
作者 | 胡驰
单位 | 东北大学自然语言处理实验室
AMTA全称The North American component of the International Association for Machine Translation,即国际机器翻译协会北美分会。自1991年起,AMTA每两年举办一次,旨在为来自学术界、工业界和政府的机器翻译研究人员、用户和从业者提供学术交流和产业交流的机会。今年AMTA 2022会议在9月12日至16日进行,采用线上和线下混合的形式,线下在美国佛罗里达州奥兰多举办。
本次会议吸引了来自全世界的400多位来自高校、公司和政府的机器翻译从业者,举办了62场学术报告、产品展示和业界经验分享。其中,学术前沿报告和产业前沿报告覆盖了机器翻译模型设计、领域适应和质量评估等方面的最新进展和业界实践经验。本文将对其中的部分报告进行重点介绍。
1.机器翻译产业发展现状
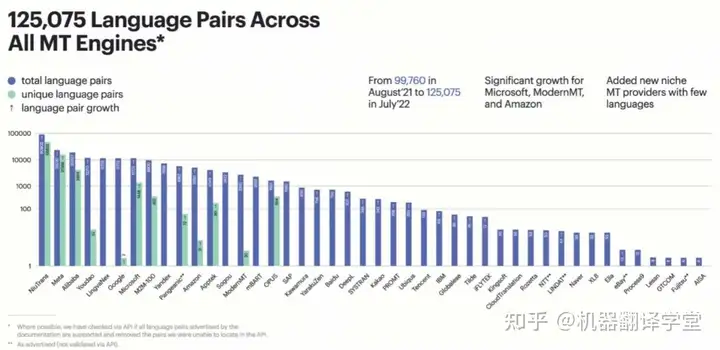
会议从机器翻译市场、机器翻译覆盖语种、领域和质量等多个角度对机器翻译的发展现状进行了总结。这场报告评估了在9大领域(通用、口语、教育、娱乐、金融、医疗保健、酒店、I T 和法律)和10余个主流语言对上的20余个商业机器翻译系统的表现,结果显示英语到西班牙语和汉语的译文质量是最高的。同时,虽然各个系统在通用领域上表现很好,但大部分系统在法律、金融、IT和医疗保健领域上的表现普遍都较差。此外,几乎所有的翻译系统在娱乐和口语领域的表现都很差,这也意味着在这些领域机器翻译还有很大的潜力可以挖掘。
这场报告指出,机器翻译市场仍在迅速增长中,目前覆盖的语种对已经达到了125,075个,相较于去年增加了26,000个,其中NiuTrans支持300种语言互译,是全球支持语种对最多的供应商。


AMTA 2022也举办了多场机器翻译学术报告,覆盖了机器翻译模型设计、数据处理、领域适应和译后编辑等多方面内容。
2.机器翻译模型设计
来自约翰霍普金斯大学的Kevin Duh主持了一场机器翻译模型自动设计的Tutorial,内容涵盖了针对机器翻译模型的超参数优化(HPO)和神经架构搜索(NAS)。这场报告讨论了针对神经机器翻译的超参数和模型结构搜索空间设计,以及如何针对特定目标(如翻译质量或翻译效率)设计有效的自动优化方法,同时也分享了微软机器翻译团队在实际场景中应用超参数优化和架构搜索方法的经验。