
原文首发自幻方AI技术博客,点击获得更好阅读体验。

AI 绘画最近成功破圈,成了炙手可热的热门话题。DALLE,GLIDE,Stable Diffusion 等基于扩散机制的生成模型让 AI 作图发生质变,让人们看到了“AI 转成生产力”的曙光。
在这些扩散模型中,Stable Diffusion 以其优秀的效果和开源的权重成为了其中的代表,受到广泛的关注和体验。其基于 Laion5B 超大规模“文本 – 图像”对数据集,Stable AI 宣称用了 5000 张 A100 耗时几个月训练而成。幻方 AI 近期在萤火二号上使用 Google Caption 数据集复现了 Stable Diffusion 的训练,并进行了优化。通过幻方自研的 hfai.pl 插件将源代码 Pytorch Lightning 框架与萤火集群的特性轻松整合,并通过 3FS、hfreduce、算子等优化工具对模型训练提速。
本文将分享我们对 Stable Diffusion 训练优化的心得体验,帮助研究者和开发者们降低研究门槛。
论文标题:High-Resolution Image Synthesis with Latent Diffusion Models
原文地址:https://arxiv.org/abs/2112.10752
源码地址:https://github.com/CompVis/stable-diffusion
模型仓库:https://github.com/HFAiLab/stable-diffusion
模型介绍
Stable Diffusion 基于 Latent Diffusion 进行了扩大训练,其将 Text Encoder 从 BERT 更换为 CLIP Text Encoder。我们首先了解下 Latent Diffusion 的模型设计。
过往虽然扩散模型的生成能力非常强大,在许多不同类型的生成任务上都达到了 SOTA 的水平,但由于其迭代生成的特点在训练和推理时往往都需要耗费非常多的 GPU 资源。Latent Diffusion 针对这一点做出了改进,通过将扩散过程从图片的像素域转变为在编码后的潜空间上,这种方式大幅降低了扩散模型运行时的复杂度,同时也能保留较好的细节和图像生成效果。整体结构如下图所示:
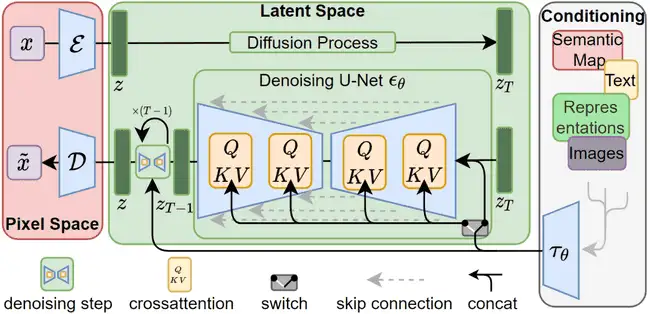
01 Latent Encoding
Latent Diffusion 通过在一般的扩散模型中增加一个变分自编码器来实现像素空间和隐空间的转换。在训练 DDPM 模型前首先会在 ImageNet 上训练一个 VAE 模型,其旨在学习一个编码器和解码器,用于将图像压缩成潜在编码。VAE 会将图片压缩到原来的 1/4 ~ 1/8 的大小,因此可以极大的降低在隐空间进行操作时的计算复杂度。而在这种情况下压缩再还原后的图片也能较好的保留原图片的信息,基本不会因为压缩产生过大的损失。
02 Cross-Attention
Latent Diffusion 创新的使用了注意力机制来进行条件控制信息和图像生成过程的融合。在条件控制生成上,作者在 U-Net 模型的每一层都引入了条件控制信息来控制图像生成的方向。而在控制信息和图像生成过程的融合上,作者引入了 Cross Attention。基于注意力的融合机制使得模型可以更容易的使用不同类型的条件控制信息,例如文本生成图片,图片生成图片,或是语义图生成图片等等。
03 Text-based Generation
和 Latent Diffusion 不同,Stable Diffusion 的重点在于文本生成图片。Stable Diffusion 使用了远大于 Latent Diffusion 的 LAION-5B 数据集中的 25 亿“图片 – 文本”对进行训练。此外受到 Imagen 等其他生成工作的启发,还将 Latent Diffusion 中使用到的 BERT Text Encoder 替换成了效果更好的由 CLIP/ViT-L-14 预训练的 Text Encoder。
模型实践
01 训练数据集
为了验证 Stable Diffusion 模型的训练性能,我们使用 Google Conceptual Caption 数据集复现了 Stable Diffusion 的训练。Google Conceptual Caption 是一个相对小范围的多模态数据集,其中有 285 万“图像 – 文本”对。该数据集已集成在幻方 AI 的数据集仓库中,转化为 ffrecord 训练数据格式存储在 3FS 高速存储里。用户可以通过如下方式调取获得高速的训练数据读取:
02 hfai.pl
Pytorch Lightning (PL) 在 PyTorch 基础上进行了封装,拥有其独特的并行训练接口。Stable Diffusion 源码基于 PL 所构建,为了使其利用起萤火集群的各种优化特性,我们采用幻方开发的 hfai.pl 插件来进行适配,具体包括:
hfai.pl.HFAIEnvironment,自动适配萤火集群的多卡并行环境,在训练时加入插件就可以正常使用;hfreduce_bind_numa,使用 hfreduce 加速通信,绑定 buma 避免多卡间额外的网络开销;hfai.pl.nn_to_hfai,使用 hfai 优化算子替换模型中的基础算子,加速训练具体操作如下:
1 . 在配置文件中将 trainer 的 strategy 指定为 hfreduce_bind_numa:
2 .在训练代码中,使用 nn_to_hfai 算子加速和 HFAIEnvironment 的环境设置功能:
通过如上简单几步操作就可以将萤火集群的加速特性融入到 Stable Diffusion 的训练代码中。测试在使用 hfai.pl 前后模型训练速度的变化,可以发现模型的单次 forward 时长从 0.787 秒加快到了 0.758 秒,速度提升了 3.8%。
训练优化
我们在 Google Conceptual Caption 上使用 256×256 的分辨率进行训练,使用了在 ImageNet 上预训练的权重来初始化用来进行隐空间映射的 VQVAE 模型。
在训练时我我们尝试了使用 4,8,16,32 节点分别进行 Stable Diffusion 的训练以测试不同并行条件下的敏感度。在逐步扩大 Stable Diffusion 训练规模的过程中,我们发现 Stable Diffusion 对学习率非常敏感,然而学习率不能轻易随 Batchsize 增大而增大,这很容易导致梯度爆炸的发生。因此,我们在训练时采用了 Warmup 和 Gradient Clipping 的方法来帮助模型加速收敛,避免无法收敛的情况。
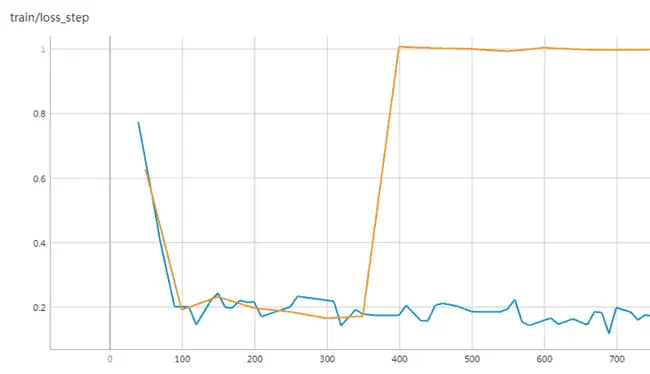
上图中橙色和蓝色曲线分别展示了有无使用 Warmup 和 Gradient Clipping 训练时的 loss 情况。如橙色曲线所示,当不使用 Clipping 和 Warmup 策略,模型在训练到第 400 个 step 的时候就出现了梯度爆炸的现象,无法继续正常进行收敛。而在使用之后,模型训练的学习率增长变得更加平缓,能够有效的避免发生梯度爆炸的发生。
训练结果
我们将模型在 Googlecc 数据集上训练了 240K Steps 后进行测试。在 COCO FID-30K(一个 COCO Caption 数据集中随机挑选的子集,由 3w 张图片组成)上,模型取得了 16.5 的 FID 指标,说明模型生成的图片能比较好的体现出文本中的内容。
以下是一些样例文本和将他们输入模型后生成的图片:
(a) A photo of a woman skiing on a white mountain.

