
来源: 早起Python
作者: 萝卜
推荐系统将成为未来十年里最重要的变革
社会化网站将由推荐系统所驱动
— John Riedl明尼苏达大学教授
01前言
智能推荐和泛的营销完全不同,后者是将产品卖给客户作为最终目标;而智能推荐是以“客户需求”为导向的,是给客户带来价值的。常见的如淘宝的 “你可能还喜欢”,亚马逊的 “购买此商品的用户也购买了” 便是实例。本文就将详细介绍如何用Python实现智能推荐算法,主要将分为两个部分:
详细原理介绍Python代码实战02常见的推荐系统与算法
常见的推荐系统分类有:
基于应用领域: 电子商务/社交好友推荐等基于设计思想: 基于协同过滤的推荐等基于使用数据: 基于用户标签的推荐等
“ 京腾 ” 合作构建用户画像标签图
常见的推荐算法有:
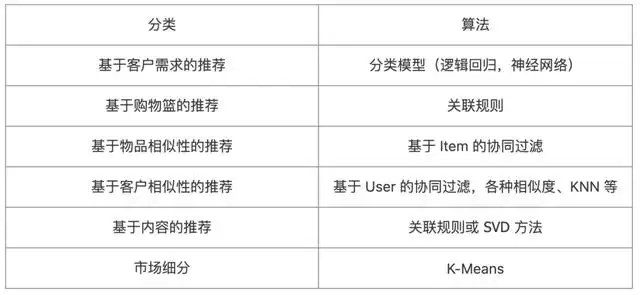
本文将专注于理解起来最容易且又十分经典常用的基于关联规则的购物篮推荐。商品的关联度分析对于提高商品的活力、挖掘消费者的购买力、促进最大化销售有很大帮助。其建模理念为:物品被同时购买的模式反映了客户的需求模式,适用场景:无需个性化定制的场景;有销售记录的产品,向老客户推荐;套餐设计与产品摆放。
03购物篮简介
问:什么是购物篮?主要运用在什么场景?
答:单个客户一次购买商品的综合称为一个购物篮,即某个客户本次的消费小票。常用场景:超市货架布局:互补品与互斥品;套餐设计。

