
1章、安装
简单介绍一下:这玩意功能和C/C++差不多,但是使用更加方便高效,很多硬件,WEB,服务端都可以用。总之就是更优越。
https://www.rust-lang.org/zh-CN/learn/get-started 下载安装

Cargo:Rust 的构建工具和包管理器
跟maven作用差不多,在安装 Rustup 时,也会安装 Rust 构建工具和包管理器的最新稳定版,即 Cargo。Cargo 可以做很多事情:
cargo build 可以构建项目cargo run 可以运行项目cargo test 可以测试项目cargo doc 可以为项目构建文档cargo publish 可以将库发布到 crates.io。要检查您是否安装了 Rust 和 Cargo,可以在终端中运行:
cargo –version 要创建一个新项目,进入第一章中创建的 projects 目录,使用 Cargo 新建一个项目,如下:
第一个命令,cargo new,它获取项目的名称(guessing_game)作为第一个参数。第二个命令进入到新创建的项目目录。
看看生成的 Cargo.toml 文件:作用跟Springboot中的Pom.xml文件差不多
文件名: Cargo.toml
正如第一章那样,cargo new 生成了一个 “Hello, world!” 程序。查看 src/main.rs 文件:
文件名: src/main.rs
现在使用 cargo run 命令,一步完成 “Hello, world!” 程序的编译和运行:
当你需要在项目中快速迭代时,run 命令就能派上用场,正如我们在这个游戏项目中做的,在下一次迭代之前快速测试每一次迭代。
重新打开 src/main.rs 文件。我们将会在这个文件中编写全部的代码。
2章、写代码
猜猜看程序的第一部分请求和处理用户输入,并检查输入是否符合预期的格式。首先,允许玩家输入猜测。在 src/main.rs 中输入示例 2-1 中的代码。
文件名: src/main.rs
运行如下
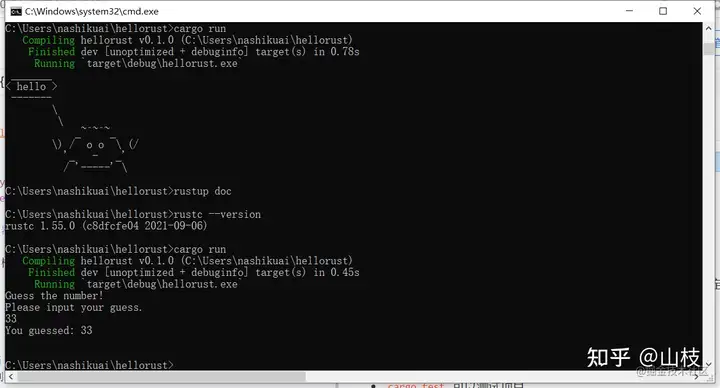
这些代码包含很多信息,我们一行一行地过一遍。为了获取用户输入并打印结果作为输出,我们需要将 io(输入/输出)库引入当前作用域。io 库来自于标准库(也被称为 std):
默认情况下,Rust 将 prelude 模块中少量的类型引入到每个程序的作用域中。如果需要的类型不在 prelude 中,你必须使用 use 语句显式地将其引入作用域。std::io 库提供很多有用的功能,包括接收用户输入的功能。
如第一章所提及,main 函数是程序的入口点:
fn 语法声明了一个新函数,() 表明没有参数,{ 作为函数体的开始。
第一章也提及了 println! 是一个在屏幕上打印字符串的宏:
这些代码仅仅打印提示,介绍游戏的内容然后请求用户输入。
let 与 mut
接下来,创建一个储存用户输入的地方,像这样:
现在程序开始变得有意思了!这一小行代码发生了很多事。注意这是一个 let 语句,用来创建 变量(variable)。这里是另外一个例子:
这行代码新建了一个叫做 apples 的变量并把它绑定到值 5 上。在 Rust 中,变量默认是不可变的。下面的例子展示了如何在变量名前使用 mut 来使一个变量可变:
让我们回到猜猜看程序中。现在我们知道了 let mut guess 会引入一个叫做 guess 的可变变量。等号(=)的右边是 guess 所绑定的值,它是 String::new 的结果,这个函数会返回一个 String 的新实例。String 是一个标准库提供的字符串类型,它是 UTF-8 编码的可增长文本块。
::new 那一行的 :: 语法表明 new 是 String 类型的一个 关联函数(associated function)。关联函数是针对类型实现的,在这个例子中是 String。
new 函数创建了一个新的空字符串,你会发现很多类型上有 new 函数,因为它是创建类型实例的惯用函数名。
总结一下,let mut guess = String::new(); 这一行创建了一个可变变量,当前它绑定到一个新的 String 空实例上。
回忆一下,我们在程序的第一行使用 use std::io; 从标准库中引入了输入/输出功能。现在调用 io 库中的函数 stdin:
如果程序的开头没有 use std::io 这一行,可以把函数调用写成 std::io::stdin。stdin 函数返回一个 std::io::Stdin 的实例,这代表终端标准输入句柄的类型。
代码的下一部分,.read_line(&mut guess),调用 read_line 方法从标准输入句柄获取用户输入。我们还向 read_line() 传递了一个参数:&mut guess。
read_line 的工作是接收用户在标准输入中输入的任何内容,并将其追加到一个字符串中(不覆盖其内容),因此它将该字符串作为参数。这个字符串参数需要是可变的,以便该方法可以通过添加用户输入来改变字符串的内容。
& 表示这个参数是一个 引用(reference),它允许多处代码访问同一处数据,而无需在内存中多次拷贝。引用是一个复杂的特性,Rust 的一个主要优势就是安全而简单的操纵引用。完成当前程序并不需要了解如此多细节。现在,我们只需知道它像变量一样,默认是不可变的。因此,需要写成 &mut guess 来使其可变,而不是 &guess。
使用 Result 抛出错误
我们还没有完全分析完这行代码。虽然这是单独一行代码,但它是逻辑行(虽然换行了但仍是语句)的一部分。后一部分是这个方法:
当使用 .method_name() 语法调用方法时,通过换行加缩进来把长行拆开是明智的。我们完全可以这样写:
不过,过长的行难以阅读,所以最好拆开来写,两个方法调用占两行。现在来看看这行代码干了什么。
之前提到了 read_line 将用户输入附加到传递给它的字符串中,不过它也返回一个值——在这个例子中是 io::Result。Rust 标准库中有很多叫做 Result 的类型:一个通用的 Result 以及在子模块中的特化版本,比如 io::Result。
