
公众号:将门创投 (thejiangmen)
本文为TechBeat人工智能社区第288期线上Talk,
这次我“门”邀请到的是新加坡南洋理工大学&阿里巴巴联合培养博士生—刘林林来到TechBeat人工智能社区开播!他与大家分享的主题是: “基于语言模型的低资源序列标注数据增强方法”,主要介绍有关低资源命名实体识别的相关研究与近期的一些进展和思考。点击【这里】,立即免费收看Talk~
Talk·信息
主题:基于语言模型的低资源序列标注数据增强方法
嘉宾:新加坡南洋理工大学&阿里巴巴联合培养博士生 刘林林
Talk·提纲
讲者团队提出了一种新的基于语言模型的数据增强方法,可以在低资源情况下用于命名实体识别、词性标注、端到端基于目标的情感分析等序列标注任务。相比于计算机视觉,语音识别,数据增强当前在自然语言处理的序列标注任务上目前并没有很多有效的应用,以往提出的同义词替换等等方法都过于简单,且效果并不显著。而其他的数据增强方法,如反向翻译等等仅适用于翻译或者分类的任务,并不适用于序列标注任务。
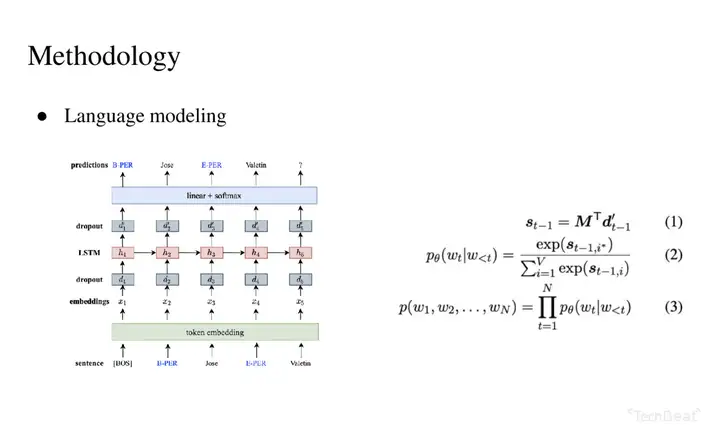
研究团队提出的基于语言模型的数据增强方法,是指把原有的序列标注数据集,通过线性化的方式把文本数据和序列标注变成语言模型的输入数据,从而通过语言模型,生成更多的可用于序列标注训练的数据,以此达到数据增强的目的。
本次分享的主要内容如下:
1. 介绍:目前常见的数据增强方法
2. 序列标注任务
3. 框架:基于语言模型的低资源序列标注数据增强方法
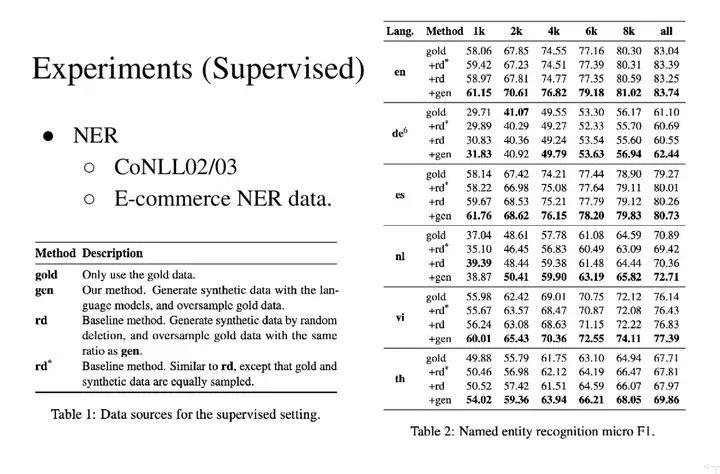
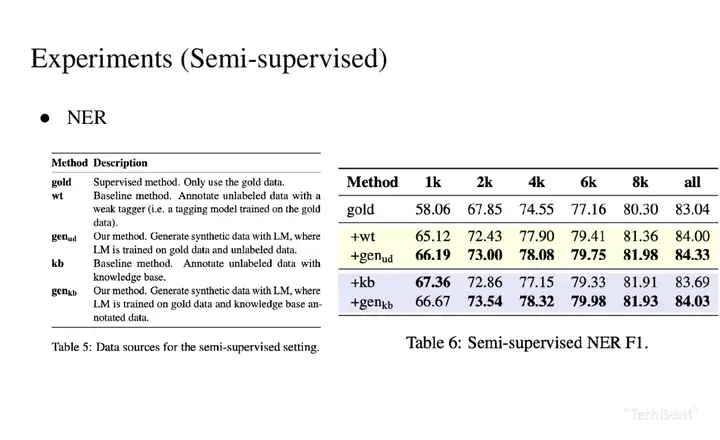
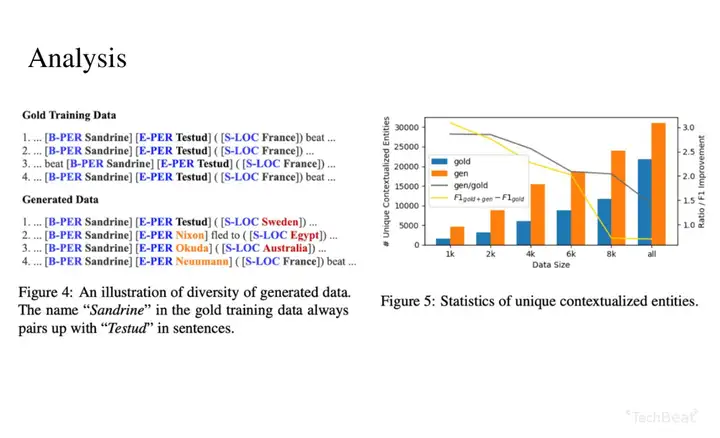
4. 实验结果
Talk·参考资料
这是本次分享中将会提及的资料
DAGA: Data Augmentation with a Generation Approach for Low-resource Tagging Tasks
https://www.aclweb.org/anthology/2020.emnlp-main.488.pdf
Talk·精彩片段
Talk·嘉宾介绍

刘林林,本科毕业于新加坡国立大学,目前是新加坡南洋理工大学和阿里巴巴的联合培养博士生。他刚开始博士第三年的学习,主要研究方向是跨语言知识迁移学习和低资源命名实体识别,现有两篇文章发表在自然语言学习顶会EMNLP。目前正在进行跨语言情境词向量对齐方面的研究,通过更加细粒度的词义级别词向量对齐来提高跨语言知识迁移任务的表现。
▶ 点击【这里
】,一起听Talk啦~
更多精彩Talk,尽在【持续上新 | Talk合辑】专栏@将门创投· 让创新获得认可
如果喜欢,别忘了赞同、关注、分享三连哦!笔芯❤





















暂无评论内容