
本文作者为京东算法服务部的张颖和段学浩,并由 Apache Hive PMC,阿里巴巴技术专家李锐帮忙校对。主要内容为:
1.背景
2.Flink SQL 的优化
3.总结一、背景
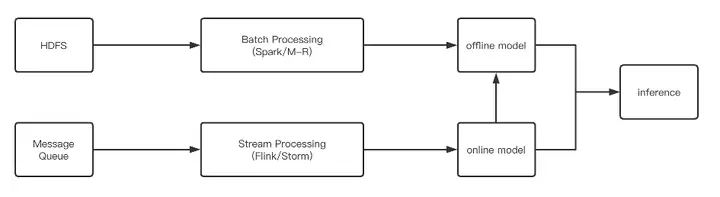
目前,京东搜索推荐的数据处理流程如上图所示。可以看到实时和离线是分开的,离线数据处理大部分用的是 Hive / Spark,实时数据处理则大部分用 Flink / Storm。
这就造成了以下现象:在一个业务引擎里,用户需要维护两套环境、两套代码,许多共性不能复用,数据的质量和一致性很难得到保障。且因为流批底层数据模型不一致,导致需要做大量的拼凑逻辑;甚至为了数据一致性,需要做大量的同比、环比、二次加工等数据对比,效率极差,并且非常容易出错。
而支持批流一体的 Flink SQL 可以很大程度上解决这个痛点,因此我们决定引入 Flink 来解决这种问题。
在大多数作业,特别是 Flink 作业中,执行效率的优化一直是 Flink 任务优化的关键,在京东每天数据增量 PB 级情况下,作业的优化显得尤为重要。
写过一些 SQL 作业的同学肯定都知道,对于 Flink SQL 作业,在一些情况下会造成同一个 UDF 被反复调用的情况,这对一些消耗资源的任务非常不友好;此外,影响执行效率大致可以从 shuffle、join、failover 策略等方面考虑;另外,Flink 任务调试的过程也非常复杂,对于一些线上机器隔离的公司来说尤甚。
为此,我们实现了内嵌式的 Derby 来作为 Hive 的元数据存储数据库 (allowEmbedded);在任务恢复方面,批式作业没有 checkpoint 机制来实现failover,但是 Flink 特有的 region 策略可以使批式作业快速恢复;此外,本文还介绍了对象重用等相关优化措施。
二、 Flink SQL 的优化
1. UDF 重用
在 Flink SQL 任务里会出现以下这种情况:如果相同的 UDF 既出现在 LogicalProject 中,又出现在 Where 条件中,那么 UDF 会进行多次调用 (见https://issues.apache.org/jira/browse/FLINK-20887)。但是如果该 UDF 非常耗 CPU 或者内存,这种多余的计算会非常影响性能,为此我们希望能把 UDF 的结果缓存起来下次直接使用。在设计的时候需要考虑:(非常重要:请一定保证 LogicalProject 和 where 条件的 subtask chain 到一起)
一个 taskmanager 里面可能会有多个 subtask,所以这个 cache 要么是 thread (THREAD LOCAL) 级别要么是 tm 级别;为了防止出现一些情况导致清理 cache 的逻辑走不到,一定要在 close 方法里将 cache 清掉;为了防止内存无限增大,选取的 cache 最好可以主动控制 size;至于 “超时时间”,建议可以配置一下,但是最好不要小于 UDF 先后调用的时间;上文有提到过,一个 tm 里面可能会有多个 subtask,相当于 tm 里面是个多线程的环境。首先我们的 cache 需要是线程安全的,然后可根据业务判断需不需要锁。根据以上考虑,我们用 guava cache 将 UDF 的结果缓存起来,之后调用的时候直接去cache 里面拿数据,最大可能降低任务的消耗。下面是一个简单的使用(同时设置了最大使用 size、超时时间,但是没有写锁):
