
随着科技的发展,人们和科技依赖关系的突破性进展,AI,元宇宙等概念的落地和发展,促使NLP不断发展。本文从NLP的发展历史开始阐述,系统的了介绍了各个时期的NLP模型。最后最2022年NLP模型发展方向做出了预测。

1.什么是NLP?
英文全称: Natural Language Processing;
中文全称:自然语言处理。随着计算机在人类社会中的地位越来越重要,计算机理解文本和语言就变成了技术发展的重中之重。自然语言处理是计算机科学和计算语言学中的一个领域,用于研究人类(自然)语言和计算机之间的相互作用。
1.1 NLP发展史
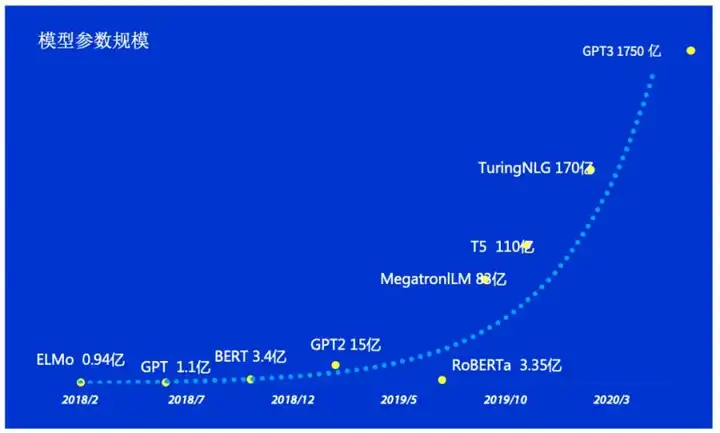
1947年,美国科学家韦弗(W. Weaver)博士和英国工程师布斯(A. D. Booth)提出了利用计算机进行语言自动翻译的设想,机器翻译从此步入历史舞台。1957 年,麻省理工学院的语言学教授诺姆·乔姆斯基提出 “要使计算机理解语言,就必须更改句子的结构。”1958 年,省理工学院的人工智能研究先驱约翰·麦卡锡(John McCarthy)研究符号运算及应用需求。麦卡锡带领由 MIT 学生组成的团队开发了一门全新的表处理语言 LISP,赋予了编程语言更强的数学计算能力。1964 年,麻省理工学院人工智能实验室的德裔计算机科学家约瑟夫·维岑鲍姆编写了自然语言对话程序 ELIZA。1981 年,伟博斯提出了一种前馈神经网络模型 MLP 。1986 年,罗斯·昆兰(Ross Quinlan)提出了 ML 算法(决策树)。1997年,LSTM 递归神经网络(RNN)模型被引入。2001年,法国 AI 专家约书亚·本吉奥(Yoshio Bengio)提出了全新的语言神经网络模型——模型使用前馈神经网络描述了一种不使用连接来形成循环的人工神经网络。2011年,美国苹果公司SIRI第一次在普通消费者中使用NLP。2014年,尤金·古斯特曼(Eugene Goostman)开发的结合NLP的聊天程序,成为有史以来首台通过图灵测试的计算机。2018年,OpenAI提出的GPT 模型可以 迁移到NLP中。2019年, GPT-2 拥有 15 亿参数。2020年,GPT-3 已经拥有惊人的 1750 亿参数。未来,GPT-N可能会有更多的突破。
1.2 NLP的主要研究方向
内容分类:语言文档摘要,包括内容警报,重复检测,搜索和索引。主题发现和建模:捕获文本集合的主题和含义,并对文本进行高级分析。上下文提取:自动从基于文本的源中提取结构化数据。情绪分析:识别存储在大量文本中的总体情绪或主观意见,用于意见挖掘。文本到语音和语音到文本的转换:将语音命令转换为文本,反之亦然。文档摘要:自动创建摘要,压缩大量文本。机器翻译:自动将一种语言的文本或语音翻译成另一种语言。2.常见的NLP模型简述