问:购物篮的常用算法?
答:常用算法有
不考虑购物顺序:关联规则。购物篮分析其实就是一个因果分析。关联规则其实是一个很方便的发现两样商品关系的算法。共同提升的关系表示两者是正相关,可以作为互补品,如豆瓣酱和葱一起卖也才是最棒的。替代品的概念便是我买了这个就不用买另外一个。考虑购物顺序:序贯模型。多在电商中使用,比如今天你将这个商品加入了购物车,过几天又将另一个商品加入了购物车,这就有了一个前后顺序。但许多实体商店因为没有实名认证,所以无法记录用户的消费顺序。问:求出互补品与互斥品后对布局有什么用?
答:根据关联规则求出的商品间的关联关系后,可能会发现商品间存在强关联,弱关联与排斥三种关系。每种清醒有各自对应的布局方式。
强关联:关联度的值需要视实际情况而定,在不同的行业不同的也业态是不同的。强关联的商品彼此陈列在一起会提高双方的销售量。双向关联的商品如果陈列位置允许的话应该相关联陈列,即A产品旁边有B,B产品边上也一定会有A,比如常见的剃须膏与剃须刀,男士发油与定型梳;而对于那些单向关联的商品,只需要被关联的商品陈列在关联商品旁边就行,如大瓶可乐旁边摆纸杯,而纸杯旁边则不摆大瓶可乐,毕竟买大可乐的消费者大概率需要纸杯,而购买纸杯的顾客再购买大可乐的概率不大。弱关联:关联度不高的商品,可以尝试摆在一起,然后再分析关联度是否有变化,如果关联度大幅提高,则说明原来的弱关联有可能是陈列的原因造成的。排斥关系:指两个产品基本上不会出现在同一张购物小票中,这种商品尽量不要陈列在一起。根据购物篮的信息来进行商品关联度的分析不仅仅只有如上三种关系,它们仅代表商品关联度分析的一个方面(可信度)。全面系统的商品关联分析必须有三度的概念,三度包括支持度,可信度和提升度。
04关联规则
直接根据关联三度所定义的概念去理解会有不少难度,尤其是可信度喝提升度中的“ 谁对谁 ”的问题。其实可以换一种方式来看:
规则 X 的支持度 = 规则 X 的交易次数 / 交易的总数。理解:支持度表示规则 X 是否普遍。规则 X(A→B) 的置信度 = 规则 X 的交易次数/规则X中商品B 的交易次数。理解:置信度是一种条件概率,表示购买了A产品的客户再购买B产品的概率。
为方便理解这些规则,我们通过下面五个购物篮的例子来练习一下
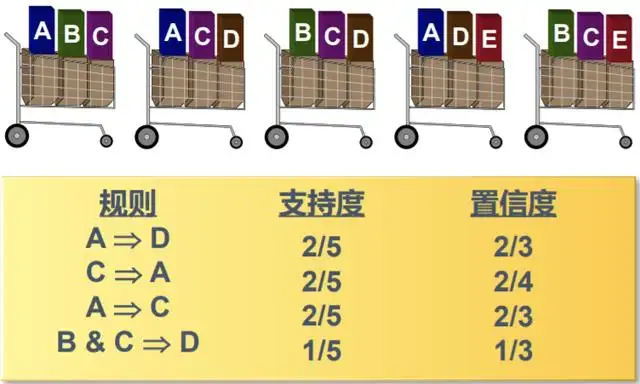
不难发现,支持度的分母都是5,也就是购物篮的数量,分子则是选取这个规则中的所有商品同时出现在一个篮子的次数。以A->D为例,同时包含A和D的篮子有2个,总的交易数量(篮子总数)有5个,所以规则A->D的支持度为2/5;有商品 A 的篮子个数为3,在这三个篮子中,其中2个篮子又包含商品D,所以该规则的置信度(可信度)为2/3。有关关联规则,还有以下两个问题想补充:
问:仅看支持度和置信度是否靠谱?
答:看一个案例:食堂卖饭,1000份打饭记录中,买米饭的有800人次,买牛肉的有600人次,两个共同买的有400人次,那么可以得出对于规则(牛肉 – > 米饭)Support=P(牛肉&米饭)= 400/1000=0.40;Confidence=P(米饭|牛肉)=400/600=0.67置信度和支持度都很高,但是给买牛肉的人推荐米饭有意义吗?显然是没有任何意义的。因为无任何条件下用户购买米饭的概率:P(米饭)=800/1000=0.8,都已经大过买了牛肉的前提下再买米饭的概率 0.67,毕竟米饭本来就比牛肉要畅销啊。
这个案例便引出了提升度的概念:提升度 = 置信度/无条件概率=0.67/0.8。规则 X(A→B) 的提升度为 n 时:向购买了 A 的客户推荐 B 的话,这个客户购买 B 的概率是 TA 自然而然购买 B 的 n × 100% 左右。生活理解:消费者平时较少单独购买桌角防撞海绵,可能偶尔想到或自己小孩碰到的时候才会想起购买,如果我们在桌子(书桌饭桌)的成功下单页面添加桌角防撞海绵的推荐,则很大程度上可以提高防撞海绵的销量。这也符合我们希望通过畅销商品带动相对非畅销商品的宗旨。
问:除了公式的含义,关联三度(支持度,置信度,提升度)还有什么关联吗?
答:可以这样理解:
支持度代表这组关联商品的份额是否够大置信度(可信度)代表关联度的强弱而提升度则是看该关联规则是否有利用价值和值得推广,用了(客户购买后推荐)比没用(客户自然而然的购买)要提高多少。所以 1.0 是提升度的一个分界值,刚才的买饭案例中给买了牛肉的用户推荐米饭的这种骚操作的提升度小于 1 也就不难理解了。另外,高置信度的两个商品(假设达到了 100%,意味着它们总是成双成对的出现),但如果支持度很低(意味着份额低),那它对整体销售提升的帮助也不会大。
05基于Apriori 算法的Python实战
由于有关Apriori等算法的研究已经很成熟,我们在用Python实战时无需一步一步计算,直接调用现有函数即可,主要是要明白背后的原理与不同算法的使用场景与优劣比较。
探索性分析
首先导入相关库并进行数据探索性分析
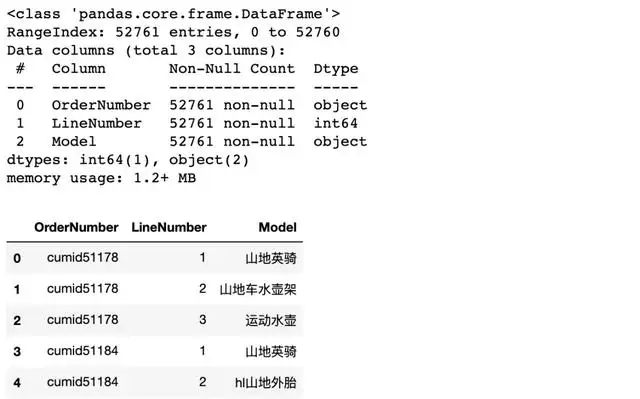
数据参数解释
OrderNumber:客户昵称LineNumber:购买顺序,如前三行分别表示同一个客户购买的三样商品的顺序Model:商品名接着来看看商品的种类

