量化有哪些可以挖掘因子、研发因子、学习新因子的路径?
这个老问题下有很多回答。我提供一个新的思路:让ChatGPT把我们心中的想法写成新的因子(而不是帮我们想出新的因子)。并且话痨ChatGPT还喜欢写代码注释与算法解释,因此这也能用来学习新因子。
下文里,我们不仅让ChatGPT写“价量背离”因子,我们还让它按要求帮我们改一个新的因子出来。(它自己把协方差计算换成了Spearman Rank 以及 Ordinary Least Squares)。要是实在懒得哄ChatGPT,那么只在提问时加上“Lets think step by step”这一句话也行。
哄ChatGPT帮我读交易程序的代码 – 金融强化学习 哄ChatGPT帮我写量化因子 – 价量背离因子 (←本文)哄ChatGPT帮我改金融交易策略 – 训练交易模型(←还在写)
本文分2.5个部分:
哄ChatGPT写“多进程的多行tqdm”:开启多进程,每一个进程显示一个进度条tqdm,多条进度条同时更新。网络上的代码,大多是用一条进度条显示多进程的进程池的进程执行进度,而非同时显示多条进度条。哄ChatGPT的咒语——提示词 Lets think step by step哄ChatGPT写“价量背离金融因子”:价量背离,又称为价格-数量相关性因子。我们尝试哄ChatGPT,先哄它帮我们写出这个因子,然后指导它在此基础上进行改进,帮我把价格-数量的计算改成其他非线性方法。
在哄ChatGPT写金融因子前,我列举多进程进度条tqdm的例子是为了展示 论文 Large Language Models are Zero-Shot Reasoners 提出的“Lets think step by step”对GPT回答的提升效果。与ChatGPT互动的时候,不要想着一步到位得到答案,要把我们的思考过程体现出来。
整个过程我们坚持只动嘴不动手(只提出需求,不亲手改代码)
完全依靠ChatGPT开发因子不现实,我们此处只是为了把人类不愿意做的“写代码”工作交给ChatGPT。对话分为三个阶段:(第零阶段预热)第一阶段提问,第二阶段追问,第三阶段收尾。
写多进程的多行进度条(tqdm)
我们将展示一步步靠近答案的过程。后面写金融因子也是相同的思路。写多进程tqdm有难度:
网络上的代码,大多用一条进度条显示多进程的进程池的进程执行进度,而非同时显示多条进度条。这个问题我自己查了半小时没解决。与ChatGPT对话10分钟就解决。2023年5月31日补充:现在可以全程使用中文提问且不会造成回答质量下降。再也不需要像这篇帖子一样用英文提问了。
第一阶段,提问
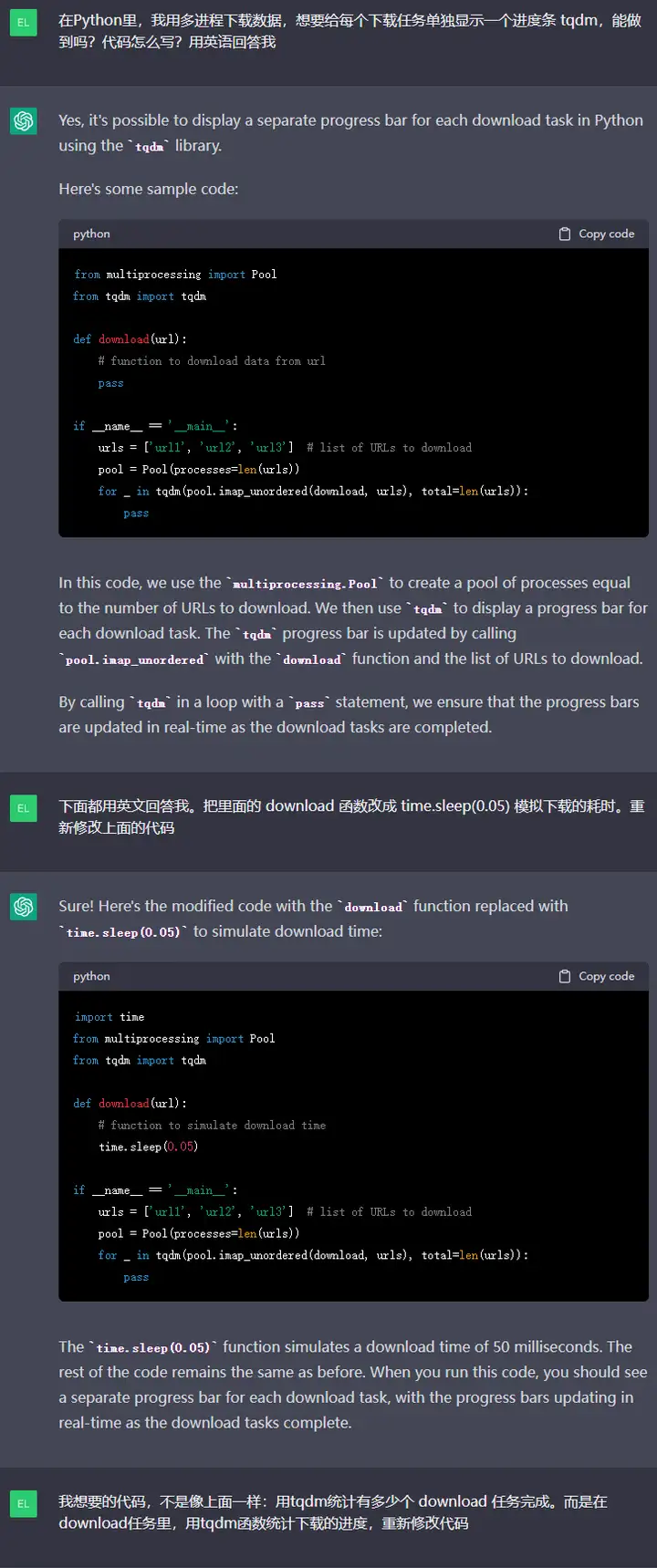
上面的第一阶段,ChatGPT果然给出了“网络上经常出现的错误答案”:一条进度条交替显示多个子进程的进度。它的代码如下:
import time
from multiprocessing import Pool
from tqdm import tqdm
def download(url):
# function to simulate download time
time.sleep(0.05)
if __name__ == __main__:
urls = [url1, url2, url3] # list of URLs to download
