
原标题:从离线到实时数据生产,网易湖仓一体设计与实践
本文根据周劲松老师在【第十三届中国数据库技术大会(DTCC2022)】线上演讲内容整理而成。
随着大数据实时化进程的不断推进,实时与离线在开发链路与数据存储上割裂的问题逐渐凸显,这不仅造成了实时与离线在开发人员与存储成本上的双倍投入,还造成了实时与离线指标不统一的问题。新的湖仓一体架构旨在统一实时与离线的数据存储,进一步解决实时与离线割裂的问题。网易基于Apache Iceberg,在之上构建了一套湖仓一体系统——Arctic,该系统在廉价的数据湖之上统一了流批存储,并提供了数据约束、结构自优化、数据一致性、实时订阅和实时Join等特性。
数据开发现状与痛点
网易的数据开发在几年之前,还是以T+1 离线数据生产为主,数据源头来自数据库或者大量业务日志,比如客户端的日志、服务器的日志,或者是传感器的数据,大量的原始数据进入离线数仓后,会做数据分层的开发,数据分层是为了数据复用,而需求是多样的,不可能每个需求都从原始到最终结果,都去做完整的一次数据处理,这样会浪费大量存储和计算成本。
分层,用的比较传统的这种 ODS层、 DWD层、 DWS 层、 ADS层这么一个架构,分层的数据主要存储在 Hive 里,计算引擎最开始用 Hive SQL,后面全部转向了 Spark SQL,去做这样的数据开发。
如果到了轻度汇聚层或者数据集市层的话,要去做一些实时分析,中间会用到Impala 这样的系统,这是一个比较传统的T+1的离线数据生产的过程,基本上都是凌晨开始去调度,然后在第二天的早上产出结果。
1)、初步引入实时化
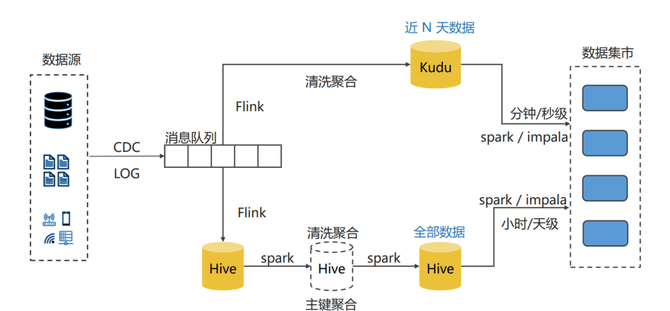
随着业务系统的发展,对数据分析需求的增加,企业就不再满足于这种T+1的状态。一天的数据延迟,现在已经不够用了,希望数据分析可以是低延迟,特别是AI的一些应用,对数据延迟要求更高,这时就要引入实时的这么一个链路。
实时链路,当时的做法跟现在很多企业一样,那就是在T+1的链路之上,重新去构造了一个实时链路。实时链路的存储用消息队列,计算引擎是 Flink。但是 ,Flink 在当初开始使用的时候,很难像 Hive一样去做数据分层。所以,大部分人的业务都是根据实际的需求,就去写一个Flink任务,从源头把数据接进来,经过聚合清洗之后,写到像Kudu这样的实时的数仓里面,然后在实时数仓里面去做分析,或者可以直接接到其他支撑实时更新的系统,比如数据库。
如此一来,原有的系统分成了两条链路,实时这条链路基本上按需开发,没有什么很好的设计规范,可能会存在着很多的重复的计算,就是你有需求你就去开发。
2)、更复杂的实时化
随着实时这条链路的业务越来越多,简单地去写一个 Flink 任务已经搞不定了,在实时场景下,逻辑会越来越复杂。比如:实时场景下,需要一些维度数据,以前在离线场景下,维度表是存在 Hive 上,一张 Hive 表就够了。但是 Hive 表,没办法去做实时的点查询。所以说我可能还要引入一些k v系统,比如说一套Hbase,然后在上面去做点查。
另外,实时链路没有数据分层,数据复用度很差,资源浪费很严重。所以,开始在实时链路上去做一些数据分层,比如:会把一些清洗好的表,或者一些公共要使用的表,把它放到一个单独的kafka topic里面。当时,整个实时链路里面,存储还是以kafka为主,然后会引入 Hbase去做 k v,会去做简单的分层,最终数据还是落到 Kudu上。在业务应用上, Kudu没办法存储大量的历史数据,因为成本比较高。所以,如果在业务使用的时候,如果既用到历史数据,也用到最近实时的数据,会把这种历史的 Hive 的数据和 Kudu里面最近的数据在做一个业务层面上去做一个聚合统一之后,然后再返回给业务系统。
3)、流批分割的Lambda架构
在典型的 Lambda 架构与流批分割的这种数据开发模式下,遇到了什么样的问题呢?
