
一、flink特点
事件驱动:有状态应用,从事件中提取数据,触发计算,状态更新等 被动触发
流与批的世界观:
批处理:有界、持久、大量 离线统计流处理:无界、实时 实时统计spark :一切都是批次 ,Flink:一切都是流
无界数据流:有开始,没有结束
有界流:有开始、有结束
分层API:

二、flink应用
事件驱动型应用:无须查数据库,更快
什么是状态:保存历史计算结果或数据
数据分析应用:流比一体
数据管道应用:ETL :提取-转换-加载
spark 和Flink比较
计算模型不同,flink 窗口更灵活,精准一次保证、时间语义
三、Flink运行架构
1.运行模式
local-cluster模式Standalone模式Yarn模式
Per-Job-Cluster模式Session-Cluster模式Application Mode模式2.三大组件
client:提交任务和解析(per-job模式)
JobManager:主进程
Dispatcher转发器分发器:处理Client提交过来的JobGraph,负责启动新的jobMasterResourceManager:资源管理JobMaster:协调TaskManager:工作进程 slot 控制task数量
slot : 内存共享,均分内存,共用CPU3.Slot 与并行度
并行度优先级:代码的算子指定>代码的env指定 > 提交参数 > 配置文件默认
Slot可以由配置文件中TaskManager.numberOfTaskSlots参数设置每个Task的Slot,然后跟据Task的数量算出集群的Slot数量
同一个算子的任务不能在同一个Slot里面不同的算子的子任务可以共享一个slot如果slot的数量<任务的并行度, standalone模式会卡着直到有足够的slot,yarn模式动态申请资源整个流程的并行度=某个最大并行度算子的并行度4.Task与SubTask
Task: 一个算子的一个子任务或者多个算子的子任务满足某种关系串在一起的子任务SubTask:一个算子的一个并行实例5.算子之间传输数据的形式
one-to-one: 元素的个数及顺序相同Redistributing: keyBy基于hashCode重分区,broadcast和Rebalance6.算子操作链的优化:
串联:相同并行度的one to one 优点:对外一个task内运行,减少网络IO打断链条:有些算子任务多,有些算子任务少,操作链会把他们串在一起,为了让忙的任务更好的执行,需把他们拆开算子.startNewChain(); 以当前算子为起点,开启新的链条(与前面切开) 算子.disableChaining(); 当前算子不加入链条(与前后都切开)
env.disableOperatorChaining() 全局禁用操作链7.富函数:
1)生命周期管理方法: open()、close()注意:如果是读文件,每个 并行实例 都会 多执行一次 close()2)运行时上下文: RuntimeContext => 获取 环境信息、状态(累加器、计数器………很多很多)分组:逻辑上的划分,按照指定的key区分不同的组; 分区:一个并行实例 = 一个分区 ,是物理上的资源
Connect: 1)connect 只能连接两条流 2)两条流的数据类型可以不一样 3)如果 connect多条流: 先两条connect,调用算子处理,之后再跟 另外的流 connect
Union: 1) 流的数据类型必须要一致 2)可以同时 union 多条流
聚合类的算子: 都在keyby之后使用, 因为都是 KeyedStream的算子,组内聚合
min、max:除了比较字段之外,其他的字段取第一条的值 minBy、maxBy: 1)除了比较字段之外,其他的字段取最新的值 2)如果比较的字段出现了相同值 第二个参数为 true,其他字段 取 第一条的值 第二个参数为 false,其他字段 取 最新的值
Reduce: 输入和输出的类型必须一致,不够灵活 分组内的第一条数据,不会调用 reduce 方法 value1是之前的计算结果,value2是当前来的数据
rescale 相比 rebalance 效率更高,少很多网络IO
8.图
StreamGraph:流图JobGraph:作业图ExecutionGraph:执行图Physical Graph:物理执行图四、flink的高级功能
1.窗口机制
滑动窗口:
Flink的窗口划分,并不是以 第一条 为 窗口的起始点
滑动步长的一个现象:每经过一次 步长的 滑动,就会有某一个窗口输出
窗口的增量聚合函数:
1)来一条数据,聚合一条
2)在窗口结束的时候,输出一次
全窗口函数: 每来一条数据,就先存起来,到了需要输出的时候,一起计算
key 分组的key context 上下文 elements 数据,窗口内(都是同一分组)的所有数据 param out 采集器aggregate(AggregateFunction,ProcessWindowFunction)
第一个函数:进行增量聚合,并将 聚合结果 传递给 第二个函数 第二个函数:全窗口函数,接收第一个函数的结果,进行进一步的处理好处: 兼顾了 增量的特点,和全窗口函数的 灵活性
以 基于 事件时间的 滚动窗口(10s) 为例:
1、窗口是怎么划分的?为什么是左闭右开?