笔者在过去几年里也对机器翻译模型的自动设计进行了长期探索,特别是针对不同的部署环境自动设计模型结构、自动选择最优的超参数设置。自动优化方法的确能够有效地提升机器翻译模型在不同硬件架构上的运行效率和翻译性能。当需要在翻译品质和效率之间寻找最优平衡点时,这类方法有很大的用武之地。然而自动优化方法的效率一直是制约其广泛应用于各类场景和任务的主要因素,目前这类方法的发展也受到了很大的阻碍。
除了自动设计翻译模型,从信息编码的角度对模型进行改进也是本次会议中颇受关注的研究方向。主流的神经机器翻译模型广泛使用字节对编码(BPE)来处理低频词和未登录词,该方法使用子词作为基本单元。也有一些工作探讨了基于字符的机器翻译,但由于字符序列很长,计算代价往往十分高昂。来自瓦伦西亚理工大学的Salvador Carrión-Ponz介绍了一种准字符级机器翻译建模方法,其粒度介于字符与子词之间,该方法能够缓解机器翻译中灾难性遗忘问题,同时与字符级建模方法相比更为高效。
3.机器翻译领域适应
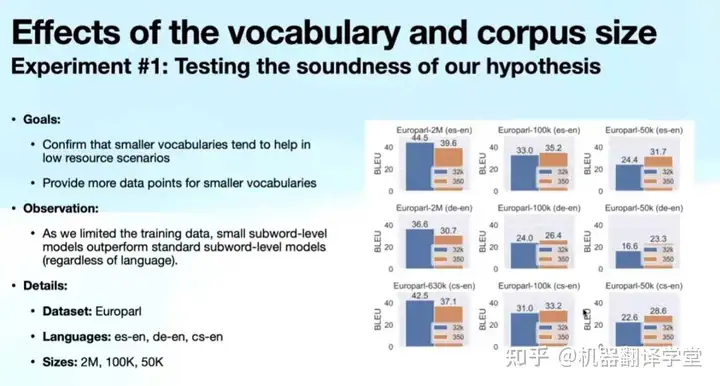
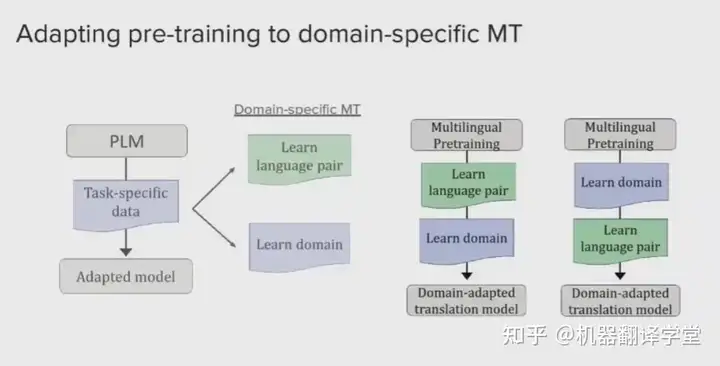
目前数据驱动的机器翻译模型在通用的新闻领域上取得了出色的表现,然而在特定领域上由于数据相对稀缺,其翻译质量往往要逊色不少。从AMTA 2022可以看出,机器翻译领域适应不论在工业界还是学术界都成为了一大研究热点。本次会议上展示的研究集中在如何降低对领域内平行语料的需求、如何实现动态领域适应和轻量级领域适应,下面从不同角度对这些研究工作进行介绍。
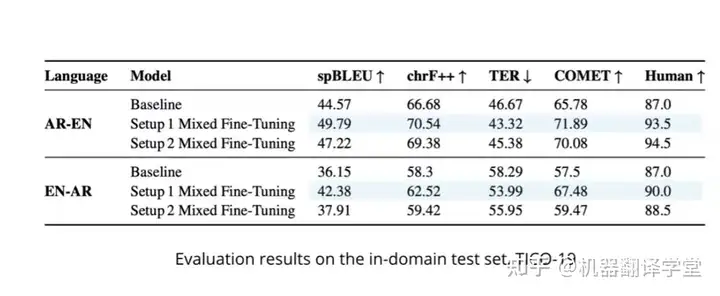
1)数据增强。来自都柏林城市大学的Yasmin Moslem介绍了一项机器翻译的领域特定文本生成工作,该工作利用单语预训练语言模型实现机器翻译特定领域的数据增强,结合反向翻译生成双语伪数据。在英语和阿拉伯语的翻译任务上取得了5个BLEU值的性能提升。
2)数据高效适应。来自约翰霍普金斯大学的Neha Verma提出了两种策略,第一种是首先在通用领域的双语数据上训练模型,然后使用领域内双语数据进行微调;第二种是首先使用多语言领域内平行语料进行训练,然后在不同语言对的领域内数据上进行微调。第一种策略可以有效地提升翻译品质,当使用mBART时比Transformer基线高出10个BLEU,第二种策略可以有效地降低对通用领域数据的依赖。