2. 单元测试
大家可能会好奇为什么会把单元测试也放到优化里面,大家都知道 Flink 任务调试过程非常复杂,对于一些线上机器隔离的公司来说尤甚。京东的本地环境是没有办法访问任务服务器的,因此在初始阶段调试任务,我们耗费了很多时间用来上传 jar 包、查看日志等行为。
为了降低任务的调试时间、增加代码开发人员的开发效率,实现了内嵌式的 Derby 来作为 Hive 的元数据存储数据库 (allowEmbedded),这算是一种优化开发时间的方法。具体思路如下:
首先创建 Hive Conf:
接下来创建 Hive Catalog:(利用反射的方式调用 embedded 的接口)
创建 tableEnvironment:(同官网)
最后关闭 Hive Catalog:
此外,对于单元测试,构建合适的数据集也是一个非常大的功能,我们实现了 CollectionTableFactory,允许自己构建合适的数据集,使用方法如下:
3. join 方式的选择
传统的离线 Batch SQL (面向有界数据集的 SQL) 有三种基础的实现方式,分别是 Nested-loop Join、Sort-Merge Join 和 Hash Join。
效率空间备注Nested-loop Join差占用大Sort-Merge Join有sort merge开销占用小有序数据集的一种优化措施Hash Join高占用大适合大小表Nested-loop Join 最为简单直接,将两个数据集加载到内存,并用内嵌遍历的方式来逐个比较两个数据集内的元素是否符合 Join 条件。Nested-loop Join 的时间效率以及空间效率都是最低的,可以使用:table.exec.disabled-operators:NestedLoopJoin 来禁用。以下两张图片是禁用前和禁用后的效果 (如果你的禁用没有生效,先看一下是不是 Equi-Join):Sort-Merge Join 分为 Sort 和 Merge 两个阶段:首先将两个数据集进行分别排序,然后再对两个有序数据集分别进行遍历和匹配,类似于归并排序的合并。(Sort-Merge Join 要求对两个数据集进行排序,但是如果两个输入是有序的数据集,则可以作为一种优化方案)。Hash Join 同样分为两个阶段:首先将一个数据集转换为 Hash Table,然后遍历另外一个数据集元素并与 Hash Table 内的元素进行匹配。第一阶段和第一个数据集分别称为 build 阶段和 build table;第二个阶段和第二个数据集分别称为 probe 阶段和 probe table。Hash Join 效率较高但是对空间要求较大,通常是作为 Join 其中一个表为适合放入内存的小表的情况下的优化方案 (并不是不允许溢写磁盘)。注意:Sort-Merge Join 和 Hash Join 只适用于 Equi-Join ( Join 条件均使用等于作为比较算子)。
Flink 在 join 之上又做了一些细分,具体包括:
特点使用Repartition-Repartition strategy对数据集分别进行分区和shuffle,如果数据集大的时候效率极差两个数据集相差不大Broadcast-Forward strategy将小表的数据全部发送到大表数据的机器上两个数据集有较大的差距Repartition-Repartition strategy:Join 的两个数据集分别对它们的 key 使用相同的分区函数进行分区,并经过网络发送数据;Broadcast-Forward strategy:大的数据集不做处理,另一个比较小的数据集全部复制到集群中一部分数据的机器上。众所周知,batch 的 shuffle 非常耗时间。
如果两个数据集有较大差距,建议采用 Broadcast-Forward strategy;如果两个数据集差不多,建议采用 Repartition-Repartition strategy。可以通过:table.optimizer.join.broadcast-threshold 来设置采用 broadcast 的 table 大小,如果设置为 “-1”,表示禁用 broadcast。
下图为禁用前后的效果:
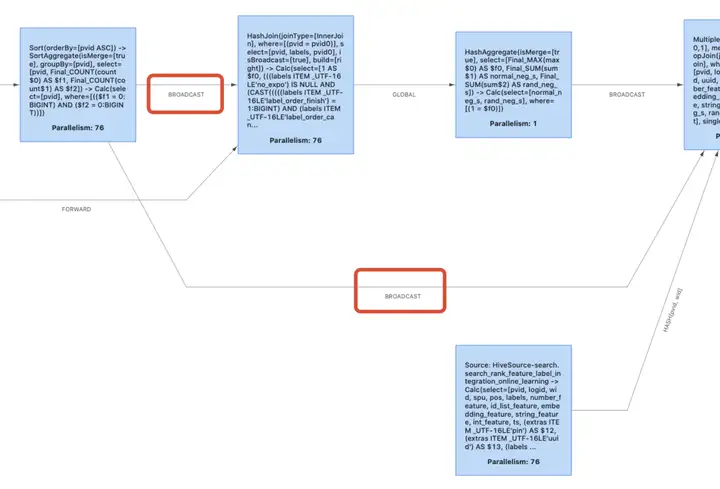
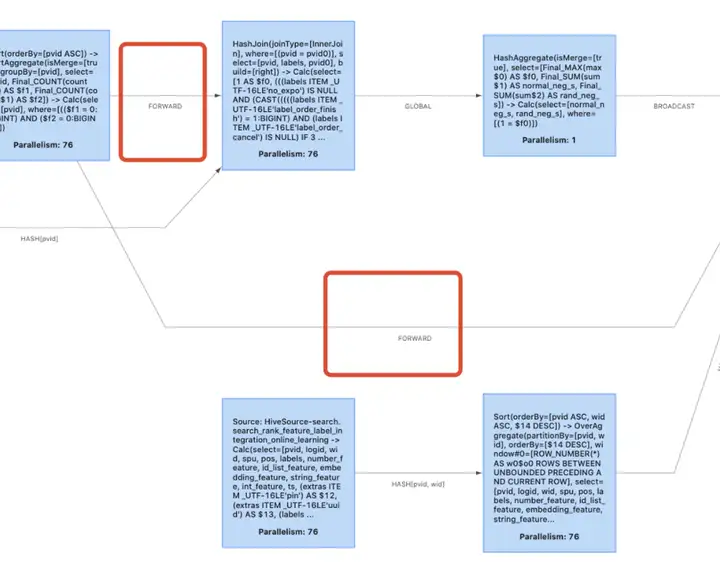
4. multiple input
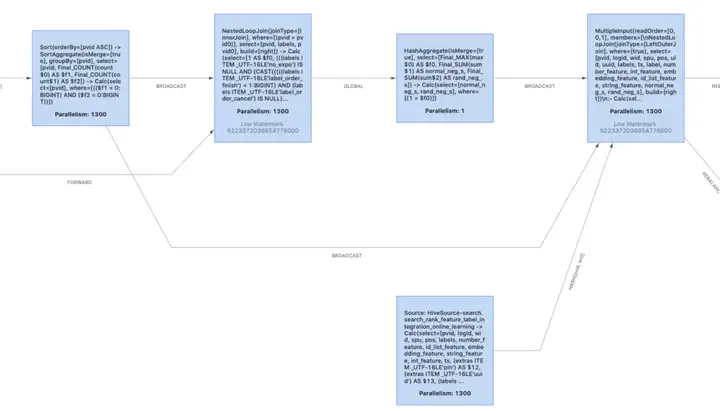
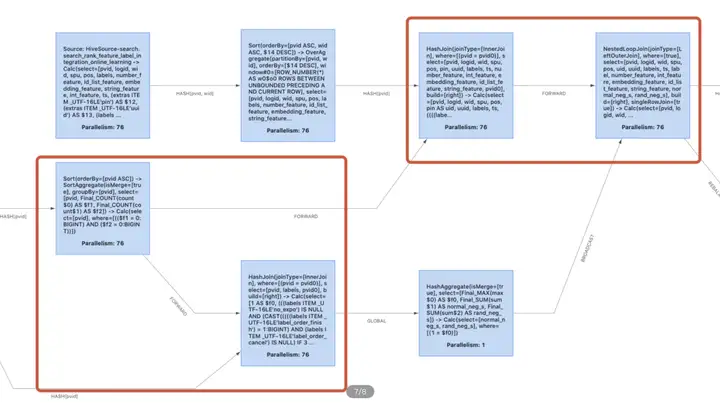
在 Flink SQL 任务里,降低 shuffle 可以有效的提高 SQL 任务的吞吐量,在实际的业务场景中经常遇到这样的情况:上游产出的数据已经满足了数据分布要求 (如连续多个 join 算子,其中 key 是相同的),此时 Flink 的 forward shuffle 是冗余的 shuffle,我们希望将这些算子 chain 到一起。Flink 1.12 引入了 mutiple input 的特性,可以消除大部分没必要的 forward shuffle,把 source 的算子 chain 到一起。
table.optimizer.multiple-input-enabled:true
下图为开了 multiple input 和没有开的拓扑图 ( operator chain 功能已经打开):
5. 对象重用
上下游 operator 之间会经过序列化 / 反序列化 / 复制阶段来进行数据传输,这种行为非常影响 Flink SQL 程序的性能,可以通过启用对象重用来提高性能。但是这在 DataStream 里面非常危险,因为可能会发生以下情况:在下一个算子中修改对象意外影响了上面算子的对象。
但是 Flink 的 Table / SQL API 中是非常安全的,可以通过如下方式来启用:
或者是通过设置:pipeline-object-reuse:true
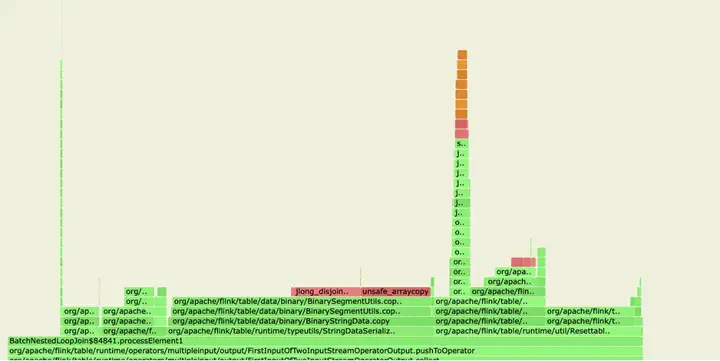
为什么启用了对象重用会有这么大的性能提升?在 Blink planner 中,同一任务的两个算子之间的数据交换最终将调用 BinaryString#copy,查看实现代码,可以发现 BinaryString#copy 需要复制底层 MemorySegment 的字节,通过启用对象重用来避免复制,可以有效提升效率。