Result 类型是 枚举(enumerations),通常也写作 enums。枚举类型持有固定集合的值,这些值被称为枚举的 成员(variants)。第六章将介绍枚举的更多细节。
Result 的成员是 Ok 和 Err,Ok 成员表示操作成功,内部包含成功时产生的值。Err 成员则意味着操作失败,并且包含失败的前因后果。
这些 Result 类型的作用是编码错误处理信息。Result 类型的值,像其他类型一样,拥有定义于其上的方法。io::Result 的实例拥有 expect 方法。如果 io::Result 实例的值是 Err,expect 会导致程序崩溃,并显示当做参数传递给 expect 的信息。如果 read_line 方法返回 Err,则可能是来源于底层操作系统错误的结果。如果 io::Result 实例的值是 Ok,expect 会获取 Ok 中的值并原样返回。在本例中,这个值是用户输入到标准输入中的字节数。
如果不调用 expect,程序也能编译,不过会出现一个警告:
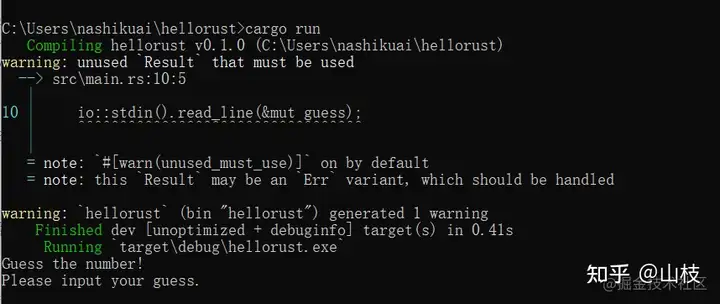
Rust 警告我们没有使用 read_line 的返回值 Result,说明有一个可能的错误没有处理。
消除警告的正确做法是实际编写错误处理代码,不过由于我们就是希望程序在出现问题时立即崩溃,所以直接使用 expect。第九章会学习如何从错误中恢复。
使用 println! 占位符打印值
除了位于结尾的右花括号,目前为止就只有这一行代码值得讨论一下了,就是这一行:
这行代码打印存储用户输入的字符串。第一个参数是格式化字符串,里面的 {} 是预留在特定位置的占位符。使用 {} 也可以打印多个值:第一对 {} 使用格式化字符串之后的第一个值,第二对则使用第二个值,依此类推。调用一次 println! 打印多个值看起来像这样:
这行代码会打印出 x = 5 and y = 10。
使用 crate 来增加更多功能
crate 可看成静态链接库
rand crate 可看成动态链接库
记住,crate 是一个 Rust 代码包。我们正在构建的项目是一个 二进制 crate,它生成一个可执行文件。 rand crate 是一个 库 crate,库 crate 可以包含任意能被其他程序使用的代码。
Cargo 对外部 crate 的运用是其真正的亮点所在。在我们使用 rand 编写代码之前,需要修改 Cargo.toml 文件,引入一个 rand 依赖。现在打开这个文件并将下面这一行添加到 [dependencies] 片段标题之下。请确保按照我们这里的方式指定 rand,否则本教程中的代码示例可能无法工作。
文件名: Cargo.toml
现在,不修改任何代码,构建项目 cargo build
生成一个随机数
你已经把 rand crate 添加到 Cargo.toml 了,让我们开始使用 rand。下一步是更新 src/main.rs,如示例 2-3 所示。
文件名: src/main.rs
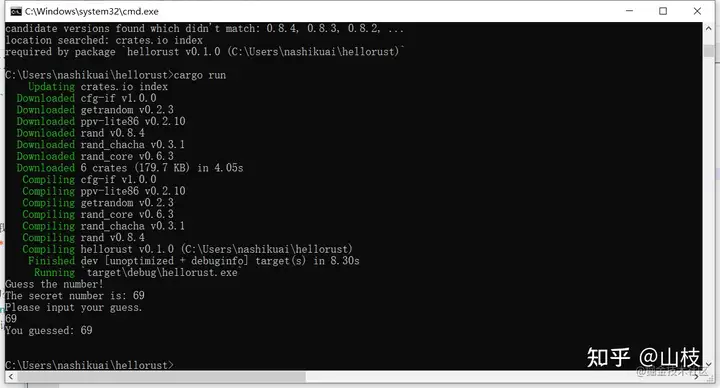
首先,我们新增了一行 use:use rand::Rng。Rng 是一个 trait,它定义了随机数生成器应实现的方法,想使用这些方法的话,此 trait 必须在作用域中。第十章会详细介绍 trait。
接下来,我们在中间还新增加了两行。rand::thread_rng 函数提供实际使用的随机数生成器:它位于当前执行线程的本地环境中,并从操作系统获取 seed。接下来,调用随机数生成器的 gen_range 方法。这个方法由刚才引入到作用域的 Rng trait 定义。gen_range 方法接受一个范围表达式作为参数,并在该范围内生成一个随机数。我们在这里使用的范围表达式采用 start..end 形式,它包含下限但不包含上限,所以需要指定 1..101 来请求一个 1 和 100 之间的数。另外,我们也可以传递 1..=100,这是等价的。
使用循环来允许多次猜测
文件名: src/main.rs
新代码的第一行是另一个 use,从标准库引入了一个叫做 std::cmp::Ordering 的类型。同 Result 一样, Ordering 也是一个枚举,不过它的成员是 Less、Greater 和 Equal。这是比较两个值时可能出现的三种结果。
接着,底部的五行新代码使用了 Ordering 类型,cmp 方法用来比较两个值并可以在任何可比较的值上调用。它获取一个被比较值的引用:这里是把 guess 与 secret_number 做比较。 然后它会返回一个刚才通过 use 引入作用域的 Ordering 枚举的成员。使用一个 match 表达式,根据对 guess 和 secret_number 调用 cmp 返回的 Ordering 成员来决定接下来做什么。
一个 match 表达式由 分支(arms) 构成。一个分支包含一个 模式(pattern)和表达式开头的值与分支模式相匹配时应该执行的代码。Rust 获取提供给 match 的值并挨个检查每个分支的模式。match 结构和模式是 Rust 中强大的功能,它体现了代码可能遇到的多种情形,并帮助你确保没有遗漏处理。这些功能将分别在第六章和第十八章详细介绍。
让我们看看使用 match 表达式的例子。假设用户猜了 50,这时随机生成的秘密数字是 38。比较 50 与 38 时,因为 50 比 38 要大,cmp 方法会返回 Ordering::Greater。Ordering::Greater 是 match 表达式得到的值。它检查第一个分支的模式,Ordering::Less 与 Ordering::Greater并不匹配,所以它忽略了这个分支的代码并来到下一个分支。下一个分支的模式是 Ordering::Greater,正确 匹配!这个分支关联的代码被执行,在屏幕打印出 Too big!。match 表达式就此终止,因为该场景下没有检查最后一个分支的必要。 通过在 You win! 之后增加一行 break,用户猜对了神秘数字后会退出循环。退出循环也意味着退出程序,因为循环是 main 的最后一部分。
总结
此时此刻,你顺利完成了猜猜看游戏。恭喜!