1)start = timestamp – (timestamp – offset + windowSize) % windowSize;
事件时间 – (事件时间 – 0 + 窗口大小)%窗口大小
时间戳按照窗口长度 取整数倍(以1970年1月1日0点为起点 => 伦敦时间)
2)end = start + size 开始时间 + 窗口长度
3)左闭右开: 属于本窗口的最大时间戳 = end -1ms , 所以时间为 end这条数据,不属于本窗口,所以是开区间
2、窗口什么时候触发、输出?
window.maxTimestamp() <= ctx.getCurrentWatermark()
当前的 watermark >= 窗口的最大时间戳
3、窗口的生命周期:什么创建的?
Collections.singletonList(new TimeWindow(start, start + size)); 本窗口(都是同一分组)的第一条数据来的时候,使用 new的方式创建的,添加到一个单例的集合
4、窗口的生命周期:什么时候关闭的?
cleanupTime = window.maxTimestamp() + allowedLateness; allowedLateness 默认是 0ms 当时间(watermark)达到 窗口的最大时间戳 + 允许迟到的时间,就会关闭窗口
2.watermark机制
1、watermark概念
1) 衡量 事件时间 的进展 2) 单调不减的(保持不变,或 增加) 3) 是一个特殊时间戳,生成之后插入到流里,随着流的流动 传递 4) 解决 乱序 的问题 5) 认为,在它之前的数据都处理过了(如果还有,说明该数据迟到了) 6) 触发 窗口等 的 计算、关闭2、watermark 写法

1)升序写法
WatermarkStrategy.<T>forMonotonousTimestamps().withTimestampAssigner()
2)乱序写法
WatermarkStrategy.<T>forBoundedOutOfOrderness(Duration).withTimestampAssigner()
3、watermark 分类
1)间歇性的生成: 来一条数据,更新一次 => onEvent() 2)周期性的生成(默认): 间隔固定周期,更新一次,默认200ms => onPeriodicEmit()4、watermark 生成逻辑
1)乱序: watermark = maxTimestamp – outOfOrdernessMillis – 1 当前为止最大的事件时间 – 乱序程度 – 1ms 2)升序: watermark = maxTimestamp – 0ms – 1ms 当前为止最大的事件时间(当前数据) – 1ms5、watermark 在多并行度下的传递
1) 一对多: 广播 2) 多对一: 取最小,参考木桶原理 3) 多对多: 以上两种的结合,挨个去分析即可6、Flink处理乱序和迟到
迟到数据: 当前数据的时间戳 小于 当前的 watermark
窗口的迟到数据:end之后,才来的 属于本窗口的数据 窗口允许迟到:
1) 当 watermark >= end – 1 时, 触发窗口计算 2) 当 end – 1ms < watermark < end + 允许迟到时间 -1 ms 时,每来一条迟到数据,都会触发一次计算 3) 当 watermark >= end + 允许迟到时间 -1 ms, 就会 关闭窗口,再有迟到的数据来,也不处理了侧输出流
用来处理迟到数据:
对于乱序迟到数据的处理方式,首先用watermark来一定程度上处理乱序数据,然后用允许迟到数据处理小于watermark的数据,最后对于超过允许迟到时间的数据,采用侧输出流进行分支处理逻辑处理,也可与主流进行合并。
7、其他注意的写法
1)如果上游是Kafka,直接在 官方提供的SourceFunction实现类上,指定watermark2)多分区的数据源,设置一个 idle超时,防止 watermark不更新的问题8、问题:读文件
1)为什么被Long的最大值触发?
为了保证所有的数据都被计算到,退出之前,会把watermark设为最大值
2)为什么其他早一点的窗口也是被Long的最大值触发?
