
文章目的:
– 了解标注数据对深度学习的意义
– 了解标注与模型之间的相互作用1. 标注数据
接下来,我们会以情感分析任务展开介绍。
1.1 原始数据
首先,我们有一些文本数据(text),如下所示:
textlabel武汉是一个美丽大气的城市。1很感谢大家阅读我的文章。1今天上午在today吃了一碗热干面,喝了一杯豆浆。0咖啡和茶,哪一个更好喝呢?0很烦,做什么事都不顺。-1又是无聊至极的一天,唉。-1这里,text为原始的数据,也是之后标注工作者需要使用的。
2. 标签定义
那么,在给定原始数据之后,就需要定义标签(label)。在实际过程中,标签的定义需要结合项目的需求来制定。在这篇文章中,以情感分析为例子,将label定义为了{-1,0,1},其中,-1 代表着负面的情感,0 代表着中性的情感,1 代表着正面的情感。
3. 打标签
顾名思义,结合文本的内容,给与相应的标签。例如,1.中的6个句子,根据标签的定义,我们给了它们合适的标签label。在实际项目中,由于数据量较大,需要逐条标注每一条数据,这个过程会由标注工作者完成。
2. 深度学习
从有无监督的角度上看,我们可以将深度学习分为3个类型,分别为有监督、半监督和无监督。无监督和有监督的最大区别点在于,无监督深度学习的训练不需要标注数据,有监督则需要。此外,在半监督深度学习的训练中,一部分数据是标注的,另一部分数据是未标注的。
在NLP领域,有监督深度学习最常见的应该是预训练语言模型,例如BERT、RoBERTa、ALBERT等。半监督深度学习,例如MixMatch,是无监督中很常见的一种。相比有监督和半监督,有监督深度学习的使用最为广泛的,大部分的NLP任务基本上都是有监督的。
在这篇文章中,结合标注的数据,我们使用的深度学习是有监督的。情感分析任务可选的深度学习框架很多,基本上大部分的网络框架都可用,只是效果或效率有差异,这里就不一一对比了。
3. 标注数据对深度学习的意义
3.1 数据数量
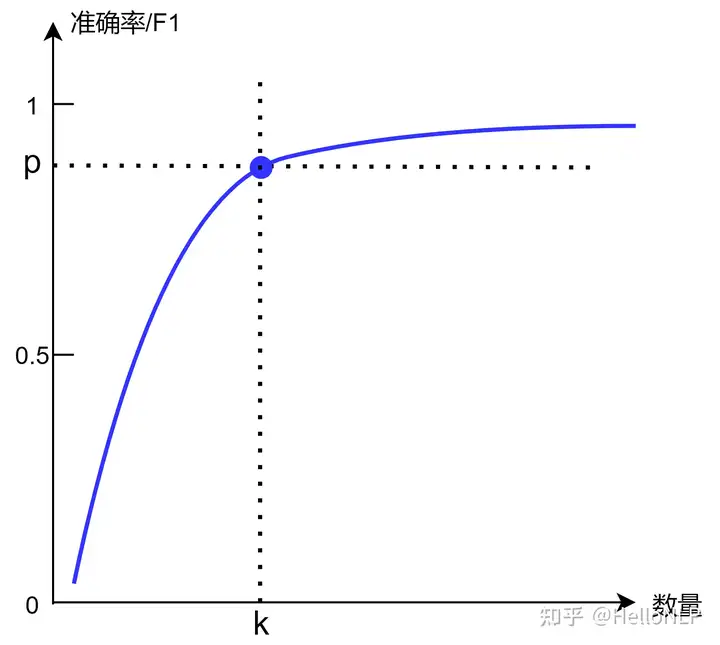
标注是一个耗费人力与时间的过程,成本非常大。从理想角度看,标注的数据数量越多,训练得到的模型效果也会越好。但是,实际情况往往并不允许。做个一名合格的算法工程师,一方面,需要结合实际的资源与时间;另一方面,项目对模型效果的要求,数据量增加对模型效果提升带来的影响,综合这2点再取一个合适值 kk 往往显得尤为重要。
3.2 数据质量/效率
标注数据的质量,对训练得到模型的效果同样有着很大的影响。一般情况下,为了提升标注的质量,会采取以下几个方法:
选择有经验的标注人员每一条数据由多人标注/抽样检查好用的标注工具3.3 算力
深度学习的参数量一般都比较大,所以选取一个合适的模型大小显得尤为重要。无论是在模型训练的过程中,还是模型部署之后,都需要考虑硬件资源。这两个过程耗费的主要是算力,即CPU或者GPU。
如果标注的数据量越大,同样的硬件条件下,以及同样的模型参数量下,所需的训练时间也会越久,几乎满足o(n)。实际过程中,模型更新的频率往往较快,如果训练时长过久,对模型的更新频率有较大的负面影响。
4. 标注与模型之间的相互作用
在三、中,我们清晰地理解了标注对深度学习的意义,其中标注可以提升模型的效果。那么,模型是否可以帮助标注呢?
4.1 标注问题
人工标注的过程毕竟是一个主观的工作,所以也会有一定的错误率(常见0%-5%)。例如情感分析标注,同样一个句子,在不同的人看来,会有不同的情感。为了纠正类似的标注问题,最好的方法当然是多人标注同一条数据,比如说每条数据5人参与标注,中标最多的标签即为最终结果。但是,这样做会带来较大的成本问题。采用一种经济高效的方法去克服这个问题,是必须面对和解决的。
4.2 模型纠错
为了更好地解决标注问题,根据自己的工作经验,了解到一个通过模型继续纠错的方法。我们可以将数据集打乱,然后按照一定的比例分割成TrainData和TestData,然后训练得到模型(根据实际情况A取合适的收敛程度,也可以过拟合)。重复这个过程2-3遍,即得到2-3个模型。之后,利用这几个模型,对数据集进行全量推理预测,取出它们预测错误的交集或并集(视实际情况B而定)。
通过模型纠错找出的数据,其中大部分是因为标注问题导致模型难以拟合的数据。
4.3 重新标注
通过步骤2,会得到需要纠错的数据,它的数据量取决于实际情况A和B。通常,建议这一部分的数据量占整体数据的5%-10%。将这一部分数据重新提交给标注的工作者,进行Review的工作。
获取重新标注的数据后,替换之前的标签,再训练模型,我们会发现模型效果往往有明显的提升。
5. 实践
下面,介绍一组真实的情感分析实验结果。由于数据保密,做了一定的脱敏处理。其中,之后的每一步都是在上一步优化之后的操作。
PLM :Pre-training Language Model
模型操作准确率PLM + TextCNN训练数据NPPLM + TextCNN训练据数2*N1.0399*PPLM + TextCNN训练据数3*N1.0492*PPLM + TextCNN训练据数4*N1.0577*PPLM + TextCNN训练据数4*N
+ 人工纠错5%数据1.0778*PPLM + TextCNN训练据数5*N1.0856*PPLM + TextCNN训练据数5*N
+ 人工纠错5%数据1.1045*P




















暂无评论内容