
Prodigy是什么
Prodigy是一种款由Explosion AI开发的支持脚本编写的数据标注工具,用于为机器学习模型创建训练集和验证集,方便用户可以快速独立的迭代自己的机器学习模型。此外,Prodigy可以帮助使用者检查和清理数据,进行错误分析。
Prodigy在NLP中的优势
自然语言处理大部分的任务都属于监督学习类型,并且NER是NLP中一个子问题。NER的准确度是保证实现信息提取、问答系统、句法分析、机器翻译等众多高级NLP任务的重要基础。在NER任务中,需要大量需要标注的数据进行训练。深度学习大行其道的今天,基于深度学习的 NLP 模型更是数据饥渴。谈到自然语言中的数据,首先脑海中会想起语料库。然而,最前沿的的NLP技术往往首先针对于英文语料,这点导致了中文NLP生态没有英文NLP生态好,中文的开源语料库相对于英文品种和数量都少。此外,NLP对一些垂直领域方面,如医疗、金融、法律等,专有名词和特有需求甚多,因此,这些场景很难移植使用一般语料库训练出来的模型。遇到上述的情景,自然语言处理的开发者就要自己选择相关数据并标注去训练模型。因此在NLP中,一个好用的数据标注工具是非常重要的,它可以帮助使用者更快的预处理机器学习模型所需的数据,加速产品的落地。
传统的标记方法往往繁琐且效率低。Prodigy的强大之处在于它有一套智能算法,可以减少人工的重复劳动。并且Prodigy的标注UI易于上手,可以帮助使用者高效进行标注。并且在UI界面还有标注进度显示和标注接受率,这个功能可以让标注者更好地规划自己的标注速度,改变自己的标注策略。
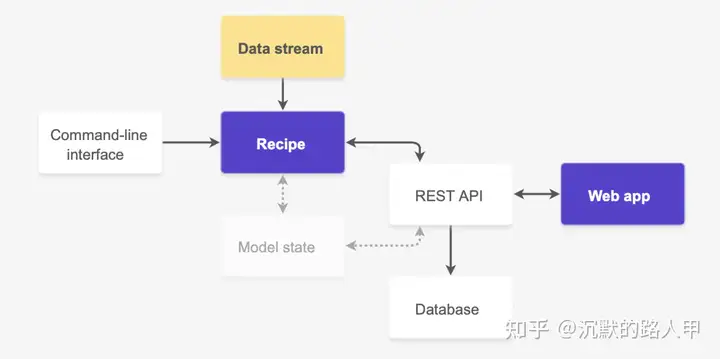
上图是Prodigy的一个简单架构图,Web app即为Prodigy提供给使用者高效标注的界面。在用户标注一部分数据后,这些数据可自动或手动的传入数据库中。REST API为用户操作数据提供了极大地便利,它还能连接SpaCy的接口去处理数据。而Recipe类似于method的意思,通过不同的recipe可以在command line上进行想要的操作。并且可以自定义recipe来使用任何框架插入自定义模型。
主动学习的智能标注算法
通过查阅相关文档发现,Prodigy将主动学习的后台算法分为了online和offline两部分。
其主要流程如下:
用户标注一个labelonline部分是通过用户的标注即时更新模型,这个阶段采取的是传统方法。由于Prodigy是闭源工具,尚不了解它的具体算法。我最初想法是想要用bag-of-word模型或者是使用BIO表示法结合SVM的one-vs-one或one-vs-rest进行快速冷启动。不过后来在看到Prodigy的Co-Founder Ines对该工具的NER功能的tutorial中提到了“即使有单词拼写错误,也可能被正确的标注出来”,我觉得在这一阶段使用了word2vec的方法,因为拼写错误的词和正确的词的词向量是非常接近的。因为Prodigy和著名NLP开源软件库-SpaCY是一个团队,Prodigy用了很多SpaCy的接口。不过我发现SpaCy不能生成自定义词向量,所以如果在训练时想要使用自定义词向量,需要使用其他库。spaCy的官方文档也建议使用其他库,例如用Gensim来生成词向量。offline 部分是当标注数据积累到一定数量时更新模型(当然也可以使用左上角保存键提前训练),然后使用准确度较高的复杂的深度学习模型(如LSTM+CRF,Bert+CRF或CNN+CRF等模型)。当然,很多常用类别可以直接调用SpaCy训练好的的常用类别模型进行冷启动,然后再开始进行step 2。模型更新后,对尽可能多的 example 做预测,将确信度排序,取确信度最低的一个 example 作为待标注例子。重复 step 1 的过程。在确信度排序里,Prodigy采用了Beam Search的方法,这个方法可以解决每步预测都预测当前概率最大的元素,最后的序列却可能不是概率最大的序列的问题。通过确定光束的宽度来得到同等数量的最优路径,这可以增加找到概率最大的预测序列的可能。在最终标注任务完成之后,offline 模型可以重新在所有标注数据上重新训练,以达到最好的模型效果。通过online 与 offline 模型互相协作,与用户手动标注的过程一起不断迭代,如果模型训练得好,这个过程将直接忽略掉确信度最大的那些例子,而把所有重点放在分类边界上的那些确信度小的例子。这样可以尽算法所能减少用户端的人工工作量。
