNN Model)
将scikit学习的KNN模型拟合到数据,并针对每个距离计算最近的邻居。 在这种情况下,我使用了无监督的NearestNeighbors方法来实现邻居搜索。 请注意,我使用k = 6作为参数是因为KNN返回的第一个邻居始终是自身,因为实例到自身的距离为0,我们不能使用它。
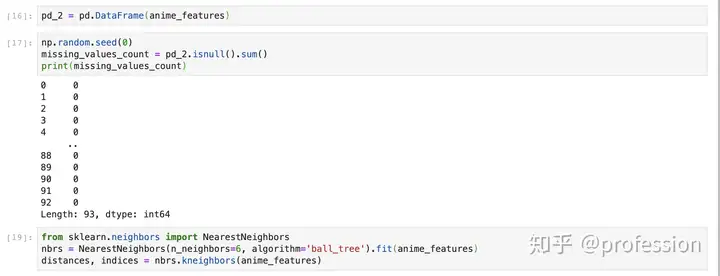
帮助函数(Helper functions)
写一些辅助函数来查询和显示结果
get_index_from_name(name): 如果指定了全名,则返回动画的索引。
get_index_from_partial_name(name) : 返回名称中带有该子字符串的所有动漫的索引。 许多动漫名称没有得到正确的记录,在许多情况下,它们的名称是日语而不是英语,并且拼写经常不同。 因此我创建了这个函数。
print_similar_animes(query,id): 查询后打印前5个相似的动漫。 我们可以按名称和ID进行查询。
结果(Query Examples)
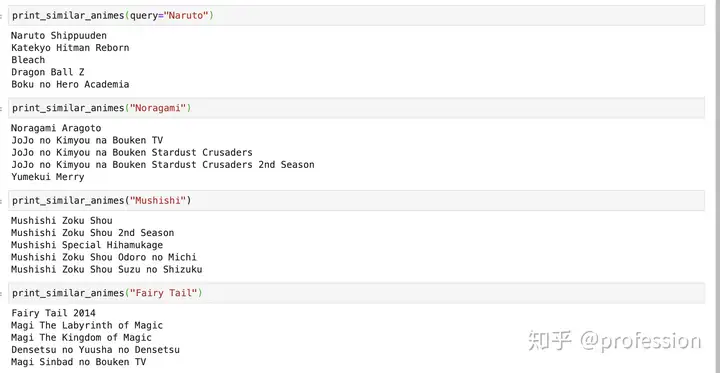
推荐第二季和相关动画:
正如我们将在下面看到的那样,推荐器的效果令人惊讶。 如果我们考虑动漫的第二季,并且相关的动漫电影和其他产品必须与自身非常相似,则推荐者会很好地预测它们。
《火影忍者》的第二季是《火影忍者疾风传》,而《野良神》的第二季是《野良神》 Aragoto,这是这两种动漫的首个推荐。 Mushishi和Gintama也是长期经营的动漫,并且有很多推荐的产品。 少年动漫迷会知道,对火影忍者的其他推荐也非常相似,例如Katekyo Hitman Reborn,DBZ,Bleach和Boku No Hero Academia都是非常受欢迎的动作/少年动漫。
动漫电影推荐
我想检查关于动漫和动漫电影的建议是否不同。 《火影忍者》是一部动画,也是与它相关的其他动画电影。 如果我获得了电影的电影推荐和动漫的电影推荐,则可以认为推荐者正在适当考虑预期内容的类型。 令人惊讶的是,尽管采用了一种简单的方法,但推荐人的确能很好地理解电影与动漫之间的区别。首先,检查其中是否包含“火影忍者”的内容,以查看电影的名称。
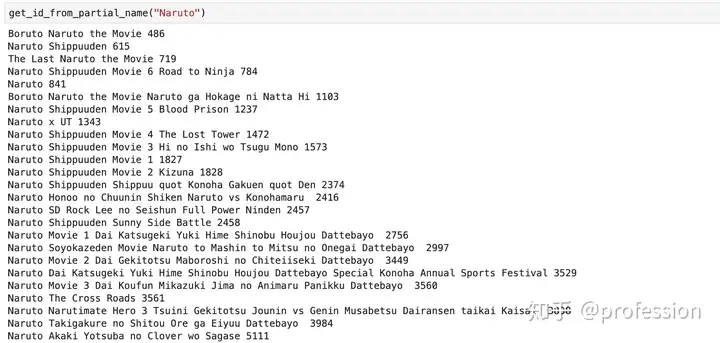
然后我们检查是可以运行的,由于距离指标为minkowsky,因此“类型”功能可帮助我们区分电影和动漫类型。
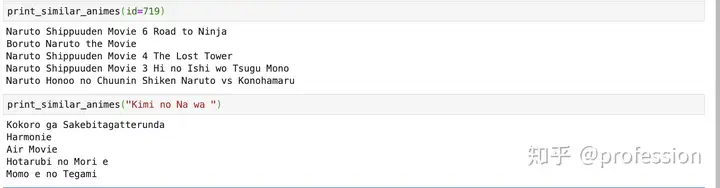
Source: Tahsin Mayeesha,2018 A Content-Based Live Music Recommender. Available from: https://medium.com/learning-machine-learning/recommending-animes-using-nearest-neighbors-61320a1a5934 [24 June 2020]
非商业应用,仅用于学术分享,侵权删


















暂无评论内容