因为默认watermark是周期性的200ms更新,还来不及更新
9、怎么确定乱序程度:
1)估算,经验值 2)抽样
如果Flink版本 <= 1.10,采用如下写法: assignTimestampsAndWatermarks(new AscendingTimestampExtractor) assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor(乱序程度))
补充扩展: 为什么要关注Kafka的全局有序性?
如果 是用 canal或maxwell等工具,同步 关系型数据库的 数据到kafka,那么就要关注 操作顺序: 表 test,某行数据做了如下操作: ① 插入 ② 更新1 ③更新2 ④删除 => 操作顺序不能乱,否则会出现问题
Kafka是全局无序、单分区有序,怎么办?
思路: 把 同一张表的 数据 ,都 发送到 同一个分区
实现: Kafka的生产者 API,可以指定 key ,key取hash值,对kafka分区数 取模 我们可以指定 key为 库名+表名
如果 一个 Topic只有一张表的数据,怎么办?
那么这个Topic可以设为 单分区
Flink可以依赖 watermark机制,一定程度 处理 乱序问题
超时设置的意义和场景:
实际工作中,可能有某一个kafka的分区一直没有数据, 结合watermark的传递,以最小的为准,就会导致 watermark不更新 进一步导致,一些窗口、计算、定时器不会被触发。
设置 idle超时,如果超时了,这个分区不会再被用来 更新watermark
intervaljoin源码:
1) 底层使用了connect进行关联,关联条件就是 各自的 keyby
2) 判断数据是否迟到,如果迟到就不处理 => 事件时间 < 当前watermark 就是迟到 (以小的为准)
3) 左流和右流,都初始化了一个 MapState,代码底层是buffer,数据来的时候,会添加进去,key是 ts,value是 List(数据)
4) 遍历 对方 的 buffer, 判断时间是否落在区间内,如果落在区间内,匹配上,发送到用户定义的 processElement方法
左流.intervalJoin(右流)
左ts + 下界 <= 右 ts <= 左ts + 上界
右ts – 上界 <= 左 ts <= 右ts – 下界
5) 注册一个定时器,去清理 MapState 左流的清理时间 = 左ts + 上界 右流的清理时间 = 右ts – 下界
定时器的原理:
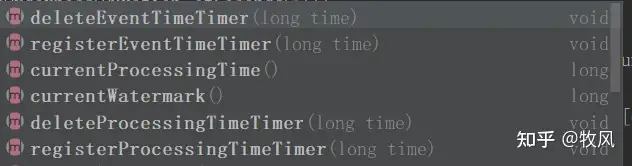
1、注册 eventTimeTimersQueue.add(new TimerHeapInternalTimer<>(time, (K) keyContext.getCurrentKey(), namespace)); => 每次调用注册的方法,都会 new一个定时器对象,放进一个 队列里(会去重 => 分组内去重,不同组之间没关系) => 如果重复注册定时器,最终还是只有一个起作用
2、触发 timer.getTimestamp() <= time time = watermark.getTimestamp() => watermark >= 注册的时间 ,触发定时器 (注意 watermark生成的时候,减去了 1ms)
3.状态编程
流计算分类
无状态:观察每个独立事件
有状态:基于多个事件输出结果
状态的分类
Managed State:自动存储、自动恢复、自动伸缩 (重要)
Raw State: 用户自己管理
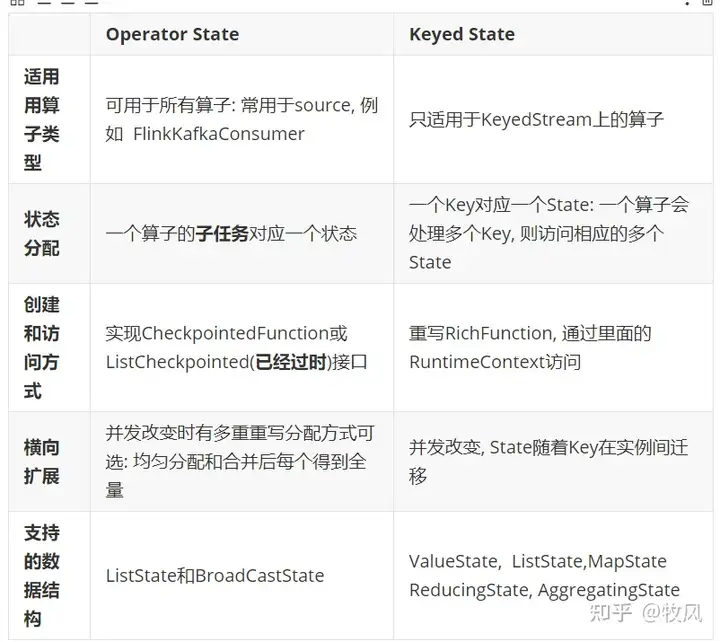
Managed State分类
Operator State(算子状态): 常用于source,一个算子的子任务对应一个状态
Keyed State(键控状态):只能用于Keyed算子
算子状态 Operator State
CheckpointedFunction中的两个方法:
initializeState: 初始化时调用这个方法,向本地状态中填充数据,每个子任务调用一次
snapshotState:checkpoint时调用这个方法,实现具体的逻辑用来持久化数据