标注前端用户友好
Prodigy在NER任务中有三种处理方式,这提供给了用户不同的操作选择,大大增加了操作的多样化。在Manual模式中,用户只需要双击单词就可以将单个词高亮,并且也可以使用鼠标拖动选择多个词。此外在鼠标拖动这个功能里,它会自动识别边界,用户不必像素精确到词的尾部。例如school这个词,即便拖动到h这个字符,那么这整个词也会高亮,这大大简化了标注难度,提高标注的准确度。如果用户需要标注到单个字符,这时候可以选择character- based模式。如果在已经有一个模型,并希望在更多数据上对其进行微调,还可以使用binary模式进行快速判断,这样可以更快速让模型得到反馈,提高了模型后期的训练速度。
可编写脚本且可扩展
Prodigy是完全可编写脚本的,并且可以整齐地插入基于Python的数据科学工作流的其余部分。Prodigy具有丰富的Python API、优雅的命令行集成和高效的Jupyter扩展。通过使用自定义配方脚本,用户可以让Prodigy以您喜欢的方式读写数据,并使用用户喜欢的任何框架插入自定义模型。其中,我在Demo中了解到了强大的patterns参数支持模式匹配,模式匹配可以使用正则表达式写成jsonl的文件建立模式或者直接使用Spacy库里早就存在的types的模型进行预训练,这些方法可以帮助模型克服冷启动,并确保它以足够多的积极示例开始,从而提出有意义的建议。这可以用于性能非常差的实体类型,甚至可以将新实体类型添加到现有模型中。
Prodigy命名体识别任务流程
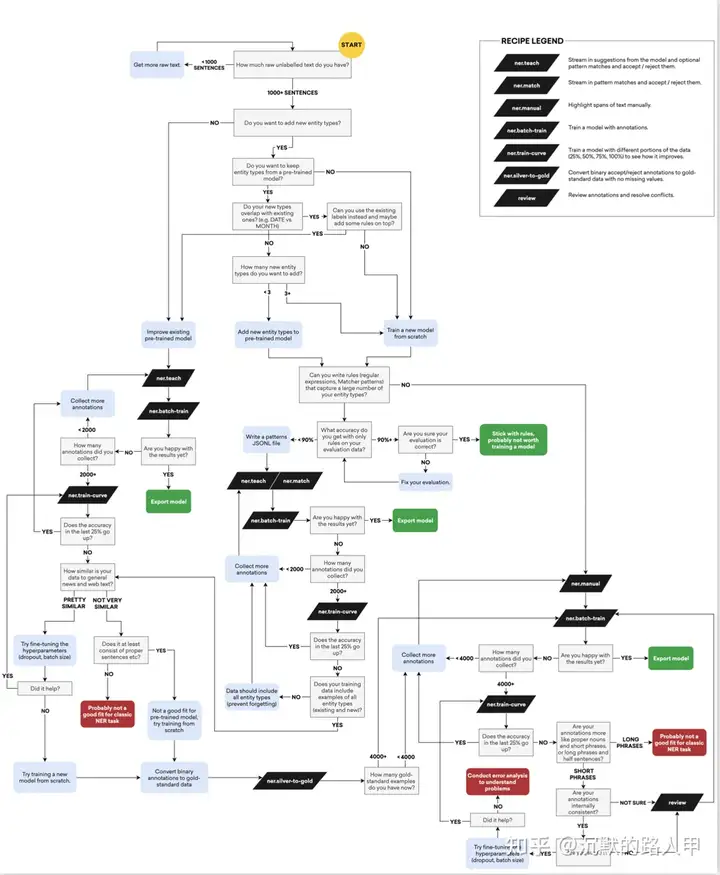
下面的流程图详细的介绍了在NER任务中,不同阶段应该使用的recipes(左上角的Legend是所用到的recipes的简单介绍),具体的recipe介绍可以查询Prodigy官方recipes文档。
Prodigy支持其他任务类型
Prodigy不仅有强大的算法支持命名体识别的标注,它还支持多种其他任务。Prodigy为每个任务都提供了一个用户友好且多样性的标注方式,如:
实体关系抽取:从文档中提取较长的短语和嵌套表达式是应用自然语言处理中的常见任务。Prodigy允许用户通过手动高亮显示单词文本来标记关系。关系任务最困难的是,没有两个问题是完全相同的,因此添加一点自定义逻辑很重要。而Prodigy可以使用spaCy强大的规则引擎或用户自定义的recipe轻松添加规则以自动合并短语或关系。文本分类:文本分类任务通常有多个类别可供选择,这些类别可能不排他性,也可能不具有互不排他性。Prodigy完全支持所有这些问题类型。它通过提出“是或否”的问题,来让用户选择。结合Prodigy的学习算法,这种二进制方法特别强大,因为这可以让模型只选择它最不确定的问题从而不断增加模型信息。CV问题:在运行对象检测、图像分割或图像分类模型时,Prodigy可以轻松创建注释训练数据并纠正模型的错误。用户可以使用绘制多边形等多种方式处理图片。并且对注释可以导出为带有像素坐标的简单JSON文件,从而可以轻松地将数据集成到pipeline。音频和视频:高亮显示音频或视频文件的切片,并用所需要的任何标签标记它们。Prodigy支持放大和缩小音视频,使注释更精确。并轻松启动、停止和重播输入音视频,以确保处理正确。




















暂无评论内容