2.1 word2vec
word2vec分为CBOW和Skip-Gram两种模型。
CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,输出就是这特定的一个词的词向量。Skip-Gram模型和CBOW的输入是特定的一个词的词向量,输出是特定词对应的上下文词向量。2.2 seq2seq
Seq2Seq:Sequence-to-sequence
输入一个序列,输出另一个序列,这种模型输入序列和输出序列的长度是可变的。
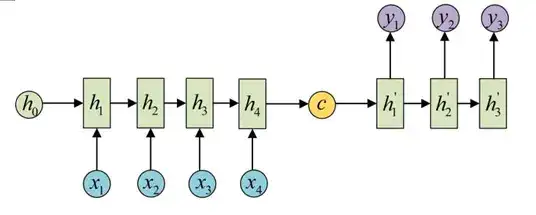
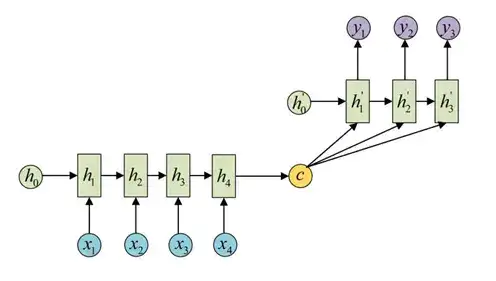
2.3 Attention model
Attention model是Decoder 的输出会与Encoder每一个时间点的输出进行分数计算。实现方法多种多样,Attention model提升了LSLTM,GRU的整体性能。
2.4 Transformer(vanilla)
transformer的结构由encoder编码和decoder解码组成。
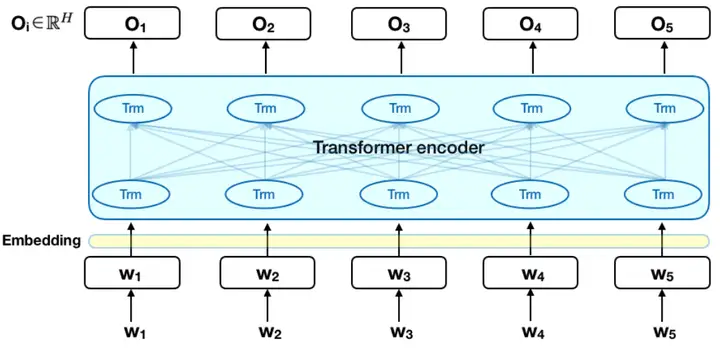
如图是Transformer 的 encoder 部分,输入是一个 token 序列,先对其进行 embedding 称为向量,然后输入给神经网络,输出是大小为 H 的向量序列,每个向量对应着具有相同索引的 token。
2.5 ELMO
ELMO是两个双层向LSTM模型,结合上下文来理解词义。
2.6 GPT
GPT是结合pre-training和fine-tuning的通用学习方式,转移到多态NLP任务中,只需要微调。
2.7 Transformer(universal)
Transformer(universal)是ACT模型动态调整symbol计算次数,可以获得最优的向量表达。它可以让机器翻译更准确,在NLP任务中通用性很强。
2.8 BERT