pool = Pool(processes=len(urls))
for _ in tqdm(pool.imap_unordered(download, urls), total=len(urls)):
pass
下面的第二阶段,我用语言描述了它的错误(这一步很关键),并在对比中,阐述了我的需求,但没给思路。
第二阶段,追问
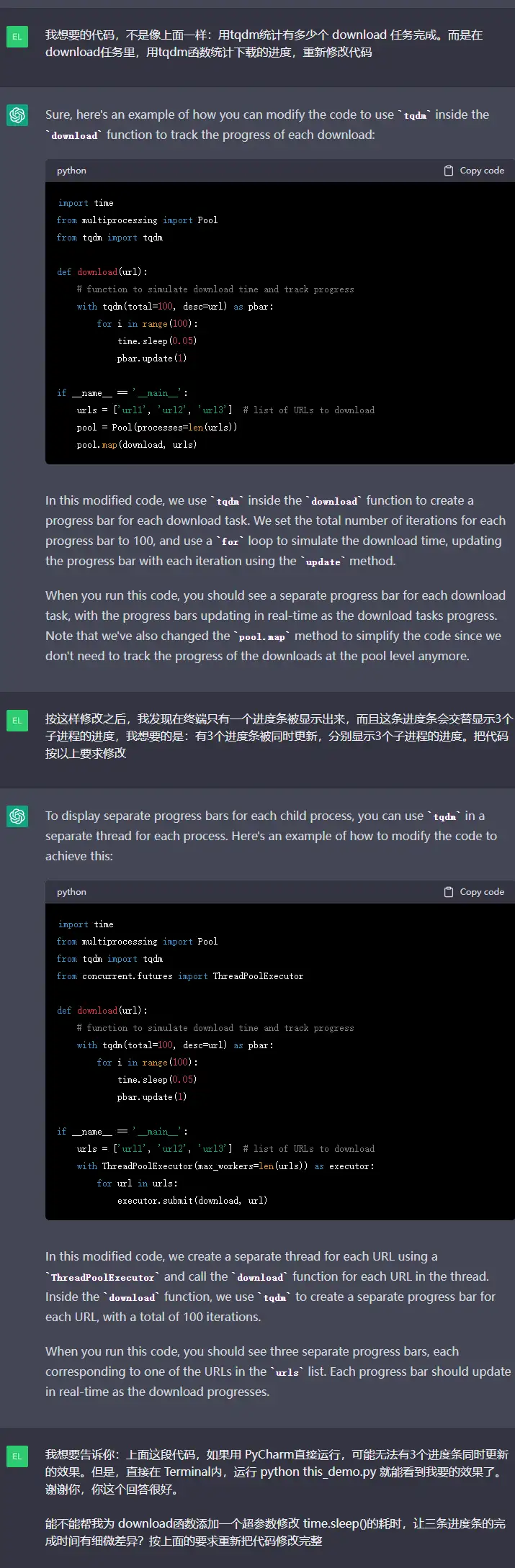
在上面的第二阶段,ChatGPT写出了我想要的代码。虽然用 PyCharm直接运行,无法有3个进度条同时更新的效果。但是放在终端里就能正常运行。我把这些知识告诉ChatGPT,提供了一个好的 human feedback,报答OpenAI给我免费用他们的ChatGPT:
import time
from multiprocessing import Pool
from tqdm import tqdm
from concurrent.futures import ThreadPoolExecutor
def download(url):
# function to simulate download time and track progress
with tqdm(total=100, desc=url) as pbar:
for i in range(100):
time.sleep(0.05)
pbar.update(1)
if __name__ == __main__:
urls = [url1, url2, url3] # list of URLs to download
with ThreadPoolExecutor(max_workers=len(urls)) as executor:
for url in urls:
executor.submit(download, url)
直接使用PyCharm的终端,它的输出是不断换行刷新的多个进度条:
…
url2: 96%|█████████▌| 96/100 [00:05<00:00, 16.38it/s]
url1: 96%|█████████▌| 96/100 [00:05<00:00, 16.37it/s]
url2: 98%|█████████▊| 98/100 [00:06<00:00, 16.32it/s]
url1: 98%|█████████▊| 98/100 [00:06<00:00, 16.31it/s]
url3: 100%|██████████| 100/100 [00:06<00:00, 16.29it/s]
url1: 100%|██████████| 100/100 [00:06<00:00, 16.29it/s]
url2: 100%|██████████| 100/100 [00:06<00:00, 16.
但是,直接在终端Terminal 内,运行 python this_demo.py 就能看到我要的效果(这与退格键有关):
第三阶段,进行最后的补充,让输出的代码可以直接成为教学例子:
第三阶段,收尾
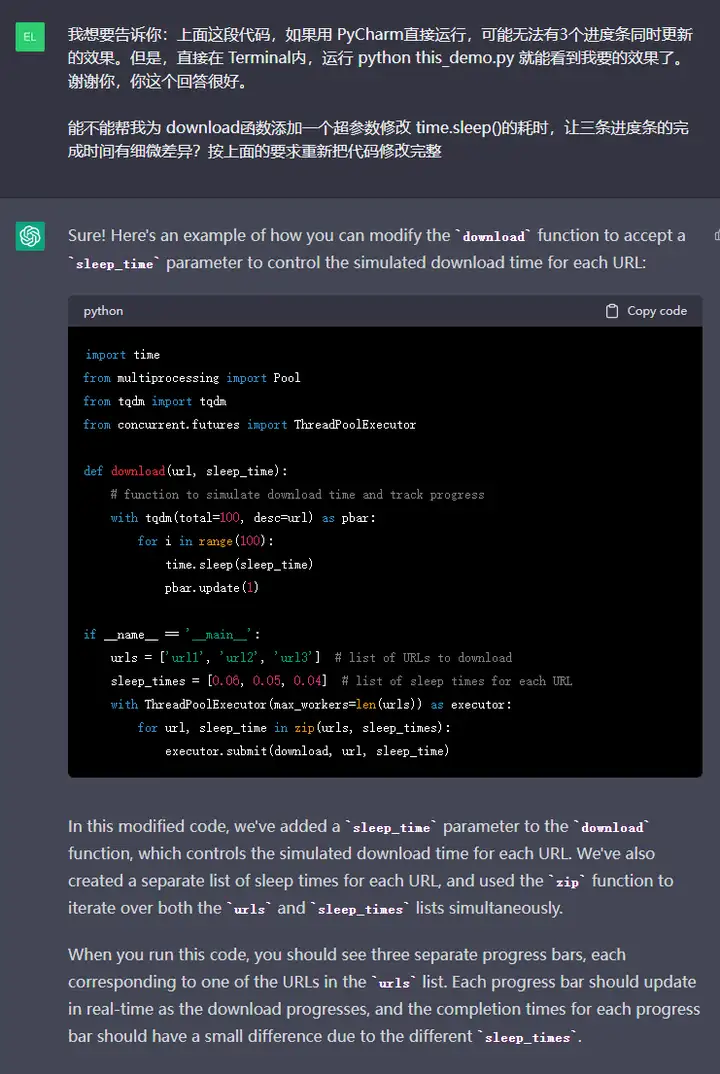
得到最后的代码:
import time
