
OpenAI创始人山姆·奥特曼曾说:“十年前的传统观点认为,人工智能首先会影响体力劳动,然后是认知劳动,再然后,也许有一天可以做创造性的工作。现在看起来,它会以相反的顺序进行。”ChatGPT的出现印证了这一点!
ChatGPT的一炮而红即将为OpenAI带来约290亿美元的融资,然而这样的成功背后不止有技术天才和资金,2022年OpenAI的预训练语言模型在技术路线上作出了新的选择:“基于人工标注数据+强化学习的推理和生成”。据美国《时代》杂志调查发现,为训练ChatGPT,OpenAI招募了大量数据标注人员,甚至还投入了大量博士级别的专业人士来完成高质量的标注任务,着眼长远,将大量资金投入在人工数据标注上是OpenAI成功的关键决策。
OpenAI在博客中写道,ChatGPT是从GPT3.5系列中的模型进行微调而诞生的。以往的预训练模型都是为了减少监督学习对高质量标注数据的依赖。而正是ChatGPT在GPT-3.5大规模语言模型的基础上,又开始依托大量人工标注数据,才得以实现理解人类指令,更精准更有“人味”的自动输出。
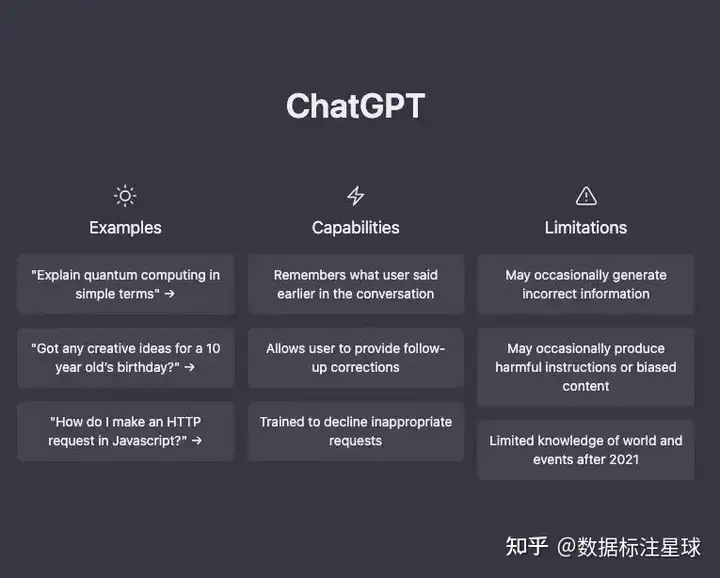
业内普遍认为,ChatGPT是人工智能里程碑,更是分水岭,这意味着AI技术发展到临界点。在人工智能领域深耕数十年的百度能否乘其东风完成自我变革,引发业界关注。在外界看来,ChatGPT或成为下一代搜索产品的雏形。

另一方面,互联网在拥有知识的同时也存在恶意和偏见的内容,通过数据标注建立一个额外的人工智能驱动的安全机制,运用文本分类标注、对话语料构建等标注类型来帮助模型调优,OpenAI才能控制这种危害,生产出适合日常使用的聊天机器人,避免出口成脏,性别歧视或者发表种族主义言论的出现。
盘石数据标注助力AI语音模型的进化发展
盘石数据深耕数据标注业务,积累了丰富的文本标注经验并针对语音模型训练提供优质的标注服务,包括:
对话评价——从多个方面针对自动生成的对话进行评价,如情感、正确性、流畅性等多个方面。

