
随着最新的 Pythorc1.3 版本的发布,下一代完全重写了它以前的目标检测框架,新的目标检测框架被称为 Detectron2。本教程将通过使用自定义 coco 数据集训练实例分割模型,帮助你开始使用此框架。如果你不知道如何创建 coco 数据集,请阅读我之前的文章——如何创建自定义 coco 数据集用于实例分割。
为了快速开始,我们将在 Colab Notebook 上进行实验,这样你就不必担心在使用 pytorch 1.3 和 detectron2 之前在自己的机器上设置开发环境的问题了。
安装 Detectron2
在 Colab Notebook 中,只需运行这 4 行代码即可安装最新的 pytorch 1.3 和 detectron2。
!pip install -U torch torchvision
!pip install git+https://github.com/facebookresearch/fvcore.git
!git clone https://github.com/facebookresearch/detectron2 detectron2_repo
!pip install -e detectron2_repo
单击输出单元格中的「RESTART RUNTIME」以使安装生效。

注册一个 coco 数据集
为了告诉 Detectron2 如何获取数据集,我们将「注册」它。
为了演示这个过程,我们使用了水果坚果分割数据集,它只有 3 个类:数据、图和榛子。我们将从现有的 coco 数据集训练模型中分离出一个分割模型,该模型可在 DeCtTrON2 model zoo 中使用。
你可以这样下载数据集。
# download, decompress the data
!wget https://github.com/Tony607/detectron2_instance_segmentation_demo/releases/download/V0.1/data
!unzip data.zip > /dev/null
或者你也可以从这里上传你自己的数据集。

按照 Detectron2 自定义数据集教程,将水果坚果数据集注册到 Detectron2。
from detectron2.data.datasets import
register_coco_instances register_coco_instances(“fruits_nuts”, {}, “./data/trainval.json”, “./data/images”)
每个数据集都与一些元数据相关联。在我们的例子中,可以通过调用fruits_nuts_metadata=metadatacatalog.get(“fruits_nuts”)来访问它。
Metadata(evaluator_type=coco, image_root=./data/images,
json_file=./data/trainval.json, name=fruits_nuts, thing_classes=[date, fig, hazelnut], thing_dataset_id_to_contiguous_id={1: 0, 2: 1, 3: 2})
要获取目录的实际内部表示形式,可以调用 dataset_dicts=dataset catalog.get(”fruits_nuts”)。内部格式使用一个 dict 来表示一个图像的注释。
为了验证数据加载是否正确,让我们可视化数据集中随机选择的样本的注释:
import random
from detectron2.utils.visualizer import Visualizer
for d in random.sample(dataset_dicts, 3):
img = cv2.imread(d[“file_name”])
visualizer = Visualizer(img[:, :, ::-1], metadata=fruits_nuts_metadata, scale=0.5)
vis = visualizer.draw_dataset_dict(d)
cv2_imshow(vis.get_image()[:, :, ::-1])
其中一张图像可能是这样子的:

模型训练
现在,让我们微调水果坚果数据集上的 coco 预训练 R50-FPN Mask R-CNN 模型。在 colab 的 k80 gpu 上训练 300 次迭代需要大约 6 分钟。
from detectron2.engine import DefaultTrainer
from detectron2.config import get_cfg
import os
cfg = get_cfg()
cfg.merge_from_file(
“./detectron2_repo/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3 x.yaml” )
cfg.DATASETS.TRAIN = (“fruits_nuts”,)
cfg.DATASETS.TEST = () # no metrics implemented for this dataset cfg.DATALOADER.NUM_WORKERS = 2
cfg.MODEL.WEIGHTS = “detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/mode
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.02
cfg.SOLVER.MAX_ITER = ( 300 ) # 300 iterations seems good enough, but you can certainly train longer
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = ( 128 ) # faster, and good enough for this toy dataset
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 3 # 3 classes (data, fig, hazelnut)
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()
如果切换到自己的数据集,请相应地更改类数、学习速率或最大迭代次数。