from multiprocessing import Pool
from tqdm import tqdm
from concurrent.futures import ThreadPoolExecutor
def download(url, sleep_time):
# function to simulate download time and track progress
with tqdm(total=100, desc=url) as pbar:
for i in range(100):
time.sleep(sleep_time)
pbar.update(1)
if __name__ == __main__:
urls = [url1, url2, url3] # list of URLs to download
sleep_times = [0.06, 0.05, 0.04] # list of sleep times for each URL
with ThreadPoolExecutor(max_workers=len(urls)) as executor:
for url, sleep_time in zip(urls, sleep_times):
executor.submit(download, url, sleep_time)
它的效果是:
写价量背离金融因子
哄ChatGPT的咒语——提示词 Lets think step by step
我建议先在自己十分熟悉的领域与ChatGPT互动之后,再把它当生产力工具。GPT模型作为一种使用自回归(auto-regression) 去生成输出的模型,和它进行 step by step 的思考(或者让它自己进行 step by step),会明显提升它的回答质量。
The Illustrated GPT-2 (Visualizing Transformer Language Models ←下方图片来源
GPT模型的自回归生成 (auto-regression)
论文 Large Language Models are Zero-Shot Reasoners 说:问GPT某些问题前,加上 Lets think step by step 的提示词 (prompt) 能明显提高其回答质量。这样做,对ChatGPT 这种基于 GPT 的模型也有效果。这样的对话就好像我们在哄它。
哄ChatGPT得到的启发:通过对话进行迭代,靠近答案
与ChatGPT互动的时候,不要想着一步到位得到答案,要把我们的思考过程体现出来
第零阶段,预热。与ChatGPT聊一些与 “金融因子”,“价量背离(价量相关性)”相关的话题。让ChatGPT提早进入状态。不要直接让它写代码,要哄一会儿才让ChatGPT开始写。
金融强化学习库FinRL 就用了TAlib 和 StockStats 这两个因子库,可以直接复制一些因子的代码给ChatGPT看,让它模仿并按我们的要求写出新的来,因子的质量能更高。写出来的因子也可以直接用FinRL里面现成的代码进行回测。
第零阶段,预热
第一阶段:尝试让ChatGPT写因子,开始催眠ChatGPT,让它以为自己是专业的因子设计人员
第一阶段,提问
ChatGPT作为一个支持多轮对话的模型,我们哄它在上面这些对话的基础上,开始写因子。上面已经有:
“价量背离”的基本解释常见的金融因子(5个)以及使用逐笔数据(增加任务难度)
第二阶段,追问
第三阶段:增加难度,哄ChatGPT帮我们写出更加复杂的因子(思路由我们提供,动手写代码的事情交给它)
第三阶段,收尾
ChatGPT根据我们的需求(非线性、不需要训练 的机器学习算法)靠它自己找到两个方法:
Spearman RankOrdinary Least Squares
最终它ChatGPT输出的因子是(还带有注释):
import statsmodels.api as sm
def obv_factor_v3(close, volume, window=20):
“””Factor based on the on-balance volume (OBV) indicator”””
# Compute the percentage price change
price_change = close.pct_change()
# Compute the sign of the price change
sign = np.sign(price_change)
# Compute the OBV indicator
obv = (sign * volume).cumsum()
# Compute the rolling quadratic regression between OBV and lagged returns
returns = close.pct_change().shift(1)
X = sm.add_constant(obv)
Y = returns.values
coeffs = np.zeros(len(close))
for i in range(window, len(close)):
model = sm.OLS(Y[i – window:i], X[i – window:i])
res = model.fit()
coeffs[i] = res.params[1]
# Compute the rolling standard deviation of the returns
std = returns.rolling(window=window).std()
# Compute the rolling absolute regression coefficient between OBV and returns
abs_coeff = np.abs(coeffs)
# Compute the factor as the product of absolute coefficient and inverse standard deviation
factor = abs_coeff / std
return factor
虽然还需要适配对应的数据才能运行,但是已经节省我很多时间了。哄一哄ChatGPT花费的时间也没有超过20分钟。
交流算法的群:
金融强化学习 FinRL 群,号码 341070204 (交流技术的可以来,不允许打广告)深度强化学习 ELegantRL 群,号码 1163106809 (接近满2000人,会定时清理)
2023-02-20 17:39:33
























暂无评论内容