分类:
列表状态(List state): 并行度不同时分别把各自分区的数据往下游均分
联合列表状态(Union list state):并行度不同时会先把上游的数据都联合起来,然后用广播的方式往下游发送,每个下游分区都获得全部的数据
广播状态(Broadcast state):广播状态可以以一种控制流的方式对主流的数据进行控制,分情况处理
步骤:
创建有两条流 –》创建一个map描述器 –》用一个流广播这个描述器返回一个广播流 –》用主流关联广播流 –》调用 process方法 重写两个方法 –》在广播流处理逻辑里通过上下文获取广播状态,往广播状态里面存数据 –》在主流处理逻辑里面通过上下文获取广播状态,根据广播状态写对应算法广播状态
键控状态
分组隔离:一个组对应着一个状态
分类:
ValueState: 单个值
ListState:list列表
MapState:键值对
ReducingState: 单个的值
AggregatingState:单个的值
状态后端
两件事:
本地状态的管理 将检查点状态写入远程存储
分类:
MemoryStateBackend(默认):本地状态存储在TaskManager的内存中, checkpoint 存储在JobManager的内存中.
FsStateBackend:本地状态在TaskManager内存,Checkpoint时,先把状态的存储地址发送到JM内存中,然后再存储在HDFS文件系统中
RocksDBStateBackend:\1. 本地状态存储在TaskManager的RocksDB数据库中(实际是内存+磁盘) 2. Checkpoint在外部HDFS文件系统中.
4.容错机制
一致性级别
在流处理中,一致性可以分为3个级别:
Ø at-most-once(最多一次): 会丢数据 不会重复
Ø at-least-once(至少一次): 不会丢数据 会重复
Ø exactly-once(严格一次): 不丢不重
端到端的一致性
端到端的一致性:数据源(例如 Kafka),流处理器和输出端都需要保证一致性。
端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性,整个端到端的一致性级别取决于所有组件中一致性最弱的组件。
具体划分如下:
source端
需要外部源可重设数据的读取位置.目前我们使用的Kafka Source具有这种特性: 读取数据的时候可以指定手动提交**offset**
flink内部
依赖checkpoint机制
sink端
需要保证从故障恢复时,数据不会重复写入外部系统. 有2种实现形式:
a) 幂等(Idempotent)写入
所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了。
b) 事务性(Transactional)写入
需要构建事务来写入外部系统,构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中。对于事务性写入,具体又有两种实现方式:预写日志(WAL)和两阶段提交(2PC)
预写日志(Write-Ahead-Log)
1)把结果数据先当成状态保存,然后收到checkpoint完成的通知时,一次性写入sink系统。
2)由于数据提前在状态后端(state backend)中做了缓存,所以无论什么 sink 系统,都能用这种方式一批搞定
3)DataStream API提供了一个模板类:GenericWriteAheadSink来实现这种事务性sink
两阶段提交two-parse commit
1)对于每个checkpoint,sink任务会启动一个事务,并将接下来所有接收的数据添加到事务里。
2)将这些数据写入外部sink系统,但是不提交它们,只是“预提交”。
3)当它收到checkpoint完成的通知时,才正式提交事务,实现结果的真正写入。
4)这种方式真正实现了exactly-once。
5)这种方式真正实现了exactly-once,它需要一个提供事务支持的外部sink系统,Flink提供了TwoPhaseCommitSinkFunction接口。
sparkstreaming结合kafka怎么实现幂等性?