第一,数据孤岛的问题。只有离线的时候,业务架构非常简单,存储是一套系统,就Hive、 Hadoop,计算是用的Spark或者用Hive SQL。引入实时之后,我们用到的系统变得多样化,比如:要用Hbase、kafka、Kudu,甚至很多业务系统用Doris,用ClickHouse。
简单理解,企业需要去用不同的存储系统,去满足实时上面的一些需求。同时,这些存储系统一般都需要独立采购和部署,而且他们的成本相较于 Hive 这样的分布式系统,其实成本会更高。并且,里面的这些数据也没办法复用,在离线这边还得再存一套,需要用一些同步工具把这些实时的数据再同步到离线里面来。
第二,研发体系的割裂,主要是实时和离线用不同的语言开发,虽然要达成相同的业务目标,但是可能要用 Spark SQL 写一遍,然后再用 Flink SQL 写一遍,甚至有的SQL没办法表达。更复杂一点,可能要用不同的方法去实现,比如 :Stream API或者Batch API。
在大部分场景下,其实在公司内部,实时和离线开发同学是不同人员,他们在技术栈上存在着差异,由此造成研发人效低,研发规范不通用,实时和离线都要处理相同的需求。大家会各建各的表,各建各的任务。最终,还有一个更大的一个问题,大家产出的数据经常在使用的时候要去统一使用,虽然你要解决相同的需求,但是前面的语言,使用的表达定义都完全不一样,怎么能够保证最终在使用的时候,或者说去聚合离线和实时产生接入的时候,保证数据的正确性呢?这就会带出指标和语义的二元性问题!
基于Apache Iceberg的湖仓一体系统Arctic
面对上述问题,网易如何应对?新型的数据湖格式,主要有三种Iceberg、Hudi、Delta,他们有一个特点,就是可以做流批统一,不像之前传统的Hive 表,只能去做离线写入,实时写入会很麻烦,因为没有一套很好的ACID机制,同一个表只能有一个任务去读,并且读写也不能并发。
换言之,你要去做流批一体的支持,首先需要去做这种读写并发的支持,其次这套存储系统能够去接受流式的去写入,批量的写入,也能够去接受流式的读取,批量的读取,这是流批一体的基础。而当时 Iceberg 和 Hudi 其实他们已经逐渐的有了这样的能力,这种新型的数据湖格式都有统一的特点,比如:流批的读写接口都具备,同时得有ACID的能力,流批一体可以并发去读写。
此种背景下,网易通过引入新型的数据湖表格式去解决流批分割的问题。而且,像Iceberg、Hudi都有实时更新的能力,以前 Hive 肯定做不到,要去更新一条数据,可能就要对整个表进行重写了。Iceberg、Hudi可以做到行级更新或者删除一条数据,对于数据库接入的数据就会非常友好,还可以流式地去实时更新湖仓里面的数据。
至于,为什么选择Iceberg,而没有选Hudi?是因为当时的Hudi对Flink没有很好的支持!而企业内部的实时计算,基本上都是用 Flink 做的,投入网易内部去使用的其实是Iceberg,然后把Iceberg引入之后,的确解决了很多以前使用 Hive 上遇到的问题。
但是,同时也发现,想直接去使用Iceberg去解决前面提到的问题,其实是存在着一些挑战。此种背景下,网易基于Iceberg自己研发了一套服务,并且现在开源了这套湖仓一体的管理服务。虽然,网易内部叫湖仓一体系统,但更准确的定义是湖仓管理服务,叫Arctic。
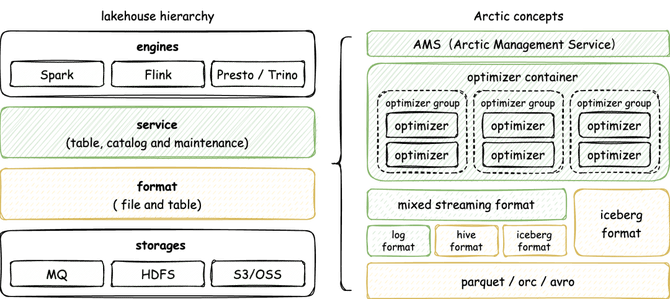