本项目通过动手实践,向你介绍了 Rust 新概念:let、match、方法、函数、使用外部 crate 等等,接下来的几章,你会继续深入学习这些概念。第三章介绍大部分编程语言都有的概念,比如变量、数据类型和函数,以及如何在 Rust 中使用它们。第四章探索所有权(ownership),这是一个 Rust 同其他语言大不相同的功能。第五章讨论结构体和方法的语法,而第六章侧重解释枚举。
3章、变量、数据类型和控制流
此章我们将会学习变量、基本类型、函数、注释和控制流。每一个 Rust 程序中都会用到这些基础知识,提早学习这些概念会让你在起步时就打下坚实的基础。
变量与常量
变量默认是不可改变的(immutable)不过可变性也是非常有用的。变量只是默认不可变;正如在第二章所做的那样,你可以在变量名之前加 mut 来使其可变。除了允许改变值之外,mut 向读者表明了其他代码将会改变这个变量值的意图。
首先,不允许对常量使用 mut。常量不光默认不能变,它总是不能变。 声明常量使用 const 关键字而不是 let,并且 必须 注明值的类型。 下面是一个声明常量的例子,常量的名称是 HREE_HOURS_IN_SECONDS,它的值被设置为 60(一分钟内的秒数)乘以 60(一小时内的分钟数)再乘以 3(我们在这个程序中要计算的小时数)的结果:
Rust 对常量的命名约定是在单词之间使用全大写加下划线。
变量覆盖
可以用相同变量名称来隐藏一个变量,以及重复使用 let 关键字来多次隐藏,如下所示:
文件名: src/main.rs
这个程序首先将 x 绑定到值 5 上。接着通过 let x = 隐藏 x,获取初始值并加 1,这样 x 的值就变成 6 了。然后,在内部作用域内,第三个 let 语句也隐藏了 x,将之前的值乘以 2,x 得到的值是 12。当该作用域结束时,内部 shadowing 的作用域也结束了,x 又返回到 6。运行这个程序,它会有如下输出:

覆盖与将变量标记为 mut 是有区别的。当不小心尝试对变量重新赋值时,如果没有使用 let 关键字,就会导致编译时错误。通过使用 let,我们可以用这个值进行一些计算,不过计算完之后变量仍然是不可变的。 mut 与覆盖的另一个区别是,当再次使用 let 时,实际上创建了一个新变量,我们可以改变值的类型,但复用这个名字。例如,假设程序请求用户输入空格字符来说明希望在文本之间显示多少个空格,然而我们真正需要的是将输入存储成数字(多少个空格):
这里允许第一个 spaces 变量是字符串类型,而第二个 spaces 变量,它是一个恰巧与第一个变量同名的崭新变量,是数字类型。覆盖使我们不必使用不同的名字,如 spaces_str 和 spaces_num;相反,我们可以复用 spaces 这个更简单的名字。然而,如果尝试使用 mut,将会得到一个编译时错误,如下所示:
这个错误说明,我们不能改变变量的类型:

数据类型
rust 分两种数据大类,两类数据类型子集:标量(scalar)和复合(compound)
标量类型
标量(scalar)类型代表一个单独的值。Rust 有四种基本的标量类型:整型、浮点型、布尔类型和字符类型。你可能在其他语言中见过它们。让我们深入了解它们在 Rust 中是如何工作的。
整型
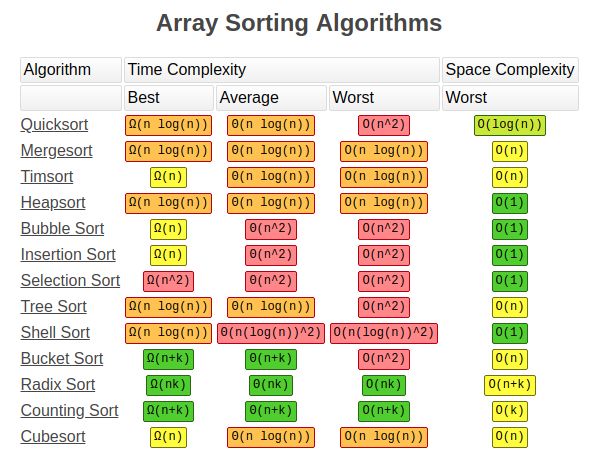
整数 是一个没有小数部分的数字。我们在第二章使用过 u32 整数类型。该类型声明表明,它关联的值应该是一个占据 32 比特位的无符号整数(有符号整数类型以 i 开头而不是 u)。表格 3-1 展示了 Rust 内建的整数类型。在有符号列和无符号列中的每一个变体(例如,i16)都可以用来声明整数值的类型。
表格 3-1: Rust 中的整型
| 长度 | 有符号 | 无符号 |
| | 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| arch | isize | usize |
每一个变体都可以是有符号或无符号的,并有一个明确的大小。有符号 和 无符号 代表数字能否为负值,换句话说,这个数字是否有可能是负数(有符号数),或者永远为正而不需要符号(无符号数)。这有点像在纸上书写数字:当需要考虑符号的时候,数字以加号或减号作为前缀;然而,可以安全地假设为正数时,加号前缀通常省略。有符号数以补码形式(two’s complement representation) 存储。
每一个有符号的变体可以储存包含从 -(2n – 1) 到 2n – 1 – 1 在内的数字,这里 n 是变体使用的位数。所以 i8 可以储存从 -(27) 到 27 – 1 在内的数字,也就是从 -128 到 127。无符号的变体可以储存从 0 到 2n – 1 的数字,所以 u8 可以储存从 0 到 28 – 1 的数字,也就是从 0 到 255。
另外,isize 和 usize 类型依赖运行程序的计算机架构:64 位架构上它们是 64 位的, 32 位架构上它们是 32 位的。
可以使用表格 3-2 中的任何一种形式编写数字字面值。请注意可以是多种数字类型的数字字面值允许使用类型后缀,例如 57u8 来指定类型,同时也允许使用 _ 做为分隔符以方便读数,例如1_000,它的值与你指定的 1000 相同。
表格 3-2: Rust 中的整型字面值
| 数字字面值 | 例子 |
| ——————— | ————- |
| Decimal (十进制) | 98_222 |
| Hex (十六进制) | 0xff |
| Octal (八进制) | 0o77 |
| Binary (二进制) | 0b1111_0000 |
| Byte (单字节字符)(仅限于u8) | bA |
那么该使用哪种类型的数字呢?如果拿不定主意,Rust 的默认类型通常是个不错的起点,数字类型默认是 i32。isize 或 usize 主要作为某些集合的索引。
浮点型
Rust 也有两个原生的 浮点数(floating-point numbers)类型,它们是带小数点的数字。Rust 的浮点数类型是 f32 和 f64,分别占 32 位和 64 位。默认类型是 f64,因为在现代 CPU 中,它与 f32 速度几乎一样,不过精度更高。
这是一个展示浮点数的实例:
文件名: src/main.rs
浮点数采用 IEEE-754 标准表示。f32 是单精度浮点数,f64 是双精度浮点数。
数值运算
Rust 中的所有数字类型都支持基本数学运算:加法、减法、乘法、除法和取余。整数除法会向下舍入到最接近的整数。下面的代码展示了如何在 let 语句中使用它们:
文件名: src/main.rs
这些语句中的每个表达式使用了一个数学运算符并计算出了一个值,然后绑定给一个变量。
包含 Rust 提供的所有运算符的列表。
布尔型
正如其他大部分编程语言一样,Rust 中的布尔类型有两个可能的值:true 和 false。Rust 中的布尔类型使用 bool 表示。例如:
文件名: src/main.rs
使用布尔值的主要场景是条件表达式,例如 if 表达式。在 “控制流”(“Control Flow”) 部分将介绍 if 表达式在 Rust 中如何工作。
字符类型
目前为止只使用到了数字,不过 Rust 也支持字母。Rust 的 char 类型是语言中最原生的字母类型,如下代码展示了如何使用它。(注意 char 由单引号指定,不同于字符串使用双引号。)
文件名: src/main.rs