作出预测
现在,我们用训练好的模型在水果坚果数据集上进行推理。首先,让我们使用我们刚刚训练的模型创建一个预测:
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, “model_final.pth”)
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 # set the testing threshold for this model
cfg.DATASETS.TEST = (“fruits_nuts”, )
predictor = DefaultPredictor(cfg)
然后,随机选取多个样本对预测结果进行可视化处理。
from detectron2.utils.visualizer import ColorMode
for d in random.sample(dataset_dicts, 3):
im = cv2.imread(d[“file_name”])
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1], metadata=fruits_nuts_metadata, scale=0.8, instance_mode=ColorMode.IMAGE_BW # remove the colors of unsegmented pixels )
v = v.draw_instance_predictions(outputs[“instances”].to(“cpu”))
cv2_imshow(v.get_image()[:, :, ::-1])
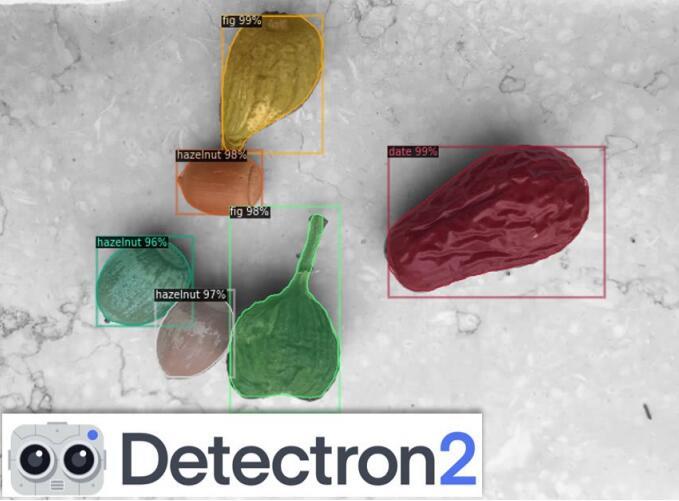
这是一个覆盖了预测的样本图像所得到的结果。

总结与思考
你可能已经阅读了我以前的教程,其中介绍了一个类似的对象检测框架,名为 MMdetection,它也构建在 pytorch 上。那么 Detectron2 和它相比如何呢?以下是我的一些想法。
两个框架都很容易用一个描述模型训练方法的配置文件进行配置。Detectron2 的 yaml 配置文件效率更高,有两个原因。首先,可以通过先进行「基本」配置来重用配置,并在此基本配置文件上构建最终的训练配置文件,从而减少重复代码。第二,可以先配置配置文件,并允许在 Python 代码中进行必要的进一步修改,从而使其更加灵活。
那么推理速度如何?简单地说,Detectron2 比相同 Mask RCNN Resnet50 FPN 模型的 MMdetection 稍快。MMdetection 的 FPS 是 2.45,而 Detectron2 达到 2.59 FPS,在推断单个图像时提高了 5.7% 的速度。我们基于以下代码做了基准测试。
import time
times = []
for i in range(20):
start_time = time.time()
outputs = predictor(im)
delta = time.time() – start_time
times.append(delta)
mean_delta = np.array(times).mean()
fps = 1 / mean_delta
print(“Average(sec):{:.2f},fps:{:.2f}”.format(mean_delta, fps))
所以,你现在学会啦,Detectron2 让你用自定义数据集训练自定义实例分割模型变得非常简单。你可能会发现以下资源很有帮助:
我之前的文章——How to create custom COCO data set for instance segmentation。
我之前的文章——How to train an object detection model with mmdetection。
Detectron2 GitHub repo。
这篇文章的可运行的 Colab Notebook 。
via:https://medium.com/@chengweizhang2012/how-to-train-detectron2-with-custom-coco-datasets-4d5170c9f389



















暂无评论内容