
原标题:学界 | 最大规模数据集、最优图像识别准确率!Facebook利用hashtag解决训练数据难题
选自code.Facebook
作者:Dhruv Mahajana、Ross Girshick、Vignesh Ramanathan、Manohar Paluri、Laurens van der Maaten
机器之心编译
参与:路、张倩
人工标注数据需要耗费大量人力成本和时间,对模型训练数据集的规模扩大带来限制。Facebook 在图像识别方面的最新研究利用带有 hashtag 的大规模公共图像数据集解决了该问题,其最佳模型的性能超越了之前最优的模型。
图像识别是 AI 研究的重要分支之一,也是 Facebook 的研究重心。Facebook 的研究人员和工程师旨在扩展计算机视觉的边界,造福现实世界。例如,使用 AI 生成图像的音频字幕帮助视觉受损的用户。为了改善这些计算机视觉系统,训练它们识别和分类大量对象,Facebook 需要包含数十亿张图像的数据集,如今常见的数百万张图像的数据集已经不足够了。
由于当前模型通常在人类标注者手动标注的数据上进行训练,因此提升识别准确率不只是向系统输入更多图像那么简单。这种劳动密集型的监督学习过程通常获得最好的性能,但是手动标注的数据集在规模方面已经接近其函数极限。Facebook 正在多达五千万张图像的数据集上训练模型,即使是在提供所有监督的情况下,数十亿张图像的训练也是不可行的。
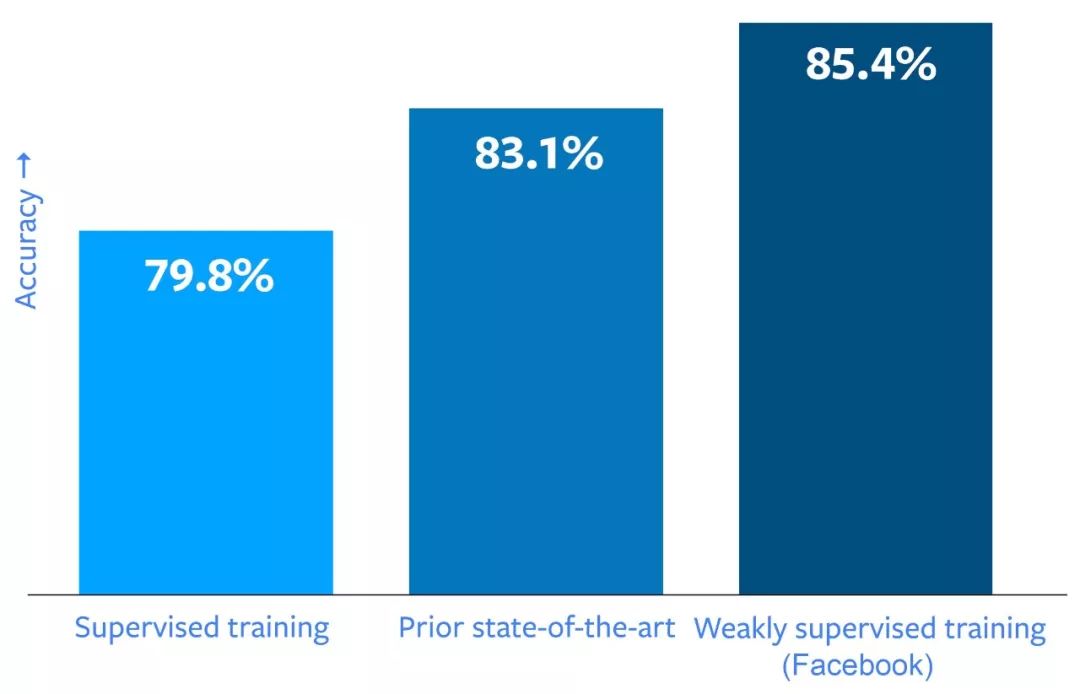
Facebook 研究人员和工程师通过在带有标签(hashtag)的公共图像数据集上训练图像识别网络解决了该问题,其中最大的数据集包含 35 亿张图像和 17000 个 hashtag。该方法的关键是使用现有公开的、用户提供的 hashtag 作为标注,取代手动标注。该方法在测试过程中表现良好。通过使用包含 10 亿图像的此类数据集训练计算机视觉系统,Facebook 得到了一个历史最高得分——在 ImageNet 上达到了 85.4% 的准确率。伴随着这一图像识别任务中的突破,该研究为如何从监督训练转向弱监督训练提供了重要洞见。在弱监督训练中,研究者使用现有标注(在本文中指 hashtag)而不是专为 AI 训练而选择的标注。Facebook 计划开源这些模型的嵌入,这样研究社区就可以使用这些表征,基于它们完成更高级别的任务。
大规模使用 hashtag
由于人们通常使用 hashtag 描述照片,所以 Facebook 研究人员认为它们可以作为模型训练数据的完美来源。这允许研究人员使用 hashtag 来完成一直以来的目标:基于人们自己标注的 hashtag 获取更多图像。
但是 hashtag 通常指非视觉概念,如 #tbt 表示「throwback Thursday」。或者它们比较模糊,如 #party 可以描述活动、设置,或者 both。对于图像识别来说,tag 的作用是弱监督数据,而模糊和/或不相关的 hashtag 是标签噪声,可能会混淆深度学习模型。