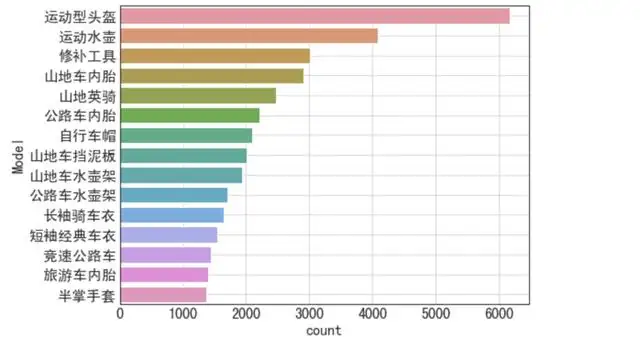
再来看看最畅销的 15 种商品

再进行一些简单的可视化
使用 Apriori 算法求解关联规则
首先生成购物篮,并将同一个客户购买的所有商品放入同一个购物篮,需要提前使用pip install Apriori安装,之后我们使用 Apriori 包中的 dataconvert 函数,下面是需要传入的参数解释
arulesdata:数据集 — DataFrametidvar: “分类的索引”,即划分购物篮的标准,本案例是根据客户 OrderNumber — object类型itemvar:将什么东西放进篮子里,本案例是将数据集中的商品,就是 Model 列放入篮子 — object类型data_type: 默认选择 inverted,库中提供的不变注意:需要注意传入的参数类型,只要对了,直接套用就不是什么难事
现在查看前五个购物篮中的物品

现在生成关联规则,根据排列组合,可知这些交易将会产生 21255×21254÷2 这么多个关联规则。首先就要满足支持度的要求,太小则直接被删去,支持度的大小可根据关联规则的多少调整 如果关联规则很少,可根据实际情况放宽支持度的要求。相关参数说明:
+ minSupport:最小支持度阈值+ minConf:最小置信度阈值+ minlen:规则最小长度+ maxlen:规则最大长度,一般2就够了这里,minSupport 或 minConf 设定越低,产生的规则越多,计算量也就越大

结果说明: 以 result 第一行为例
+ lhs: 被称为左手规则,通俗理解即用户购买的商品 – 山地车内胎+ rhs: 被称为右手规则,通俗理解即根据用户购买某商品来推荐的另一件商品 – ll山地胎+ support: 支持度,山地车内胎 和 ll山地胎 同时出现在一张购物小票中的概率+ confidence: 置信度,购买了 山地车内胎 的前提下,同时购买 ll山地胎 的概率+ lift:向购买了 山地车内胎 的客户推荐 ll山地胎 的话,这个客户购买 ll山地胎 的概率是这个客户自然而然购买 ll山地胎 的 400% 左右,即高了300% 多!现在我们筛选互补品和互斥品,代码如下
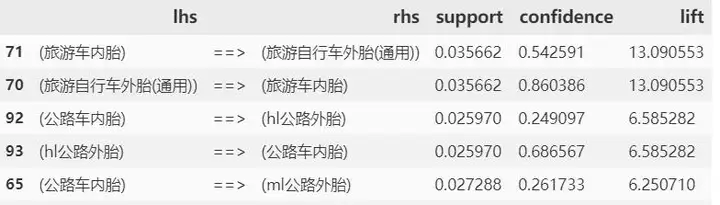
对结果简单分析一些,不要期望每个规则都有意义,要结合业务思考,比如竞速型赛道自行车与运动水壶互斥实属正常,竞速讲究轻量化,还配个水壶干什么… 比如山地车配一个竞速公路车用的运动型头盔…互斥产品则是成对出现的!
根据关联规则结果推荐产品
需要结合业务需求
获得最大营销响应度?– 看置信度,越高越好销售最大化?– 看提升度,越高越好用户未产生消费,我们向其推荐商品?以获得最高的营销相应率为目标
如果一个新客户刚刚下单了山地车英骑这个产品,如果希望获得最高的营销响应率,那在他付费成功页面上最应该推荐什么产品?
目标:获得最高的营销响应率

以最大化总体销售额为目标
如果一个新客户刚下单了山地英骑这个产品,如果希望最大化提升总体的销售额,那么在他付费成功的页面上应该推荐什么产品?
目标:最大化销售额

再次重申提升度通俗含义:提升度是相对于自然而然购买而言,A对B的提升度为4.0的理解如下:向购买了A的用户推荐B,则该用户购买B的概率是该用户单独(即自然而然的购买)购买B的概率的 400% 向购买了A的用户推荐B,则该用户购买B的概率比该用户单独(即自然而然的购买)购买B的概率高300%!
用户并未产生消费,为其推荐某样商品

最后总结一下,基于关联规则的 Apriori 算法是智能推荐领域十分经典的应用之一,简单易上手。其实推荐领域的难点不一定在于算法,而在于过大的客户量与其产生的数据,所以一般到了最后用的都是混合推荐。至于更深层次的序贯模型与协同过滤,几乎没有人使用 Python 或 R 来实现,大部分都是使用分布式框架如 Spark,后续也会推出相关文章。

















暂无评论内容