Rust 的 char 类型的大小为四个字节(four bytes),并代表了一个 Unicode 标量值(Unicode Scalar Value),这意味着它可以比 ASCII 表示更多内容。在 Rust 中,拼音字母(Accented letters),中文、日文、韩文等字符,emoji(绘文字)以及零长度的空白字符都是有效的 char 值。Unicode 标量值包含从 U+0000 到 U+D7FF 和 U+E000 到 U+10FFFF 在内的值。不过,“字符” 并不是一个 Unicode 中的概念,所以人直觉上的 “字符” 可能与 Rust 中的 char 并不符合。
复合类型
复合类型(Compound types)可以将多个值组合成一个类型。Rust 有两个原生的复合类型:元组(tuple)和数组(array)。
元组类型
元组是一个将多个其他类型的值组合进一个复合类型的主要方式。元组长度固定:一旦声明,其长度不会增大或缩小。 文件名: src/main.rs
tup 变量绑定到整个元组上,因为元组是一个单独的复合元素。为了从元组中获取单个值,可以使用模式匹配(pattern matching)来解构(destructure)元组值,像这样:
文件名: src/main.rs
程序首先创建了一个元组并绑定到 tup 变量上。接着使用了 let 和一个模式将 tup 分成了三个不同的变量,x、y 和 z。这叫做 解构(destructuring),因为它将一个元组拆成了三个部分。最后,程序打印出了 y 的值,也就是 6.4。
除了使用模式匹配解构外,也可以使用点号(.)后跟值的索引来直接访问它们。例如:
文件名: src/main.rs
这个程序创建了一个元组,x,并接着使用索引为每个元素创建新变量。跟大多数编程语言一样,元组的第一个索引值是 0。
没有任何值的元组 () 是一种特殊的类型,只有一个值,也写成 () 。该类型被称为 单元类型(unit type),而该值被称为 单元值(unit value)。如果表达式不返回任何其他值,则会隐式返回单元值。
数组类型
另一个包含多个值的方式是 数组(array)。与元组不同,数组中的每个元素的类型必须相同。Rust 中的数组与一些其他语言中的数组不同,因为 Rust 中的数组是固定长度的:一旦声明,它们的长度不能增长或缩小。
Rust 中,数组中的值位于中括号内的逗号分隔的列表中:
文件名: src/main.rs
一个你可能想要使用数组而不是 vector 的例子是,当程序需要知道一年中月份的名字时。程序不大可能会去增加或减少月份。这时你可以使用数组,因为我们知道它总是包含 12 个元素:
可以像这样编写数组的类型:在方括号中包含每个元素的类型,后跟分号,再后跟数组元素的数量。
这里,i32 是每个元素的类型。分号之后,数字 5 表明该数组包含五个元素。
以这种方式编写数组的类型看起来类似于初始化数组的另一种语法:如果要为每个元素创建包含相同值的数组,可以指定初始值,后跟分号,然后在方括号中指定数组的长度,如下所示:
变量名为 a 的数组将包含 5 个元素,这些元素的值最初都将被设置为 3。这种写法与 let a = [3, 3, 3, 3, 3]; 效果相同,但更简洁。
访问数组元素
数组是可以在堆栈上分配的已知固定大小的单个内存块。可以使用索引来访问数组的元素,像这样:
文件名: src/main.rs
在这个例子中,叫做 first 的变量的值是 1,因为它是数组索引 [0] 的值。变量 second 将会是数组索引 [1] 的值 2。
无效的数组元素访问
如果我们访问数组结尾之后的元素会发生什么呢?比如你将上面的例子改成下面这样,它使用类似于第 2 章中的猜数字游戏的代码从用户那里获取数组索引:
文件名: src/main.rs
此代码编译成功。如果您使用 cargo run 运行此代码并输入 0、1、2、3 或 4,程序将在数组中的索引处打印出相应的值。如果你输入一个超过数组末端的数字,如 10,你会看到这样的输出错误
函数
fn 关键字,它用来声明新函数
Rust 代码中的函数和变量名使用 snake case 规范风格。在 snake case 中,所有字母都是小写并使用下划线分隔单词。这是一个包含函数定义示例的程序:
文件名: src/main.rs
Rust 中的函数定义以 fn 开始并在函数名后跟一对圆括号。大括号告诉编译器哪里是函数体的开始和结尾。
函数参数:
声明中有一个命名为 x 的参数。x 的类型被指定为 i32。当将 5 传给 another_function 时,println! 宏将 5 放入格式化字符串中大括号的位置。在函数签名中,必须 声明每个参数的类型。当一个函数有多个参数时,使用逗号分隔。
这与其他语言不同,例如 C 和 Ruby,它们的赋值语句会返回所赋的值。在这些语言中,可以这么写 x = y = 6,这样 x 和 y 的值都是 6;Rust 中不能这样写。
表达式
函数中可以使用表达式,表达式会计算出一个值
这个表达式:
是一个代码块,它的值是 4。这个值作为 let 语句的一部分被绑定到 y 上。
具有返回值的函数
函数可以向调用它的代码返回值。我们并不对返回值命名,但要在箭头(->)后声明它的类型。在 Rust 中,函数的返回值等同于函数体最后一个表达式的值。使用 return 关键字和指定值,可从函数中提前返回;但大部分函数隐式的返回最后的表达式。这是一个有返回值的函数的例子:
文件名: src/main.rs
在 five 函数中没有函数调用、宏、甚至没有 let 语句——只有数字 5。这在 Rust 中是一个完全有效的函数。注意,也指定了函数返回值的类型,就是 -> i32。
five 函数的返回值是 5,所以返回值类型是 i32。让我们仔细检查一下这段代码。有两个重要的部分:首先,let x = five(); 这一行表明我们使用函数的返回值初始化一个变量。因为 five 函数返回 5,这一行与如下代码相同:
其次,five 函数没有参数并定义了返回值类型,不过函数体只有单单一个 5 也没有分号,因为这是一个表达式,我们想要返回它的值。
让我们看看另一个例子:
文件名: src/main.rs
运行代码会打印出 The value of x is: 6。但如果在包含 x + 1 的行尾加上一个分号,把它从表达式变成语句,我们将看到一个错误。
关于注释:这是一个简单的注释:
控制流
Rust 代码中最常见的用来控制执行流的结构是 if 表达式和循环。
if 表达式
文件名: src/main.rs
所有的 if 表达式都以 if 关键字开头,其后跟一个条件。
使用 else if 处理多重条件
可以将 else if 表达式与 if 和 else 组合来实现多重条件。例如:
文件名: src/main.rs
这个程序有四个可能的执行路径。
在 let 语句中使用 if
因为 if 是一个表达式,我们可以在 let 语句的右侧使用它,例如在示例 3-2 中:
文件名: src/main.rs
示例 3-2:将 if 表达式的返回值赋给一个变量
number 变量将会绑定到表示 if 表达式结果的值上。运行输出:
记住,代码块的值是其最后一个表达式的值,而数字本身就是一个表达式。在这个例子中,整个 if 表达式的值取决于哪个代码块被执行。这意味着 if 的每个分支的可能的返回值都必须是相同类型;
使用循环重复执行
多次执行同一段代码是很常用的,Rust 为此提供了多种 循环(loops)。一个循环执行循环体中的代码直到结尾并紧接着回到开头继续执行。为了实验一下循环,让我们新建一个叫做 loops 的项目。
Rust 有三种循环:loop、while 和 for。我们每一个都试试。
使用 loop 重复执行代码
loop 关键字告诉 Rust 一遍又一遍地执行一段代码直到你明确要求停止。
文件名: src/main.rs
当运行这个程序时,我们会看到连续的反复打印 again!,直到我们手动停止程序。大部分终端都支持一个快捷键,ctrl-c,来终止一个陷入无限循环的程序。
continue:跳过本次循环后续,进行下一循环