Arctic的底层存储公司内部用的是HDFS,但外部应用很多都已经上云,比如S3或者阿里云的OSS,如果是消息数据存储,大部分会存在MQ上。MQ也是低延迟消息的一种存储,在这之上就是format和 service 层,再之上就是引擎层,包括 Spark 、Flink,一个去做批量的这种任务开发,一个去做实时的任务开发,然后 presto、Trino 这些去做了一些 AP 分析,它都是我们的计算引擎。中间两层其实就是核心应用会覆盖到的两个层级,而Iceberg自己就是一个很好的format,所以可以直接用iceberg 作为table format。
但是,前面提到直接用Iceberg 去做table format,可能在某些业务场景下还是会有些问题,所以网易在Iceberg 之上做了重新设计,也就是Mixed streaming format,它最大优势是面向这种流式场景,去补足暂时现阶段Iceberg可能存在的一些不足。
但是,Mixed streaming format和Iceberg format包括Hive format,都可以理解是并行的格式,你在这套系统里面用哪一种 format 的表都没有问题。其次,在这套系统里面,不只是一个纯粹的面向数据湖、面向文件的这么一个存储系统,还是会去考虑实时场景下,需要消息队列提供的这种毫秒级延迟,所以说它还要用 log format 这样的概念。log format在我们的消息队列之上,消息队列设计的格式也是放在Mixed streaming format之下。
再上层,就是 service 层,主要有两核心,一个就是AMS(Arctic Management service)这么一个服务,它会去存储一些元数据,同时还有数据湖里的一些管理能力,包括对数据湖里面的表去做监控,去做优化。通过optimizer container一套完整的资源管理,可以去做分布式的多表并发的优化。optimizer 要调度到不同的基础设施上,比如k8s、yarn或者直接调度到物理机上,不同的调度方式会有不同的 optimizer container 实现。
一个 optimize container对应着一个集群,这个集群里可能有不同的队列,即optimizer group。在这个队列内部会起很多的任务,那就是optimizer。对于很多表,会去选择一个optimizer group,你的表的所有的这种优化的任务都会放在 group 下,不同的表放到不同的 group 下,就可以去做到资源隔离。那Ams + optimizer ,这套机制就是网易现阶段service 层的一个核心。
面向开放式架构的诸多功能创新
arctic是一个开放式架构下的湖仓管理系统,首先它面向开放式架构,面向不同的 table format。现在,主要面向 Iceberg format,然后企业自己也在Iceberg之上有一套Mixed streaming format的实现。以后也会去尝试去对接更多的 table format,比如说 Hudi 或者Delta,我们认为他们有管理优化等相同的需求,arctic 都是可以作为一套湖仓管理系统去对接这些format。arctic是在开放的表格式之上,首先它与Iceberg 、Hudi不是竞争关系,arctic是这些技术之上的管理服务。Arctic面向场景更多地关注流和实时更新的场景,并且提供一套可插拔的数据自优化的管理服务。