3)参数高效适应。传统领域适应时对模型的全部参数进行微调,这样不同领域都需要存储完整的模型权重,当领域数量庞大时存储和传输成本十分高昂。针对这一问题,来自约翰霍普金斯大学的Suzanna Sia借鉴Prefix-tuning,提出基于Prefix的微调方法,实现大规模预训练语言模型的参数高效领域适应。该方法只需要调整原始模型不足百分之一的参数即可取得相似甚至更好的表现。
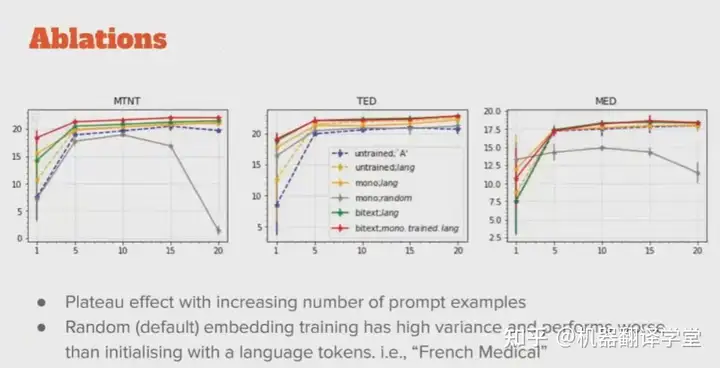
4)在线领域适应。前面的领域适应方法都需要对模型权重进行调整,现实场景中绝大多数用户都没有办法调整服务商的翻译模型权重,但有时可以提供一些翻译示例。针对这一场景,来自SYSTRAN的John P Barraza分享了如何通过模糊匹配(Fuzzy Match)和相似语义查询提供更充分的领域上下文信息。基于模糊匹配的翻译通过字符串匹配方式搜索相似句子为模型提供了示例,而基于嵌入相似性的翻译通过使用分布式句子表示检索,能够为翻译提供更合适的上下文。这一方法能够显著超越传统的翻译记忆(Translation Memory)方法,在基于字符串匹配的自动评价和基于语义相似度的自动评价指标上都取得了很大的提升。

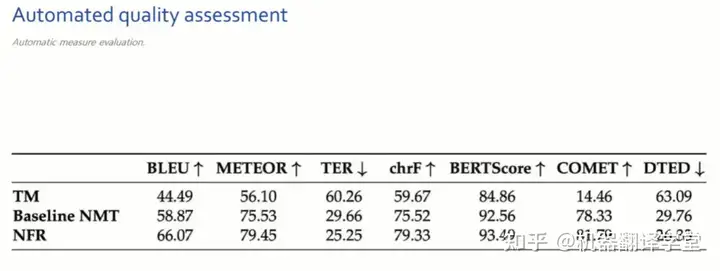
4.总结
这次AMTA会议展示了机器翻译研究和产业的发展现状,其中最引人瞩目的当属机器翻译的领域适应。踏着深度学习的发展浪潮,数据驱动的神经机器翻译在通用的新闻领域取得了长足的进展,但在资源相对稀缺的特定领域上机器翻译的性能仍显不足。这对机器翻译的学术研究和产业实践都带来了巨大的挑战。结合WMT这一顶级机器翻译评测来看,机器翻译的领域适应越来越受到研究者和从业人员的关注。如何充分利用现有的通用领域数据、相对充足的单语数据,同时减少对模型结构和参数的调整、实现机器翻译的动态领域适应,是机器翻译研究和实践中十分值得关注的话题。
阅读更多内容请查看“机器翻译学堂”
关于机器翻译学堂
机器翻译学堂是一个以机器翻译为核心的学习平台。面向所有的自然语言处理、机器学习等领域的学习者,分享论文解读、学习资料、优质博客、会议信息、行业动态、开源数据集等资源。
欢迎大家多多关注机器翻译学堂,一起学习,共同进步!
网站:https://school.niutrans.com
微信公众号:jiqifanyixuetang




















暂无评论内容