break:跳出循环
如果存在嵌套循环,break 和 continue 应用于此时最内层的循环。你可以选择在一个循环上指定一个 循环标签(loop label),然后将标签与 break 或 continue 一起使用,使这些关键字应用于已标记的循环而不是最内层的循环。下面是一个包含两个嵌套循环的示例
外层循环有一个标签 counting_ up,它将从 0 数到 2。没有标签的内部循环从 10 向下数到 9。第一个没有指定标签的 break 将只退出内层循环。breakcounting_up; 语句将退出外层循环。这个代码打印:

从循环返回
loop 的一个用例是重试可能会失败的操作,比如检查线程是否完成了任务。然而你可能会需要将操作的结果传递给其它的代码。如果将返回值加入你用来停止循环的 break 表达式,它会被停止的循环返回:
在循环之前,我们声明了一个名为 counter 的变量并初始化为 0。接着声明了一个名为 result 来存放循环的返回值。在循环的每一次迭代中,我们将 counter 变量加 1,接着检查计数是否等于 10。当相等时,使用 break 关键字返回值 counter * 2。循环之后,我们通过分号结束赋值给 result 的语句。最后打印出 result 的值,也就是 20。
while 条件循环
在程序中计算循环的条件也很常见。当条件为真,执行循环。当条件不再为真,调用 break 停止循环。这个循环类型可以通过组合 loop、if、else 和 break 来实现;如果你喜欢的话,现在就可以在程序中试试。
然而,这个模式太常用了,Rust 为此内置了一个语言结构,它被称为 while 循环。示例 3-3 使用了 while:程序循环三次,每次数字都减一。接着,在循环结束后,打印出另一个信息并退出。
文件名: src/main.rs
示例 3-3: 当条件为真时,使用 while 循环运行代码
这种结构消除了很多使用 loop、if、else 和 break 时所必须的嵌套,这样更加清晰。当条件为真就执行,否则退出循环。
使用 for 遍历集合
可以使用 while 结构来遍历集合中的元素,比如数组。例如,看看示例 3-4。
文件名: src/main.rs
示例 3-4:使用 while 循环遍历集合中的元素
这里,代码对数组中的元素进行计数。它从索引 0 开始,并接着循环直到遇到数组的最后一个索引(这时,index < 5 不再为真)。
数组中的所有五个元素都如期被打印出来。尽管 index 在某一时刻会到达值 5,不过循环在其尝试从数组获取第六个值(会越界)之前就停止了。
但这个过程很容易出错;如果索引长度或测试条件不正确会导致程序 panic。这也使程序更慢,因为编译器增加了运行时代码来对每次循环进行条件检查,以确定在循环的每次迭代中索引是否在数组的边界内。
作为更简洁的替代方案,可以使用 for 循环来对一个集合的每个元素执行一些代码。for 循环看起来如示例 3-5 所示:
文件名: src/main.rs
示例 3-5:使用 for 循环遍历集合中的元素
当运行这段代码时,将看到与示例 3-4 一样的输出。更为重要的是,我们增强了代码安全性,并消除了可能由于超出数组的结尾或遍历长度不够而缺少一些元素而导致的 bug。
例如,在示例 3-4 的代码中,如果你将 a 数组的定义改为有四个元素,但忘记将条件更新为 while index < 4,代码将会 panic。使用 for 循环的话,就不需要惦记着在改变数组元素个数时修改其他的代码了。
for 循环的安全性和简洁性使得它成为 Rust 中使用最多的循环结构。即使是在想要循环执行代码特定次数时,例如示例 3-3 中使用 while 循环的倒计时例子,大部分 Rustacean 也会使用 for 循环。这么做的方式是使用 Range,它是标准库提供的类型,用来生成从一个数字开始到另一个数字之前结束的所有数字的序列。
下面是一个使用 for 循环来倒计时的例子,它还使用了一个我们还未讲到的方法,rev,用来反转 range:
文件名: src/main.rs
这段代码看起来更帅气不是吗?
总结
你做到了!这是一个大章节:你学习了变量、标量和复合数据类型、函数、注释、 if 表达式和循环!如果你想要实践本章讨论的概念,尝试构建如下程序:
相互转换摄氏与华氏温度。生成 n 阶斐波那契数列。打印圣诞颂歌 “The Twelve Days of Christmas” 的歌词,并利用歌曲中的重复部分(编写循环)。当你准备好继续的时候,让我们讨论一个其他语言中 并不 常见的概念:所有权(ownership)。
4章、所有权
所有权(系统)是 Rust 最为与众不同的特性,它让 Rust 无需垃圾回收(garbage collector)即可保障内存安全。因此,理解 Rust 中所有权如何工作是十分重要的。本章,我们将讲到所有权以及相关功能:借用、slice 以及 Rust 如何在内存中布局数据。
Rust 的核心功能(之一)是 所有权(ownership)。所有运行的程序都必须管理其使用计算机内存的方式。一些语言中具有垃圾回收机制,在程序运行时不断地寻找不再使用的内存;在另一些语言中,程序员必须亲自分配和释放内存。Rust 则选择了第三种方式:通过所有权系统管理内存,编译器在编译时会根据一系列的规则进行检查。在运行时,所有权系统的任何功能都不会减慢程序。当你理解了所有权,你将有一个坚实的基础来理解那些使 Rust 独特的功能。
想象一下去餐馆就座吃饭。当进入时,你说明有几个人,餐馆员工会找到一个够大的空桌子并领你们过去。如果有人来迟了,他们也可以通过询问来找到你们坐在哪。
入栈比在堆上分配内存要快,因为(入栈时)操作系统无需为存储新数据去搜索内存空间;其位置总是在栈顶。相比之下,在堆上分配内存则需要更多的工作,这是因为操作系统必须首先找到一块足够存放数据的内存空间,并接着做一些记录为下一次分配做准备。
访问堆上的数据比访问栈上的数据慢,因为必须通过指针来访问。现代处理器在内存中跳转越少就越快(缓存)。
继续类比,假设有一个服务员在餐厅里处理多个桌子的点菜。在一个桌子报完所有菜后再移动到下一个桌子是最有效率的。从桌子 A 听一个菜,接着桌子 B 听一个菜,然后再桌子 A,然后再桌子 B 这样的流程会更加缓慢。(请想象指针跳来跳去)出于同样原因,处理器在处理的数据彼此较近的时候(比如在栈上)比较远的时候(比如可能在堆上)能更好的工作。在堆上分配大量的空间也可能消耗时间。
当你的代码调用一个函数时,传递给函数的值(包括可能指向堆上数据的指针)和函数的局部变量被压入栈中。当函数结束时,这些值被移出栈。
跟踪哪部分代码正在使用堆上的哪些数据,最大限度的减少堆上的重复数据的数量,以及清理堆上不再使用的数据确保不会耗尽空间,这些问题正是所有权系统要处理的。 一旦理解了所有权,你就不需要经常考虑栈和堆了,不过明白了所有权的存在就是为了管理堆数据,能够帮助解释为什么所有权要以这种方式工作。
所有权规则
首先,让我们看一下所有权的规则。当我们通过举例说明时,请谨记这些规则:
Rust 中的每一个值都有一个被称为其 所有者(owner)的变量。值在任一时刻有且只有一个所有者。当所有者(变量)离开作用域,这个值将被丢弃。 这三个规则有没有感觉像springboot中的约定大于配置的感觉,嗯 ,大概就是自助餐那个感觉。变量作用域
在所有权的第一个例子中,我们看看一些变量的 作用域(scope)。作用域是一个项(item)在程序中有效的范围。假设有这样一个变量:
变量 s 绑定到了一个字符串字面值,这个字符串值是硬编码进程序代码中的。这个变量从声明的点开始直到当前 作用域 结束时都是有效的。示例 4-1 的注释标明了变量 s 在何处是有效的。
示例 4-1:一个变量和其有效的作用域 换句话说,这里有两个重要的时间点:
当 s 进入作用域 时,它就是有效的。这一直持续到它 离开作用域 为止。目前为止,变量是否有效与作用域的关系跟其他编程语言是类似的。现在我们在此基础上介绍 String 类型。 可以使用 from 函数基于字符串字面值来创建 String,如下:
这两个冒号(::)是运算符,允许将特定的 from 函数置于 String 类型的命名空间(namespace)下,而不需要使用类似 string_from 这样的名字。 可以 修改此类字符串 :
内存与分配
对于 String 类型,为了支持一个可变,可增长的文本片段,需要在堆上分配一块在编译时未知大小的内存来存放内容。这意味着:
必须在运行时向操作系统请求内存。需要一个当我们处理完 String 时将内存返回给操作系统的方法。第一部分由我们完成:当调用 String::from 时,它的实现 (implementation) 请求其所需的内存。这在编程语言中是非常通用的。
然而,第二部分实现起来就各有区别了。在有 垃圾回收(garbage collector,GC)的语言中, GC 记录并清除不再使用的内存,而我们并不需要关心它。没有 GC 的话,识别出不再使用的内存并调用代码显式释放就是我们的责任了,跟请求内存的时候一样。从历史的角度上说正确处理内存回收曾经是一个困难的编程问题。如果忘记回收了会浪费内存。如果过早回收了,将会出现无效变量。如果重复回收,这也是个 bug。我们需要精确的为一个 allocate 配对一个 free。
Rust 采取了一个不同的策略:内存在拥有它的变量离开作用域后就被自动释放(离开自助餐厅就不能吃饭)。下面是示例 4-1 中作用域例子的一个使用 String 而不是字符串字面值的版本:
这是一个将 String 需要的内存返回给操作系统的很自然的位置:当 s 离开作用域的时候。当变量离开作用域,Rust 为我们调用一个特殊的函数。这个函数叫做 drop,在这里 String 的作者可以放置释放内存的代码。Rust 在结尾的 } 处自动调用 drop。
这个模式对编写 Rust 代码的方式有着深远的影响。现在它看起来很简单,不过在更复杂的场景下代码的行为可能是不可预测的,比如当有多个变量使用在堆上分配的内存时。现在让我们探索一些这样的场景。
变量与数据交互的方式(一):移动
在Rust 中,多个变量可以采取不同的方式与同一数据进行交互。让我们看看示例 4-2 中一个使用整型的例子。
示例 4-2:将变量 x 的整数值赋给 y
我们大致可以猜到这在干什么:“将 5 绑定到 x;接着生成一个值 x 的拷贝并绑定到 y”。现在有了两个变量,x 和 y,都等于 5。这也正是事实上发生了的,因为整数是有已知固定大小的简单值,所以这两个 5 被放入了栈中。
现在看看这个 String 版本:
这看起来与上面的代码非常类似,所以我们可能会假设他们的运行方式也是类似的:也就是说,第二行可能会生成一个 s1 的拷贝并绑定到 s2 上。不过,事实上并不完全是这样。
看看图 4-1 以了解 String 的底层会发生什么。String 由三部分组成,如图左侧所示:一个指向存放字符串内容内存的指针,一个长度,和一个容量。这一组数据存储在栈上。右侧则是堆上存放内容的内存部分。

图 4-1:将值 “hello” 绑定给 s1 的 String 在内存中的表现形式
长度表示 String 的内容当前使用了多少字节的内存。容量是 String 从操作系统总共获取了多少字节的内存。长度与容量的区别是很重要的,不过在当前上下文中并不重要,所以现在可以忽略容量。
当我们将 s1 赋值给 s2,String 的数据被复制了,这意味着我们从栈上拷贝了它的指针、长度和容量。我们并没有复制指针指向的堆上数据。换句话说,内存中数据的表现如图 4-2 所示。

图 4-2:变量 s2 的内存表现,它有一份 s1 指针、长度和容量的拷贝
这个表现形式看起来 并不像 图 4-3 中的那样,如果 Rust 也拷贝了堆上的数据,那么内存看起来就是这样的。如果 Rust 这么做了,那么操作 s2 = s1 在堆上数据比较大的时候会对运行时性能造成非常大的影响。

图 4-3:另一个 s2 = s1 时可能的内存表现,如果 Rust 同时也拷贝了堆上的数据的话
之前我们提到过当变量离开作用域后,Rust 自动调用 drop 函数并清理变量的堆内存。不过图 4-2 展示了两个数据指针指向了同一位置。这就有了一个问题:当 s2 和 s1 离开作用域,他们都会尝试释放相同的内存。这是一个叫做 二次释放(double free)的错误,也是之前提到过的内存安全性 bug 之一。两次释放(相同)内存会导致内存污染,它可能会导致潜在的安全漏洞。
为了确保内存安全,这种场景下 Rust 的处理有另一个细节值得注意。与其尝试拷贝被分配的内存,Rust 则认为 s1 不再有效,因此 Rust 不需要在 s1 离开作用域后清理任何东西。看看在 s2 被创建之后尝试使用 s1 会发生什么;这段代码不能运行:
你会得到一个类似如下的错误,因为 Rust 禁止你使用无效的引用。

如果你在其他语言中听说过术语 浅拷贝(shallow copy)和 深拷贝(deep copy),那么拷贝指针、长度和容量而不拷贝数据可能听起来像浅拷贝。不过因为 Rust 同时使第一个变量无效了,这个操作被称为 移动(move),而不是浅拷贝。上面的例子可以解读为 s1 被 移动 到了 s2 中。那么具体发生了什么,如图 4-4 所示。

图 4-4:s1 无效之后的内存表现
这样就解决了我们的问题!因为只有 s2 是有效的,当其离开作用域,它就释放自己的内存,完毕。
另外,这里还隐含了一个设计选择:Rust 永远也不会自动创建数据的 “深拷贝”。因此,任何 自动 的复制可以被认为对运行时性能影响较小。
变量与数据交互的方式(二):克隆
如果我们 确实 需要深度复制 String 中堆上的数据,而不仅仅是栈上的数据,可以使用一个叫做 clone 的通用函数。第五章会讨论方法语法,不过因为方法在很多语言中是一个常见功能,所以之前你可能已经见过了。
这是一个实际使用 clone 方法的例子:
这段代码能正常运行,并且明确产生图 4-3 中行为,这里堆上的数据 确实 被复制了。
当出现 clone 调用时,你知道一些特定的代码被执行而且这些代码可能相当消耗资源。你很容易察觉到一些不寻常的事情正在发生。
只在栈上的数据:拷贝
这里还有一个没有提到的小窍门。这些代码使用了整型并且是有效的,他们是示例 4-2 中的一部分:
但这段代码似乎与我们刚刚学到的内容相矛盾:没有调用 clone,不过 x 依然有效且没有被移动到 y 中。
原因是像整型这样的在编译时已知大小的类型被整个存储在栈上,所以拷贝其实际的值是快速的。这意味着没有理由在创建变量 y 后使 x 无效。换句话说,这里没有深浅拷贝的区别,所以这里调用 clone 并不会与通常的浅拷贝有什么不同,我们可以不用管它。
Rust 有一个叫做 Copy trait 的特殊注解,可以用在类似整型这样的存储在栈上的类型上(第十章详细讲解 trait)。如果一个类型拥有 Copy trait,一个旧的变量在将其赋值给其他变量后仍然可用。Rust 不允许自身或其任何部分实现了 Drop trait 的类型使用 Copy trait。
那么什么类型是 Copy 的呢?可以查看给定类型的文档来确认,不过作为一个通用的规则,任何简单标量值的组合可以是 Copy 的,不需要分配内存或某种形式资源的类型是 Copy 的。如下是一些 Copy 的类型:
所有整数类型,比如 u32。布尔类型,bool,它的值是 true 和 false。所有浮点数类型,比如 f64。字符类型,char。元组,当且仅当其包含的类型也都是 Copy 的时候。比如,(i32, i32) 是 Copy 的,但 (i32, String) 就不是。所有权与函数