这些噪声标签是大规模训练工作的重点,因此研究人员开发了一种新方法,专为使用 hashtag 监督执行图像识别实验而准备。该方法包括处理每个图像的多个标签(加 hashtag 的用户通常会添加多个 hashtag)、整理 hashtag 同义词、平衡经常出现的 hashtag 和出现频率较低的 hashtag 的影响力。为了使这些标签有助于图像识别训练,Facebook 研究团队训练了一个大规模 hashtag 预测模型。该方法显示出优秀的迁移学习结果,表明该模型的图像分类结果可广泛应用于其他 AI 系统。这一新研究基于 Facebook 之前的研究,包括基于用户评论、hashtag 和视频的图像分类研究。这一对弱监督学习的全新探索是一次广泛的合作,Facebook 应用机器学习团队(AML)和 Facebook 人工智能研究院(FAIR)均参与其中。
在规模和性能方面开辟新天地
由于单个机器完成模型训练需要一年多时间,因此 Facebook 在多达 336 个 GPU 上进行分布式训练,将总训练时间缩短至几周。在如此大的模型规模面前(该研究中最大的模型是具备超过 86.1 千万个参数的 ResNeXt 101-32x48d),使用分布式训练方法尤其重要。此外,Facebook 设计了一种方法来移除重复项,确保不会在评估数据上进行训练,这个问题在此类研究中经常出现。
Facebook 希望能看到图像识别方面的性能提升,不过对实验结果仍然感到惊讶。在 ImageNet 图像识别基准上,其最佳模型达到了 85.4% 的准确率,该模型在 10 亿张图像上进行训练,训练数据一共包括 1500 个 hashtag。这是截至目前最高的 ImageNet 基准准确率,比之前最优模型高 2%。研究者将卷积神经网络架构的影响力进行分解,观测到的性能提升更加显著:将数十亿图像(以及大量 hashtag)用于深度学习导致高达 22.5% 的性能提升。
在另一个主要基准 COCO 上,研究者发现使用 hashtag 进行预训练可以将模型的平均准确率提高 2% 以上。
这些是图像识别和目标检测领域的基础改进,表示计算机视觉又前进了一步。但是研究者的实验还揭示了大规模训练和噪声标签的优势和面临的挑战。
例如,尽管扩大训练数据集规模是值得的,但选择匹配特定图像识别任务的 hashtag 集也具备同等的重要性。研究者通过在 10 亿张图像、1500 个匹配 ImageNet 数据集类别的 hashtag 上的训练结果优于在同样大小的数据集、但使用全部 17000 个 hashtag 的训练结果。另一方面,对于类别较多的任务,使用 17000 个 hashtag 进行训练的模型性能更好,这表明研究者应该在未来训练中增加 hashtag 的数量。
增加训练数据规模通常有利于图像识别。但是它也会产生新的问题,包括定位图像中对象位置的能力下降。Facebook 研究者还发现其最大的模型仍未充分利用 35 亿张图像数据集的优势,这表明研究者应该在更大的模型上进行训练。
大规模自标注数据集是图像识别的未来
这项研究的一个重要成果(甚至超越了图像识别的广泛成果)就是证实了在 hashtag 上训练计算机视觉模型是完全可行的。虽然使用了一些基础技术来合并相似标签、降低其他标签的权重,但是该方法不需要复杂的「清理」过程来消除标签噪声。相反,研究者能够使用 hashtag 训练模型,而且只需对训练过程做出很少的修改。规模似乎是一大优势,因为在数十亿张图像上训练的网络对标签噪声具备更好的稳健性。