下图为没有开启对象重用时相应的火焰图:
6. SQL 任务的 failover 策略
batch 任务模式下 checkpoint 以及其相关的特性全部都不可用,因此针对实时任务的基于 checkpoint 的 failover 策略是不能应用在批任务上面的,但是 batch 任务允许 Task 之间通过 Blocking Shuffle 进行通信,当一个 Task 因为任务未知的原因失败之后,由于 Blocking Shuffle 中存储了这个 Task 所需要的全部数据,所以只需要重启这个 Task 以及通过 Pipeline Shuffle 与其相连的全部下游任务即可:
jobmanager.execution.failover-strategy:region (已经 finish 的 operator 可直接恢复)
table.exec.shuffle-mode:ALL_EDGES_BLOCKING (shuffle 策略)。
7. shuffle
Flink 里的 shuffle 分为 pipeline shuffle 和 blocking shuffle。
pipeline shuffle 性能好,但是对资源的要求高,而且容错比较差 (会将该 operator 分到前面的一个 region 里面,对于 batch 任务来说,如果这个算子出问题,将从上一个 region 恢复);blocking shuffle 就是传统的 batch shuffle,会将数据落盘,这种 shuffle 的容错好,但是会产生大量的磁盘、网络 io (如果为了省心的话,建议用 blocking suffle)。blocking shuffle 又分为 hash shuffle 和 sort shuffle,如果你的磁盘是 ssd 并且并发不太大的话,可以选择使用 hash shuffle,这种 shuffle 方式产生的文件多、随机读多,对磁盘 io 影响较大;如果你是 sata 并且并发比较大,可以选择用 sort-merge shuffle,这种 shuffle 产生的数据少,顺序读,不会产生大量的磁盘 io,不过开销会更大一些 (sort merge)。相应的控制参数:
table.exec.shuffle-mode,该参数有多个参数,默认是 ALL_EDGES_BLOCKING,表示所有的边都会用 blocking shuffle,不过大家可以试一下 POINTWISE_EDGES_PIPELINED,表示 forward 和 rescale edges 会自动开始 pipeline 模式。
taskmanager.network.sort-shuffle.min-parallelism ,将这个参数设置为小于你的并行度,就可以开启 sort-merge shuffle;这个参数的设置需要考虑一些其他的情况,具体的可以按照官网设置。
三、总结
本文着重从 shuffle、join 方式的选择、对象重用、UDF 重用等方面介绍了京东在 Flink SQL 任务方面做的优化措施。另外,感谢京东实时计算研发部付海涛等全部同事的支持与帮助。
原文链接
本文为阿里云原创内容,未经允许不得转载。



















暂无评论内容