将值传递给函数在语义上与给变量赋值相似。向函数传递值可能会移动或者复制,就像赋值语句一样。示例 4-3 使用注释展示变量何时进入和离开作用域:
文件名: src/main.rs
示例 4-3:带有所有权和作用域注释的函数
当尝试在调用 takes_ownership 后使用 s 时,Rust 会抛出一个编译时错误。这些静态检查使我们免于犯错。试试在 main 函数中添加使用 s 和 x 的代码来看看哪里能使用他们,以及所有权规则会在哪里阻止我们这么做。
返回值与作用域
返回值也可以转移所有权。示例 4-4 与示例 4-3 一样带有类似的注释。
文件名: src/main.rs
示例 4-4: 转移返回值的所有权
变量的所有权总是遵循相同的模式:将值赋给另一个变量时移动它。当持有堆中数据值的变量离开作用域时,其值将通过 drop 被清理掉,除非数据被移动为另一个变量所有。
在每一个函数中都获取所有权并接着返回所有权有些啰嗦。如果我们想要函数使用一个值但不获取所有权该怎么办呢?如果我们还要接着使用它的话,每次都传进去再返回来就有点烦人了,除此之外,我们也可能想返回函数体中产生的一些数据。
我们可以使用元组来返回多个值,如示例 4-5 所示。
文件名: src/main.rs
示例 4-5: 返回参数的所有权
但是这未免有些形式主义,而且这种场景应该很常见。幸运的是,Rust 对此提供了一个功能,叫做 引用(references)。
引用与借用
示例 4-5 中的元组代码有这样一个问题:我们必须将 String 返回给调用函数,以便在调用 calculate_length 后仍能使用 String,因为 String 被移动到了 calculate_length 内。
下面是如何定义并使用一个(新的)calculate_length 函数,它以一个对象的引用作为参数而不是获取值的所有权:
文件名: src/main.rs
首先,注意变量声明和函数返回值中的所有元组代码都消失了。其次,注意我们传递 &s1 给 calculate_length,同时在函数定义中,我们获取 &String 而不是 String。
这些 & 符号就是 引用,它们允许你使用值但不获取其所有权。图 4-5 展示了一张示意图。

图 4-5:&String s 指向 String s1 示意图
注意:与使用 & 引用相反的操作是 解引用(dereferencing),它使用解引用运算符,*。我们将会在第八章遇到一些解引用运算符,并在第十五章详细讨论解引用。
仔细看看这个函数调用:
&s1 语法让我们创建一个 指向 值 s1 的引用,但是并不拥有它。因为并不拥有这个值,当引用离开作用域时其指向的值也不会被丢弃。
同理,函数签名使用 & 来表明参数 s 的类型是一个引用。让我们增加一些解释性的注释:
变量 s 有效的作用域与函数参数的作用域一样,不过当引用离开作用域后并不丢弃它指向的数据,因为我们没有所有权。当函数使用引用而不是实际值作为参数,无需返回值来交还所有权,因为就不曾拥有所有权。
我们将获取引用作为函数参数称为 借用(borrowing)。正如现实生活中,如果一个人拥有某样东西,你可以从他那里借来。当你使用完毕,必须还回去。
如果我们尝试修改借用的变量呢?尝试示例 4-6 中的代码。剧透:这行不通!
文件名: src/main.rs
示例 4-6:尝试修改借用的值
这里是错误:

正如变量默认是不可变的,引用也一样。(默认)不允许修改引用的值。
可变引用
我们通过一个小调整就能修复示例 4-6 代码中的错误:
文件名: src/main.rs
首先,必须将 s 改为 mut。然后必须创建一个可变引用 &mut s 和接受一个可变引用 some_string: &mut String。
不过可变引用有一个很大的限制:在特定作用域中的特定数据只能有一个可变引用。这些代码会失败:
文件名: src/main.rs
错误如下:
这个限制允许可变性,不过是以一种受限制的方式允许。新 Rustacean 们经常难以适应这一点,因为大部分语言中变量任何时候都是可变的。
这个限制的好处是 Rust 可以在编译时就避免数据竞争。数据竞争(data race)类似于竞态条件,它可由这三个行为造成:
两个或更多指针同时访问同一数据。至少有一个指针被用来写入数据。没有同步数据访问的机制。数据竞争会导致未定义行为,难以在运行时追踪,并且难以诊断和修复;Rust 避免了这种情况的发生,因为它甚至不会编译存在数据竞争的代码!
一如既往,可以使用大括号来创建一个新的作用域,以允许拥有多个可变引用,只是不能 同时 拥有:
类似的规则也存在于同时使用可变与不可变引用中。这些代码会导致一个错误:
错误如下:
不能在拥有不可变引用的同时拥有可变引用。然而,多个不可变引用是可以的,因为没有哪个只能读取数据的人有能力影响其他人读取到的数据。
注意一个引用的作用域从声明的地方开始一直持续到最后一次使用为止。例如,因为最后一次使用不可变引用在声明可变引用之前,所以如下代码是可以编译的:
不可变引用 r1 和 r2 的作用域在 println! 最后一次使用之后结束,这也是创建可变引用 r3 的地方。它们的作用域没有重叠,所以代码是可以编译的。
尽管这些错误有时使人沮丧,但请牢记这是 Rust 编译器在提前指出一个潜在的 bug(在编译时而不是在运行时)并精准显示问题所在。这样你就不必去跟踪为何数据并不是你想象中的那样。
悬垂引用(Dangling References)
在具有指针的语言中,很容易通过释放内存时保留指向它的指针而错误地生成一个 悬垂指针(dangling pointer),所谓悬垂指针是其指向的内存可能已经被分配给其它持有者。相比之下,在 Rust 中编译器确保引用永远也不会变成悬垂状态:当你拥有一些数据的引用,编译器确保数据不会在其引用之前离开作用域。
让我们尝试创建一个悬垂引用,Rust 会通过一个编译时错误来避免:
文件名: src/main.rs
这里是错误:
错误信息引用了一个我们还未介绍的功能:生命周期(lifetimes)。第十章会详细介绍生命周期。不过,如果你不理会生命周期部分,错误信息中确实包含了为什么这段代码有问题的关键信息:
让我们仔细看看我们的 dangle 代码的每一步到底发生了什么:
文件名: src/main.rs
因为 s 是在 dangle 函数内创建的,当 dangle 的代码执行完毕后,s 将被释放。不过我们尝试返回它的引用。这意味着这个引用会指向一个无效的 String,这可不对!Rust 不会允许我们这么做。
这里的解决方法是直接返回 String:
这样就没有任何错误了。所有权被移动出去,所以没有值被释放。
引用的规则
让我们概括一下之前对引用的讨论:
在任意给定时间,要么 只能有一个可变引用,要么 只能有多个不可变引用。引用必须总是有效的。接下来,我们来看看另一种不同类型的引用:slice。
Slice 类型
另一个没有所有权的数据类型是 slice。slice 允许你引用集合中一段连续的元素序列,而不用引用整个集合。
这里有一个编程小习题:编写一个函数,该函数接收一个字符串,并返回在该字符串中找到的第一个单词。如果函数在该字符串中并未找到空格,则整个字符串就是一个单词,所以应该返回整个字符串。
让我们考虑一下这个函数的签名:
first_word 函数有一个参数 &String。因为我们不需要所有权,所以这没有问题。不过应该返回什么呢?我们并没有一个真正获取 部分 字符串的办法。不过,我们可以返回单词结尾的索引。试试如示例 4-7 中的代码。
文件名: src/main.rs
示例 4-7:first_word 函数返回 String 参数的一个字节索引值
因为需要逐个元素的检查 String 中的值是否为空格,需要用 as_bytes 方法将 String 转化为字节数组:
接下来,使用 iter 方法在字节数组上创建一个迭代器:
我们将在第十三章详细讨论迭代器。现在,只需知道 iter 方法返回集合中的每一个元素,而 enumerate 包装了 iter 的结果,将这些元素作为元组的一部分来返回。enumerate 返回的元组中,第一个元素是索引,第二个元素是集合中元素的引用。这比我们自己计算索引要方便一些。
因为 enumerate 方法返回一个元组,我们可以使用模式来解构,就像 Rust 中其他任何地方所做的一样。所以在 for 循环中,我们指定了一个模式,其中元组中的 i 是索引而元组中的 &item 是单个字节。因为我们从 .iter().enumerate() 中获取了集合元素的引用,所以模式中使用了 &。
在 for 循环中,我们通过字节的字面值语法来寻找代表空格的字节。如果找到了一个空格,返回它的位置。否则,使用 s.len() 返回字符串的长度:
现在有了一个找到字符串中第一个单词结尾索引的方法,不过这有一个问题。我们返回了一个独立的 usize,不过它只在 &String 的上下文中才是一个有意义的数字。换句话说,因为它是一个与 String 相分离的值,无法保证将来它仍然有效。考虑一下示例 4-8 中使用了示例 4-7 中 first_word 函数的程序。
文件名: src/main.rs
示例 4-8:存储 first_word 函数调用的返回值并接着改变 String 的内容
这个程序编译时没有任何错误,而且在调用 s.clear() 之后使用 word 也不会出错。因为 word 与 s 状态完全没有联系,所以 word仍然包含值 5。可以尝试用值 5 来提取变量 s 的第一个单词,不过这是有 bug 的,因为在我们将 5 保存到 word 之后 s 的内容已经改变。
我们不得不时刻担心 word 的索引与 s 中的数据不再同步,这很啰嗦且易出错!如果编写这么一个 second_word 函数的话,管理索引这件事将更加容易出问题。它的签名看起来像这样:
现在我们要跟踪一个开始索引 和 一个结尾索引,同时有了更多从数据的某个特定状态计算而来的值,但都完全没有与这个状态相关联。现在有三个飘忽不定的不相关变量需要保持同步。
幸运的是,Rust 为这个问题提供了一个解决方法:字符串 slice。
字符串 slice
字符串 slice(string slice)是 String 中一部分值的引用,它看起来像这样:
这类似于引用整个 String 不过带有额外的 [0..5] 部分。它不是对整个 String 的引用,而是对部分 String 的引用。
可以使用一个由中括号中的 [starting_index..ending_index] 指定的 range 创建一个 slice,其中 starting_index 是 slice 的第一个位置,ending_index 则是 slice 最后一个位置的后一个值。在其内部,slice 的数据结构存储了 slice 的开始位置和长度,长度对应于 ending_index 减去 starting_index 的值。所以对于 let world = &s[6..11]; 的情况,world 将是一个包含指向 s 第 7 个字节(从 1 开始)的指针和长度值 5 的 slice。 图 4-6 展示了一个图例。

图 4-6:引用了部分 String 的字符串 slice
对于 Rust 的 .. range 语法,如果想要从第一个索引(0)开始,可以不写两个点号之前的值。换句话说,如下两个语句是相同的:
依此类推,如果 slice 包含 String 的最后一个字节,也可以舍弃尾部的数字。这意味着如下也是相同的:
也可以同时舍弃这两个值来获取整个字符串的 slice。所以如下亦是相同的:
注意:字符串 slice range 的索引必须位于有效的 UTF-8 字符边界内,如果尝试从一个多字节字符的中间位置创建字符串 slice,则程序将会因错误而退出。出于介绍字符串 slice 的目的,本部分假设只使用 ASCII 字符集;
在记住所有这些知识后,让我们重写 first_word 来返回一个 slice。“字符串 slice” 的类型声明写作 &str:
文件名: src/main.rs
我们使用跟示例 4-7 相同的方式获取单词结尾的索引,通过寻找第一个出现的空格。当找到一个空格,我们返回一个字符串 slice,它使用字符串的开始和空格的索引作为开始和结束的索引。
现在当调用 first_word 时,会返回与底层数据关联的单个值。这个值由一个 slice 开始位置的引用和 slice 中元素的数量组成。
second_word 函数也可以改为返回一个 slice:
现在我们有了一个不易混淆且直观的 API 了,因为编译器会确保指向 String 的引用持续有效。还记得示例 4-8 程序中,那个当我们获取第一个单词结尾的索引后,接着就清除了字符串导致索引就无效的 bug 吗?那些代码在逻辑上是不正确的,但却没有显示任何直接的错误。问题会在之后尝试对空字符串使用第一个单词的索引时出现。slice 就不可能出现这种 bug 并让我们更早的知道出问题了。使用 slice 版本的 first_word 会抛出一个编译时错误:
文件名: src/main.rs
这里是编译错误:
回忆一下借用规则,当拥有某值的不可变引用时,就不能再获取一个可变引用。因为 clear 需要清空 String,它尝试获取一个可变引用。Rust不允许这样做,因而编译失败。Rust 不仅使得我们的 API 简单易用,也在编译时就消除了一整类的错误!
字符串字面值就是 slice
还记得我们讲到过字符串字面值被储存在二进制文件中吗?现在知道 slice 了,我们就可以正确地理解字符串字面值了:
这里 s 的类型是 &str:它是一个指向二进制程序特定位置的 slice。这也就是为什么字符串字面值是不可变的;&str 是一个不可变引用。
字符串 slice 作为参数
在知道了能够获取字面值和 String 的 slice 后,我们对 first_word 做了改进,这是它的签名:
而更有经验的 Rustacean 会编写出示例 4-9 中的签名,因为它使得可以对 String 值和 &str 值使用相同的函数:
示例 4-9: 通过将 s 参数的类型改为字符串 slice 来改进 first_word 函数
如果有一个字符串 slice,可以直接传递它。如果有一个 String,则可以传递整个 String 的 slice。定义一个获取字符串 slice 而不是 String 引用的函数使得我们的 API 更加通用并且不会丢失任何功能:
文件名: src/main.rs
其他类型的 slice
字符串 slice,正如你想象的那样,是针对字符串的。不过也有更通用的 slice 类型。考虑一下这个数组:
就跟我们想要获取字符串的一部分那样,我们也会想要引用数组的一部分。我们可以这样做:
这个 slice 的类型是 &[i32]。它跟字符串 slice 的工作方式一样,通过存储第一个集合元素的引用和一个集合总长度。你可以对其他所有集合使用这类 slice。第八章讲到 vector 时会详细讨论这些集合。
总结
所有权、借用和 slice 这些概念让 Rust 程序在编译时确保内存安全。Rust 语言提供了跟其他系统编程语言相同的方式来控制你使用的内存,但拥有数据所有者在离开作用域后自动清除其数据的功能意味着你无须额外编写和调试相关的控制代码。
所有权系统影响了 Rust 中很多其他部分的工作方式,所以我们还会继续讲到这些概念,这将贯穿本书的余下内容。让我们开始第五章,来看看如何将多份数据组合进一个 struct 中。


















暂无评论内容