故事改写——根据情节对自动生成的故事进行改写,使其语义通顺,逻辑完整。

摘要抽取——针对长文本进行摘要抽取,保证情节完整,篇幅简短,表达流畅。
逻辑推理——根据推理题目的信息,给出正确答案并提供解题思路。

角色扮演——构建角色并与该角色进行对话,避免出现逻辑错误、人设不符、不通顺、错字等情况。
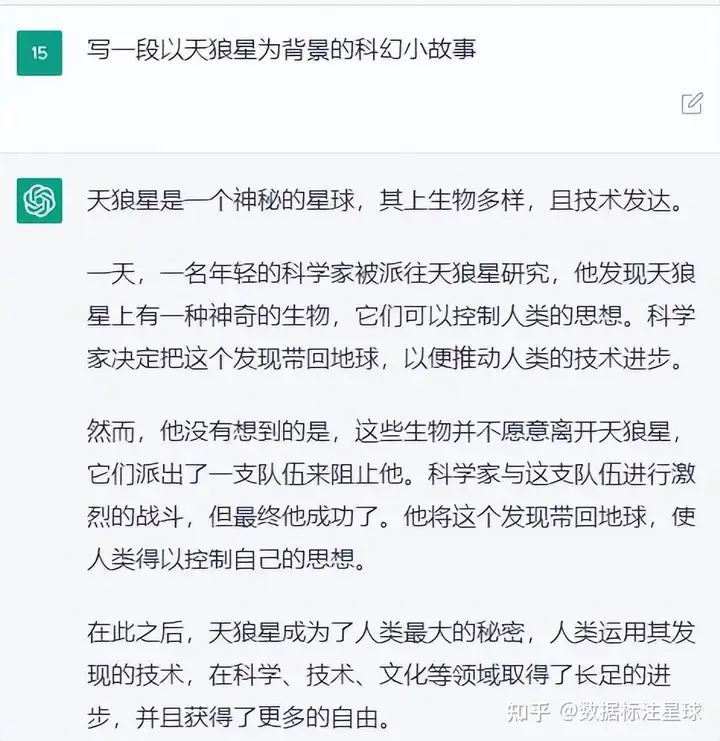
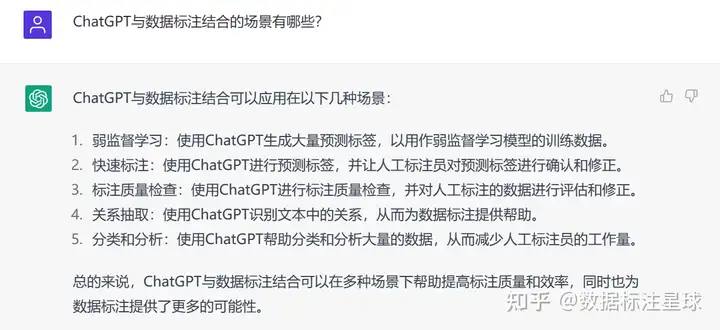
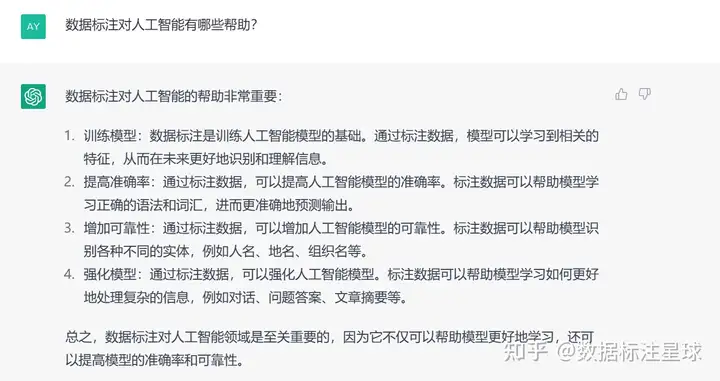
以下为ChatGPT关于“数据标注”的观点




国际领先的基础数据服务商——盘石数据
辽宁盘石数据科技有限公司是一家拥有自然语言处理技术(NLP)基因的人工智能基础能力服务商,从数据(Data)、 算法(Algorithm)、人才(Talent)、智能应用(Application)、服务(Service)全方位助力人工智能发展。为全球提供有竞争力的“DATAS”数据建设解决方案。
公众号:盘石数据





















暂无评论内容