(b) A painting of a squirrel eating a burger.

(c) A photo of a red train being operated on a train track.

(d) A photo of a dog playing in a green field next to a lake.

可见虽然训练数据集规模较小,但模型仍然达到了较好的生成效果。
体验总结
Stable Diffusion 作为 AI 作图领域的旗舰模型,受到了广泛的关注,在小范围数据上训练也可以实现惊艳的生成效果。我们借助幻方萤火集群,通过简单几步改造,能比较轻松地实现 Stable Diffusion 的训练加速,证明了萤火集群的易用性和实力。
综合体验打分如下:
01:研究新颖度 ★★★★
作者提出了一种在隐空间上进行扩散的生成模型结构,降低了扩散模型运行开销的同时保证了生成质量。模型还应用了交叉注意力机制来辅助条件控制生成,并且支持多种不同模态条件下的图像生成。
02:开源指数 ★★★★★
作为首个完全开源代码、训练数据和预训练权重的 AI 绘画预训练大模型,stable-diffusion 在学术界和其他相关领域都产生了极大的影响力。
03:算力门槛 ★★
由于模型对资源占用有所优化,且开源工作完善,因此单个普通 GPU 即可运行模型推理。但训练开销较高。
04:通用指数 ★★★★
作者提出的在隐空间上进行扩散的方法对一般的扩散模型都能够适用,并且基于交叉注意力的条件控制方法也能将模型应用于许多不同任务类型,对生成领域研究工作有广泛的借鉴意义。
05:模型适配度 ★★★
该项目依赖 pytorch-lightning,需要对萤火集群进行一定适配,但通过 hfai.pl 工具也能比较容易的在幻方 AI 环境运行并获得加速效果。
幻方AI,希望让更多“想象力”和“创造力”生长。期待与各方科学家及开发者们一同共建AI时代。



















暂无评论内容