以Schema evolution为例,前面提到的Iceberg format,那它就是原生的 Iceberg 表。也就是说,如果你已经是Iceberg的用户,你已经在用Iceberg表了,那你可以非常轻量的把arctic作为一个管理服务单独部署起来。相较于以前传统的Hive 表,Iceberg format表结构可以支持非常自由的变更。Hive 表的表结构变更其实是有一些限制的,因为 Hive 下面的文件有自己的schema,它自己也存了表的 schema 信息,他们之间是用名字去做映射。这种情况下,去做一些结构变更,可能就会有些风险,比如要做一些 rename 变更,rename完了以后发现,在老的文件里面已经找不到这一个字段了,那老的数据就会读不到了。在网易内部,Hive只会去做一种schema 异步,就是加字段,那这样的话会很大程度地限制源端数据库,只能加字段。
再比如:Hidden partitioning。如何理解呢?使用 Hive 的用户和使用数据库的用户,可能在 partition 上面的理解上其实是有很大的不足。Hive 的 partition是一个额外的字段,这些额外的字段你要在写入的时候写进去,读的时候要把这个额外字段作为一个条件,放到额外条件里,这样才能够用到这些分区的能力。
但是,对于数据库的用户,建立分区本身它是一个运维侧的事情,对于业务来说,写入和查询都不考虑分区,我直接按业务字段的条件去写 SQL 就好了。那 Hidden partitioning 就是用一样的概念,你的分区不再是一些表上的额外字段,你在写入和读取的时候也不用再去关心它,只是你表中已有字段上面的一些转换关系。比如:要在一个时间字段上按天去做分区,那你这个分区配置就是在时间字段上一个取天的一个函数,然后以后你在这个时间字段上去做条件的过滤,它就可以自动的去映射到分区上面,帮你去做高效的过滤了。
与此同时,Time travel(解决冗余数据存储问题)、Serialization isolation(数据一致性解决方案)、 Fast scan planning(快速找到需要读的文件)等等,都是Iceberg format一些功能优势,这里不详细赘述!
而Mixed streaming format关键特性是:更强的主键约束和流批通用 、Auto-Bucket 提升 OLAP 性能 、LogStore 提供秒级 Data pipeline 、Hive / Iceberg 格式兼容 、事务冲突解决机制。包括Self-optimizing可以解决自动、异步与透明问题,资源隔离与共享,以及灵活可扩展的部署方式等。
未来规划
从 IT 定位来说,湖仓一体核心内容就两块,一个是更强的管理能力,另一个就是更强的OLAP性能,未来网易会在这两个方面继续增强。比如:数据湖权限问题、更多的监控项以及热表与慢查询、多数据中心和多云管理等等。同时,OLAP方面,会支撑更好的排序,去提升排序字段上的这种范围查询的性能。虽然Iceberg 也有sort order 的能力,但只能有一套sort order,你的数据和查询条件非常多,引入太多的排序字段,可能最终也得不到一个很好的性能。一个方向是,要根据不同的这种排序字段去建立不同的副本,来提升你的查询能力。
另外,聚合key,我们可以理解为预聚合,通过Arctic能不能去做一些预聚合的事情?这些都建立在base store、 change store架构之上,每个 base store 有不同的排序规则,change store写进来的都是CDC数据,能够做排序和聚合支持,包括可以支持二级索引。其中,Mixed streaming format是OLAP性能提升的一个关键!
嘉宾介绍:
网易平台研发专家 周劲松
从事大数据与数据库方向开发工作7年,曾负责网易分布式数据库与数据传输系统的研发工作,目前作为Arctic流批一体数据湖的项目负责人,在构建数据基础设施方面有着充分的开发与实践经验。返回搜狐,查看更多
责任编辑:



















暂无评论内容