我们设想了在不远的未来,hashtag 作为计算机视觉标签的其他使用方向,可能包括使用 AI 更好地理解视频片段,或改变图像在 Facebook feed 流中的排序方式。Hashtag 还可以帮助系统识别图像何时不仅属于总类别,还属于更具体的子类别。例如,照片的音频说明提及「树上的一只鸟」是有用信息,但是如果音频说明可以具体到物种(如:糖槭树上的一只主红雀),就可以为视觉受损的用户提供更好的描述。

Hashtag 可以帮助计算机视觉系统超越一般分类条目,以识别图像中的特定子类别和其他元素。
除了 hashtag 的具体用途之外,该研究还指出了可能影响新产品和现有产品的广泛图像识别方面取得的进展。例如,更精确的模型可能会改善在 Facebook 上重现记忆的方式。该研究指出了使用弱监督数据的长期影响。随着训练数据集变得越来越大,对弱监督学习的需求——以及从长远来看,对无监督学习的需求——将变得越来越显著。了解如何弥补噪声大、标注不准确的缺陷对于构建和使用大规模训练集至关重要。
本研究在 Dhruv Mahajan、Ross Girshick、Vignesh Ramanathan、Kaiming He、Manohar Paluri、Yixuan Li、Ashwin Bharambe 和 Laurens van der Maaten 的《Exploring the Limits of Weakly Supervised Pretraining》一文中有更详细的描述。由于该研究涉及到的规模史无前例,此论文详细的论述将为一系列新研究方向铺平道路,包括开发新一代足够复杂的深度学习模型,从而有效地从数十亿张图像中学习。
该研究还表明,为了更好地衡量当今图像识别系统以及未来规模更大、监督更少的图像识别系统的质量和局限性,开发类似 ImageNet 的广泛使用的新型基准很有必要。
论文:Exploring the Limits of Weakly Supervised Pretraining

论文链接:https://research.fb.com/publications/exploring-the-limits-of-weakly-supervised-pretraining/
摘要:当前最优的适合大量任务的视觉感知模型依赖于监督式预训练。ImageNet 分类实际上是这些模型的预训练任务。但是,目前 ImageNet 将近十岁,用现代标准来看规模有些小了。即便如此,使用规模大了好几个数量级的数据集进行预训练也很少见。原因很明显:此类数据集很难收集和标注。本论文展示了一种独特的迁移学习研究,在数十亿社交媒体图像上训练大型卷积网络来预测 hashtag。实验表明大规模 hashtag 预测的训练性能很好。我们展示了在多个图像分类和目标检测任务上的改进,并报告了目前最高的 ImageNet-1k single-crop,top-1 准确率 85.4%(top-5 准确率 97.6%)。我们还进行了大量实验,为大规模预训练和迁移学习性能之间的关系提供了新的实证数据。
原文链接:https://code.facebook.com/posts/1700437286678763/
本文为机器之心编译,转载请联系本公众号获得授权。
✄————————————————
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



















暂无评论内容