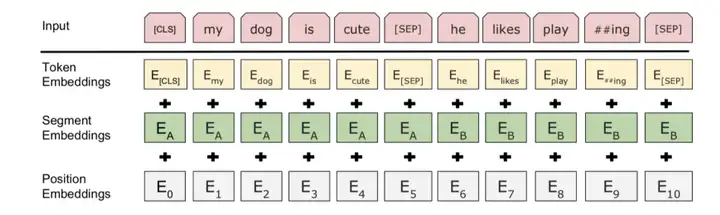
BERT是一种多层双向Transformer编码器,其中的Transformer与原始的Transformer是相同的。
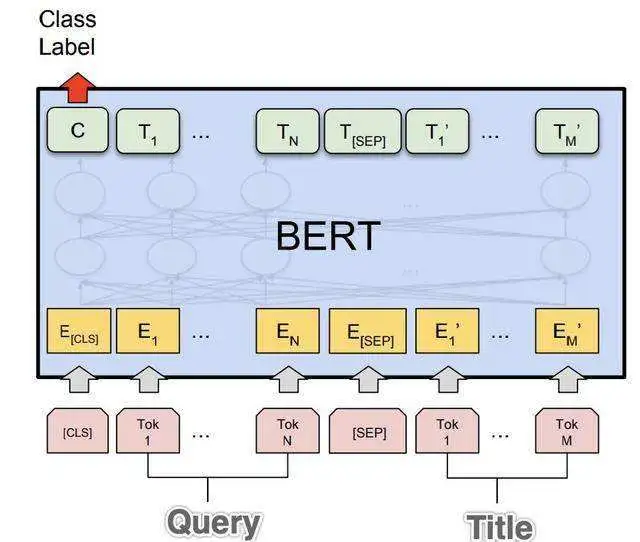
2.9 GPT2
GPT2模型可以在零样本下获取SOFA,经过训练后,它的高容量模型能够尽可能的提高语料库的多样性,无需监督学习。
2.10 Transformer-XL
Transformer-XL是分段方式建模,递归机制。使用相对位置编码重新实现positon embedding。长文档使用此模型的建模能力提升明显。
2.11 MASS
MASS:Masked Sequence to Sequence Pre-training for Language Generation
MASS的模型框架: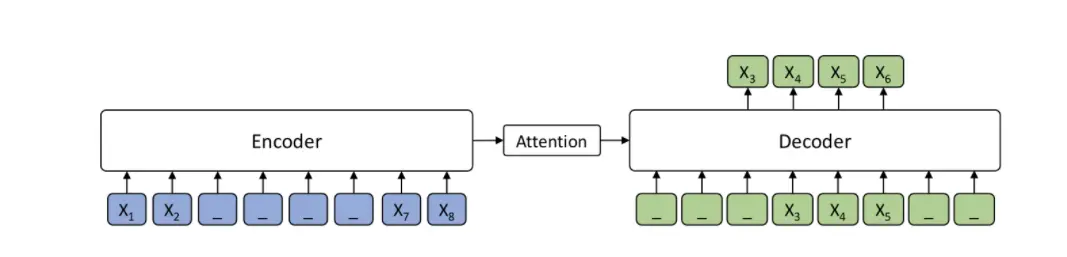
MASS的优点:
GPT和BERT可以提供强大的pretrain的模型,这有利于下游的transfer learning的任务。Seq2Seq保证了高质量的完成语言生成任务。2. 12 XLNet
XLNet是采用回归语音模型,输入全排列引入上下文信息,使用最新的Transorner-XL模型,直接使用相对位置编码,将递归机制整合到全排列设定中。
3.2022年NLP模型发展的趋势
我们先来看下NLP的五个阶段:

3.1 GPT4到来?

从OpenAI 论文中透露出来的信息:GPT-4主要提示在AI模型上,当前的模型主要集中在文本上,GPT4模型可以将可编辑文本生成图像。通过处理文本和图像的模型就是本文视觉融合。另一个新的功能可能是人类强势介入机器学习来指导模型,去抑制不理想模型,这就是人类反馈和强化学习模型。强大任务,可能好会使GPT-4的参数成倍的增加。
3.2 非原始数据在创建新模型中发挥作用?
AI的发展速度和方向,有一个十分重要的功能AI的数据合成功能,合成数据可能是音视频、文字和图像的合成,这种的新的数据参数对NLP的用例,会造就新的NLP模型出现。
3.3 WS5阶段更多社会功能模型因为体验创造新模型
现在科技社会 中出现了很多新的概念,智慧医疗、智慧交通、智慧城市、智慧农业、智能家居,这些还在发展还远远没有达到顶峰的领域,都是为了人类社会更好的体验,对应硬件设备终端、互联网终端的几何倍增长,会使对应功能的新的NLP模型出现,这个模型可能是解决了一个设备的数据采集,会获得其他设备的相互学习,相互响应。

总结
不同的阶段,不同的模型为之服务。我们现在所看到的各种模型,很多都是模型组合,模型微调生成新的模型,多模态NLP的标准数据集可大规模视觉+文本、甚至视觉+文本+语音Transformer模型的训练。
经过近几年的发展趋势来看,NLP的模型在2022年会有突破性创新模型的出现吗?总体上依然是现有多模型叠加和对现有模型的管理,优化。
随着科技的发展,人们和科技依赖关系的突破性进展,AI,元宇宙等概念的落地和发展,促使NLP模型不局限与BERT的优化,GPTn的的进化实现,期待这一天的到来。
本文分享自华为云社区《【云驻共创】2022 年 NLP 模型发展趋势是什么样的?》,作者:心跳包 。



















暂无评论内容