
Stable Diffusion的发布一举改变了开源AI绘画模型的格局,像普罗米修斯一样把火种带给了普通人。
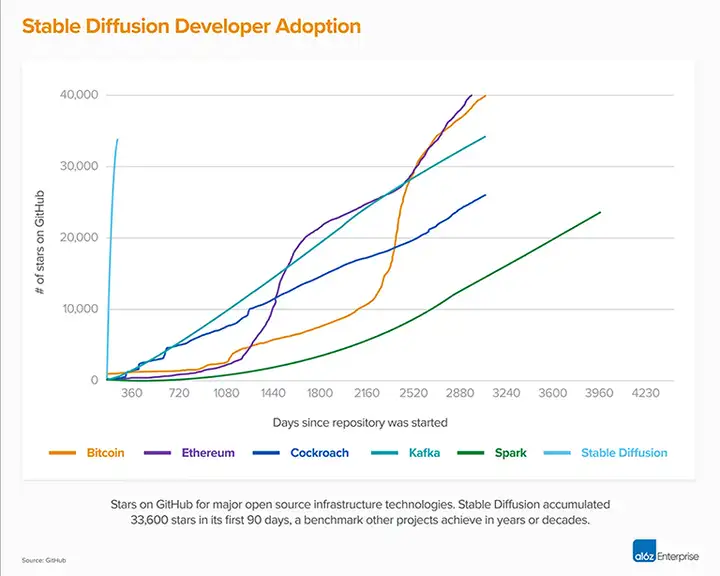
Stable Diffusion发布以来,在全球范围内催生了数百种新的模型和相关创新,比如,支持中文的太乙模型就算一个。
Stable Diffusion已经成了一个现象,也成了Github有史以来少数几个快速达到10k个星的开源项目,截止写这篇帖子的时候,已经到了35K个星。
几天前,Stable Diffusion 2.0 发布了,相较于1.0版本,有多项更新。

首先,Stable Diffusion 2.0采用了新的文本编码器OpenCLIP(来自OpenAI的对比语言图像预训练),有助于提高生成的图片的质量。

第二,新版本默认支持768×768和512×512两种分辨率,此前默认分辨率仅为512×512。
新的模型基于LAION-5B数据集的美学子数据集进行训练,另外,还通过NSFW过滤掉了一些成人敏感内容。
第三,(Super-resolution Upscaler)分辨率放大,Stable Diffusion 2.0的放大扩散模型可以将图像分辨率提升四倍。

如上图所示,可以将128×128的图片放大为512×512的,结合用文字生成的图片,可以生成2048×2048及以上分辨率的图片。
第四,Depth2img利用深度信息生成图片。
Depth2img部分,新增的一些特性带来了更多玩法,比如Depth2img可以对输入图片的深度信息进行推理,然后,用文本和深度信息来共同生成新的图片。

上图中,可以从小红人变成右面的四个小人,新生成的图片整体保持了原有的形状和结构。
这种技术意味着你可以用简单的原型来生成更多具有创意的东西,生成的创意看起来很不同,但有些结构框架是不变的,也就是说,你可以对生成的内容有更多控制。
第五,智能修图inpainting部分,Stable Diffusion 2.0进行了一些微调,使得修图更快速也更智能。

Stable Diffusion 2.0继续优化在单个GPU上的运行表现,使得更多人能接触并用上这款软件,用它来创造令人惊叹的内容。

Stable Diffusion 2.0发布了三四天了,我试着在Ubuntu和Windows环境下手动安装,目前并不顺利,只成功加载了768-v-ema.ckpt这一个权重参数,我得等大神来提供更简易的安装方式了,目前不推荐本地安装。
想尝鲜的话可以试试国外网友在Colab上分享的notebook。
最后放上Stable Diffusion 2.0的GitHub地址,大神可以从这里下手。



















暂无评论内容