手动提交:kafka的offset在下游sparkstreaming接收到数据后就自动提交了,而在数据处理过程中可能存在数据的丢失问题,所以把offset的提交方式改为手动提交,等数据处理完成后再提交,这样的话保证了数据不会丢失,但不能解决数据重复的问题
幂等性:下游用具有幂等性的数据库来存数据,保证数据不会重复,如redis,hbase
sink到文件系统:什么实现两阶段提交?
1.写到一个临时文件 ==》预提交
2.写临时文件成功的话,就把临时文件改名为正式文件名 ==》正式提交
3.如果预提交中出现失败的话,就删除该临时文件 ==》回滚
幂等会出现暂时不一致:
是指一批数据回滚后,在发生故障前这批数据已经有写入sink的了,回滚会重新重播这部分数据,但是它是幂等操作,所以还是保证了Exactly-once。
checkpoint原理
原理:
1.JobManager中的Checkpoint Coordinator会周期性的生成barrier。
2.barrier生成之后会从source端注入到数据流里面,随着整个数据流流动。3.barrier每经过一个算子,都会触发当前算子状态的checkpoint备份,备份的方式由StateBacked的类型决定(MemoryStateBacked,FsStateBacked,RocksDBStateBacked)
4.在barrier未到达sink之前,sink会把读到的数据写入缓存中预提交。
5.当barrier流向sink后,触发sink的checkpoint完成后,说明本次所有节点的checkpoint都已完成,sink此时会接收到一个特殊的信号,用来把数据进行二次提交
6.恢复状态时,使用最近的一次完成的checkpoint,完整指的是:从source到sink每个算子都备份了状态
分析:性能:处理数据和备份异步,相对性能比较高
2pc:两阶段提交依赖于checkpoint,本阶段ck完成才进行二次提交
理解Barrier
1.barrier是由jobmanager里面的CheckpointCoordinator(协调器)产生的
2.barrier不会跨越流中的数据
3.barrier相当于把数据流分割开来,每个barrier之间的数据都是一批次快照
检查点制作过程:
第一步: Checkpoint Coordinator(JM里面) 向所有 source 节点 trigger Checkpoint. 然后Source Task会在数据流中安插CheckPoint barrier
第二步: source 节点向下游广播 barrier,这个 barrier 就是实现 Chandy-Lamport 分布式快照算法的核心,下游的 task 只有收到所有 input 的 barrier 才会执行相应的 Checkpoint
第三步: 当 task 完成 state 备份后,会将备份数据的地址(state handle)通知给 Checkpoint coordinator(协调器)。
第四步: 下游的 sink 节点收集齐上游所有 input 的 barrier 之后,会执行本地快照,这里特地展示了 RocksDB incremental Checkpoint 的流程,首先 RocksDB 会全量刷数据到磁盘上(红色大三角表示),然后 Flink 框架会从中选择没有上传的文件(增量备份)进行持久化备份(紫色小三角)。
第五步: 同样的,sink 节点在完成自己的 Checkpoint 之后,会将 state handle 返回通知 Coordinator。
第六步: 最后,当 Checkpoint coordinator 收集齐所有 task 的 state handle,就认为这一次的 Checkpoint 全局完成了,向持久化存储中再备份一个 Checkpoint meta 文件。
barrier对齐:
barrier对齐:如果barrier在等待的过程中,则barrier后面的数据也跟着等待不进行处理,严格按照barrier在流中的位置进行处理
反压机制:
反压:等待过程中,数据或者barrier都会待在算子的输入缓冲区里面,如果数据迟迟未被处理,则会导致缓存区数据塞满,则上游输出缓存区也会存满数据,上游输入缓存区也会积累数据,基于credit机制(信用机制)
SavePoint原理
Flink 还提供了可以自定义的镜像保存功能,就是保存点(savepoints)原则上,创建保存点使用的算法与检查点完全相同,因此保存点可以认为就是具有一些额外元数据的检查点Flink不会自动创建保存点,因此用户(或外部调度程序)必须明确地触发创建操作保存点是一个强大的功能。除了故障恢复外,保存点可以用于:有计划的手动备份,更新应用程序,版本迁移,暂停和重启应用,等等操作:flink run -s ck地址 -c jar包注意:在算子的并行度或类型有很大变动时,savepoint可能不起作用
Kafka+Flink+Kafka 实现端到端严格一次




















暂无评论内容